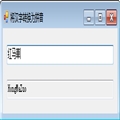
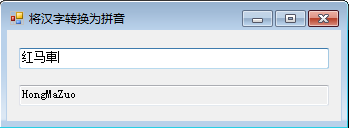
一:上图,不清楚的看代码注解,很详细了
二:具体代码
窗体代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Text.RegularExpressions;
namespace ChineseToABC
{
public partial class Frm_Main : Form
{
public Frm_Main()
{
InitializeComponent();
}
private void txt_Chinese_TextChanged(object sender, EventArgs e)
{
txt_PinYIn.Text = //调用拼音类的GetABC方法得到拼音字符串
new PinYin().GetABC(txt_Chinese.Text);
}
}
}
拼音类代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Windows.Forms;
public class PinYin
{
//定义拼音区编码数组
private static int[] getValue = new int[]
{
-20319,-20317,-20304,-20295,-20292,-20283,-20265,-20257,-20242,-20230,-20051,-20036,
-20032,-20026,-20002,-19990,-19986,-19982,-19976,-19805,-19784,-19775,-19774,-19763,
-19756,-19751,-19746,-19741,-19739,-19728,-19725,-19715,-19540,-19531,-19525,-19515,
-19500,-19484,-19479,-19467,-19289,-19288,-19281,-19275,-19270,-19263,-19261,-19249,
-19243,-19242,-19238,-19235,-19227,-19224,-19218,-19212,-19038,-19023,-19018,-19006,
-19003,-18996,-18977,-18961,-18952,-18783,-18774,-18773,-18763,-18756,-18741,-18735,
-18731,-18722,-18710,-18697,-18696,-18526,-18518,-18501,-18490,-18478,-18463,-18448,
-18447,-18446,-18239,-18237,-18231,-18220,-18211,-18201,-18184,-18183, -18181,-18012,
-17997,-17988,-17970,-17964,-17961,-17950,-17947,-17931,-17928,-17922,-17759,-17752,
-17733,-17730,-17721,-17703,-17701,-17697,-17692,-17683,-17676,-17496,-17487,-17482,
-17468,-17454,-17433,-17427,-17417,-17202,-17185,-16983,-16970,-16942,-16915,-16733,
-16708,-16706,-16689,-16664,-16657,-16647,-16474,-16470,-16465,-16459,-16452,-16448,
-16433,-16429,-16427,-16423,-16419,-16412,-16407,-16403,-16401,-16393,-16220,-16216,
-16212,-16205,-16202,-16187,-16180,-16171,-16169,-16158,-16155,-15959,-15958,-15944,
-15933,-15920,-15915,-15903,-15889,-15878,-15707,-15701,-15681,-15667,-15661,-15659,
-15652,-15640,-15631,-15625,-15454,-15448,-15436,-15435,-15419,-15416,-15408,-15394,
-15385,-15377,-15375,-15369,-15363,-15362,-15183,-15180,-15165,-15158,-15153,-15150,
-15149,-15144,-15143,-15141,-15140,-15139,-15128,-15121,-15119,-15117,-15110,-15109,
-14941,-14937,-14933,-14930,-14929,-14928,-14926,-14922,-14921,-14914,-14908,-14902,
-14894,-14889,-14882,-14873,-14871,-14857,-14678,-14674,-14670,-14668,-14663,-14654,
-14645,-14630,-14594,-14429,-14407,-14399,-14384,-14379,-14368,-14355,-14353,-14345,
-14170,-14159,-14151,-14149,-14145,-14140,-14137,-14135,-14125,-14123,-14122,-14112,
-14109,-14099,-14097,-14094,-14092,-14090,-14087,-14083,-13917,-13914,-13910,-13907,
