通常来说,大家认为深度学习的观点是Geoffrey Hinton在2006年提出的。这一算法提出之后,得到了迅速的发展。关于深度学习,zouxy09的专栏中有详细的介绍,Free Mind 的博文也很值得一读。本博文是我对深度学习的一点看法,主要内容在第4、5部分,不当之处还请指教。
深度学习,即Deep Learning,是一种学习算法(Learning algorithm)。学习算法这个很好理解,那么Deep指的是什么呢?这里的Deep是针对算法的结构而言的。
譬如,SVMs及Logistic Regression被称为浅层学习,是因为其隐藏节点只有一层。也就是说,这些算法只通过了一层“思考”就得到了答案,所以它们是浅显的。然而,深度学习的结构中有多个隐藏层,所以起了一个名字叫做Deep。博文Deep learning:十六(deep networks)中对这种结构的优缺点做了说明。
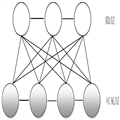
深度学习是基于Deep Belief Nets提出的算法。Hinton的论文中,是从受限波尔兹曼机(RBMs)中引出的Deep Belief Nets。波尔兹曼机的结构图如下(来自百度图片,这个图实际上不对,隐层节点和可见层节点两两之间都有连线)。

受限波尔兹曼机去掉了同层之间节点的连线,结构图如下(来自受限波尔兹曼机)。
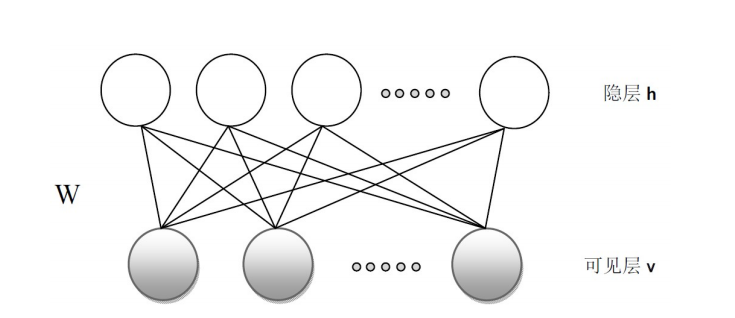
波尔兹曼机的相关知识具体可以参考Simon Haykin的《神经网络原理》第三版。受限波尔兹曼机有很多好的博文,譬如受限波尔兹曼机。波尔兹曼机的学习规则是使得学习之后的似然函数取值最大,然而作为无监督学习,似然函数从何而来?
Hinton原来是学物理的,《神经网络原理》中把波尔兹曼机分在了植根于统计力学的随机机器这一章中。波尔兹曼机中定义了一个系统能量,并基于此定义了各个状态的概率。这些都是基于统计热力学得出的。在这一基础上,可以写出似然函数,之后利用梯度方法对网络进行迭代。
受限波尔兹曼机的叠加得到了深度信度网络(deep belief nets),可参考深度学习概述:从感知机到深度网络或Hinton的《A Fast Learning Algorithm for Deep Belief Nets》

深度信度网络的训练方法被称为是一种 fast, greedy algorithm。就如上图(来自受限波尔兹曼机)所表示,首先,我们认为x和h1组成RBM,对其进行训练;之后,固定此处的w,训练h1和h2,并以此类推。
UFLDL教程中是利用稀疏自编码其来导出的深度信度网络,以及深度学习算法的。个人觉得这比玻尔兹曼机好理解多了。稀疏自编码器如下所示(来自UFLDL教程),它的理论建立在多层感知器的反向传播(back propagate)算法上。

和2中类似,深度网络可以表示为如下形式(来自受限波尔兹曼机)。同样可以采用逐层训练的方法。

记得之前看过一本叫做《数学基础》的书,其中有一段印象深刻。“为何在集论可推出的无数种结构中,只有少数几种得到了重要的地位?为何有些概念更加有趣?形形色色的数学理论盛衰由人类的实践决定。”那么,我们是否可以认为,数学从一无所有开始,通过限定公理,建立起一套合适的数学理论来拟合我们看到的世界?而深度学习拟合的又是什么?为何深度学习能够在包括计算机视觉在内的众多领域取得成功?深度学习——机器学习——人工智能,拟合的是我们看到的世界。
稀疏自编码器的解释
根据信息不增定理,在网络传播过程中熵减少。而稀疏编码器中的隐藏元个数小于输入维度。因此,隐藏元是一个自编码的过程,在这个过程中尽可能的保留输入的信息。在深度网络中,每一层的训练亦是如此。
研究表明,人脑的神经元连接也是多层的。由此发展出的神经网络(多层感知器)和由稀疏自编码器构成的深度网络具有相同的结构。一个不恰当的表示是,网络的训练过程是使得每一层保留的熵最大,这样整个网络的输出才有可能有尽可能大的熵(在限定的网络结构下)。那么,为何这一条规则可以在网络训练中取得成功?
因为熵是人定义出来的,并不是真实存在,却帮助人更好的去理解这个世界。由稀疏自编码器导出的深度学习网络利用这一条规则对人脑进行了成功的模拟。如果这一条规则(即人脑的对信息的处理不满足保留熵最大)不成立,那么就不符合人对世界的认知,在人类发展过程中,熵的定义就会被淘汰。所以这一条规则是成立的,这样训练出来的网络,和人的大脑有共同之处。
波尔兹曼机的解释
对于波尔兹曼机及其背后的物理思想,自己还没有搞明白。然而,物理是一门对自然万物运行的机理进行解释的科学,统计热力学也不例外。人自身即置于这个世界之内,建立的理论大概也是殊途同归吧。对于这一点,由于自己学识所限,不敢妄加揣测。
看过《老子》之后后,大抵都会纠结于一个问题——什么是道?我个人倾向于把“道”理解为天地,或是天地之间的规则,而这个规则不是永恒不变的。“道”可以视作为一种机制,形形色色的生物是其运行的不同结果。那么,回到4中那句“形形色色的数学理论盛衰由人类的实践决定”,数学理论的盛衰真的是人类的实践决定的吗?只有在人意识到某一种理论的不足的时候,才会有新的理论的发展,有了发展和变化,才会有盛衰。人认识世界,世界改变人的认识,数学理论的盛衰由“道”决定。
回归正题。
1.对于SVMs等浅层学习,什么是道?
2.深度学习的道?
3.道法自然、修道
很多浅层学习算法可以看作是从被标记的数据之间寻找规律的过程,对于网络结构本身而言,它的“道”是一组组人为建立的被标记的数据。我们试图去建立一个属于它们的世界,让它们在我们建立的世界中学习。然而,这个过程是困难的,不谈浅层网络的结构对其表示的影响,和真实的世界相比,我们建立的用来训练浅层网络的世界太简单,对真实世界的表示有太大的局限性。

深度学习的过程是不一样的。认识到建立一个世界的困难之后,试图利用世界本身去训练网络。然而这个过程是没有有反馈的(即无监督学习),我们把人本身作为桥梁,利用我们抽象出的规则,和合适的结构(多层感知器)去构造一个能够表达真实世界规律的人工网络。

对于Deep belief Nets,我们做的还是太多了,太“有为”了。无论从结构上,还是其规则的限定上(我们把网络的训练问题过多的限制成优化问题了)。修道,一般指突破天地限制,大彻大悟的过程。如果有一天,算法能够突破人为的限定,和人所在的世界交互,那算是修道成功了吧!
这段时间烦心事很多,博客本来都不想写了,后来想想,还是应该坚持下去。这篇博文主要是想把我现在的看法表达出来,行文有点惨不忍睹,观点也有很多错误,还请大家见谅。