-13906,-13905,-13896,-13894,-13878,-13870,-13859,-13847,-13831,-13658,-13611,-13601,
-13406,-13404,-13400,-13398,-13395,-13391,-13387,-13383,-13367,-13359,-13356,-13343,
-13340,-13329,-13326,-13318,-13147,-13138,-13120,-13107,-13096,-13095,-13091,-13076,
-13068,-13063,-13060,-12888,-12875,-12871,-12860,-12858,-12852,-12849,-12838,-12831,
-12829,-12812,-12802,-12607,-12597,-12594,-12585,-12556,-12359,-12346,-12320,-12300,
-12120,-12099,-12089,-12074,-12067,-12058,-12039,-11867,-11861,-11847,-11831,-11798,
-11781,-11604,-11589,-11536,-11358,-11340,-11339,-11324,-11303,-11097,-11077,-11067,
-11055,-11052,-11045,-11041,-11038,-11024,-11020,-11019,-11018,-11014,-10838,-10832,
-10815,-10800,-10790,-10780,-10764,-10587,-10544,-10533,-10519,-10331,-10329,-10328,
-10322,-10315,-10309,-10307,-10296,-10281,-10274,-10270,-10262,-10260,-10256,-10254
};
//定义拼音数组
private static string[] getStr = new string[]
{
"A","Ai","An","Ang","Ao","Ba","Bai","Ban","Bang","Bao","Bei","Ben",
"Beng","Bi","Bian","Biao","Bie","Bin","Bing","Bo","Bu","Ba","Cai","Can",
"Cang","Cao","Ce","Ceng","Cha","Chai","Chan","Chang","Chao","Che","Chen","Cheng",
"Chi","Chong","Chou","Chu","Chuai","Chuan","Chuang","Chui","Chun","Chuo","Ci","Cong",
"Cou","Cu","Cuan","Cui","Cun","Cuo","Da","Dai","Dan","Dang","Dao","De",
"Deng","Di","Dian","Diao","Die","Ding","Diu","Dong","Dou","Du","Duan","Dui",
"Dun","Duo","E","En","Er","Fa","Fan","Fang","Fei","Fen","Feng","Fo",
"Fou","Fu","Ga","Gai","Gan","Gang","Gao","Ge","Gei","Gen","Geng","Gong",
"Gou","Gu","Gua","Guai","Guan","Guang","Gui","Gun","Guo","Ha","Hai","Han",
"Hang","Hao","He","Hei","Hen","Heng","Hong","Hou","Hu","Hua","Huai","Huan",
"Huang","Hui","Hun","Huo","Ji","Jia","Jian","Jiang","Jiao","Jie","Jin","Jing",
"Jiong","Jiu","Ju","Juan","Jue","Jun","Ka","Kai","Kan","Kang","Kao","Ke",
"Ken","Keng","Kong","Kou","Ku","Kua","Kuai","Kuan","Kuang","Kui","Kun","Kuo",
"La","Lai","Lan","Lang","Lao","Le","Lei","Leng","Li","Lia","Lian","Liang",
"Liao","Lie","Lin","Ling","Liu","Long","Lou","Lu","Lv","Luan","Lue","Lun",
"Luo","Ma","Mai","Man","Mang","Mao","Me","Mei","Men","Meng","Mi","Mian",
"Miao","Mie","Min","Ming","Miu","Mo","Mou","Mu","Na","Nai","Nan","Nang",
"Nao","Ne","Nei","Nen","Neng","Ni","Nian","Niang","Niao","Nie","Nin","Ning",
"Niu","Nong","Nu","Nv","Nuan","Nue","Nuo","O","Ou","Pa","Pai","Pan",
"Pang","Pao","Pei","Pen","Peng","Pi","Pian","Piao","Pie","Pin","Ping","Po",
"Pu","Qi","Qia","Qian","Qiang","Qiao","Qie","Qin","Qing","Qiong","Qiu","Qu",
"Quan","Que","Qun","Ran","Rang","Rao","Re","Ren","Reng","Ri","Rong","Rou",
"Ru","Ruan","Rui","Run","Ruo","Sa","Sai","San","Sang","Sao","Se","Sen",
"Seng","Sha","Shai","Shan","Shang","Shao","She","Shen","Sheng","Shi","Shou","Shu",
"Shua","Shuai","Shuan","Shuang","Shui","Shun","Shuo","Si","Song","Sou","Su","Suan",
"Sui","Sun","Suo","Ta","Tai","Tan","Tang","Tao","Te","Teng","Ti","Tian",
"Tiao","Tie","Ting","Tong","Tou","Tu","Tuan","Tui","Tun","Tuo","Wa","Wai",
"Wan","Wang","Wei","Wen","Weng","Wo","Wu","Xi","Xia","Xian","Xiang","Xiao",
"Xie","Xin","Xing","Xiong","Xiu","Xu","Xuan","Xue","Xun","Ya","Yan","Yang",
"Yao","Ye","Yi","Yin","Ying","Yo","Yong","You","Yu","Yuan","Yue","Yun",
"Za", "Zai","Zan","Zang","Zao","Ze","Zei","Zen","Zeng","Zha","Zhai","Zhan",
"Zhang","Zhao","Zhe","Zhen","Zheng","Zhi","Zhong","Zhou","Zhu","Zhua","Zhuai","Zhuan",
"Zhuang","Zhui","Zhun","Zhuo","Zi","Zong","Zou","Zu","Zuan","Zui","Zun","Zuo"
};
/// <summary>
/// 将汉字转换拼音的方法
/// </summary>
/// <param name="str">汉字字符串</param>
/// <returns>拼音字符串</returns>
public string GetABC(string str)
{
Regex reg = new Regex("^[\u4e00-\u9fa5]$");//实力化一个正则表达式,验证输入是否为汉字
byte[] arr = new byte[2];//定义字节数组,//每个汉字为2字节
string pystr = "";//定义字符串变量用于返回拼音
char[] mChar = str.ToCharArray();//获取汉字对应的字符数组//将此实例中的字符复制到 Unicode 字符数组。
return GetStr(mChar,pystr,reg,arr);//返回获取到的汉字拼音
}
/// <summary>
/// 拼音字符串
/// </summary>
/// <param name="mChar">汉字对应的字符数组</param>
/// <param name="pystr">用于返回拼音的字符串数组</param>
/// <param name="reg">汉字的正则表达式</param>
/// <param name="arr">定义的字节数组</param>
/// <returns></returns>
private string GetStr(char[] mChar,string pystr,Regex reg,byte[] arr)
{
int asc = 0, M1 = 0, M2 = 0;
for (int j = 0; j < mChar.Length; j++)
{
if (reg.IsMatch(mChar[j].ToString()))//如果输入的是汉字
{
//根据系统默认编码得到字节码
arr = System.Text.Encoding.Default.GetBytes(mChar[j].ToString());
M1 = (short)(arr[0]);//取字节1
M2 = (short)(arr[1]);//取字节2
//计算汉字的编码,第一个字节移8位后与第二个字节相加得到汉字编码,Unicode固定为双字节编码,共可以表示65536个字符 。
asc = M1 * 256 + M2 - 65536;
if (asc > 0 && asc < 160)
{
pystr += mChar[j];
}
else
{
switch (asc)
{
case -9254:
pystr += "Zhen"; break;
case -8985:
pystr += "Qian"; break;
case -5463:
pystr += "Jia"; break;
case -8274:
pystr += "Ge"; break;
case -5448:
pystr += "Ga"; break;
case -5447:
pystr += "La"; break;
case -4649:
pystr += "Chen"; break;
case -5436:
pystr += "Mao"; break;
case -5213:
pystr += "Mao"; break;
case -3597:
pystr += "Die"; break;
case -5659:
pystr += "Tian"; break;
default:
for (int i = (getValue.Length - 1); i >= 0; i--)
{
if (getValue[i] <= asc)//判断汉字的拼音区编码是否在指定范围内
{
pystr += getStr[i];//如果不超出范围则获取对应的拼音
break;
}
}
break;
}
}
}
else//如果不是汉字
{
pystr += mChar[j].ToString();//如果不是汉字则返回
}
}
return pystr;
}
}