openface 人脸识别框架 但个人感觉精度还是很一般
openface的githup文档地址:http://cmusatyalab.github.io/openface/
openface的安装:
官方推荐用docker来安装openface,这样方便快速不用自己去安装那么多依赖库:
docker pull bamos/openface docker run -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
也就两行代码的事情,如果自己一步步去安装的话,估计很花时间。
参考路径:http://cmusatyalab.github.io/openface/setup/
Demo简单分析:
openface的网页提供了四个demo:

第一:实时视频定位人物

具体demo位置在github clone下来的 demos/web 目录里,通过启用:
docker run -class="hljs-tag">p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash -l -c '/root/openface/demos/web/start-servers.sh'
来启动这个web服务,但是最新版的无法远程访问,原因是加了安全机制了,官方也提供了两种解决方法:
1)设置google浏览器的访问
用该命令启动谷歌浏览器 --unsafely-treat-insecure-origin-as-secure="example.com" ,还需要包含--user-data-dir = / test / only / profile / dir来为标志创建新的测试配置文件。
2)客户端安装ncat作为代理
export SERVER_IP=192.168.99.100 ncat --sh-exec "ncat $SERVER_IP 8000" -l 8000 --keep-open
& ncat --sh-exec "ncat $SERVER_IP 9000" -l 9000 --keep-open &
具体运用查看:http://cmusatyalab.github.io/openface/demo-1-web/ 和ncat的官网
这里讲都是从linux系统来说的,我没有试验成功!
=======================================================
第二:人脸比较 Comparing two images
这个需要自己去看py代码了,不难,只是需要自己根据阈值去判断是否是同一张图片:
进入容器:
docker attach 89dfcc6 cd /root/openface/ ./demos/compare.py images/examples/{lennon*,clapton*}

阈值是0.99,阈值的确定是一件技术活,当然要自己训练多,有相应的直觉
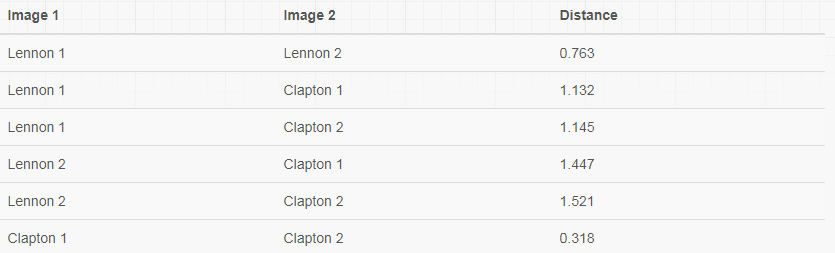
阈值在0.99以上的可以确定为同一张图片,否则不是
这里不多说,多看代码,多训练数据,多调参,你会更有直觉去做好一件事。
===========================================================================
第三:训练分类
这个训练结果有点让我失望,一方面可能是训练图片太少了,另一方面的就是图片的预处理上出现比例失调的情况影响了训练结果
1)快速安装
因为这里涉及到docker 数据卷的问题,需要挂载一个目录到本地,所以重新启动一个容器:
docker run –v /app/ml_data/:/root/openface/data/mydata/ -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
/app/ml_data 是本地数据;/root/openface/data/mydata 是容器里目录
2)准备数据

train_img 是放置训练的图片
others 是放置验证的图片
aligned_imgage 是放置经过预处理,剪裁大小的图片
generated_charaters 是放置训练后的特征数据
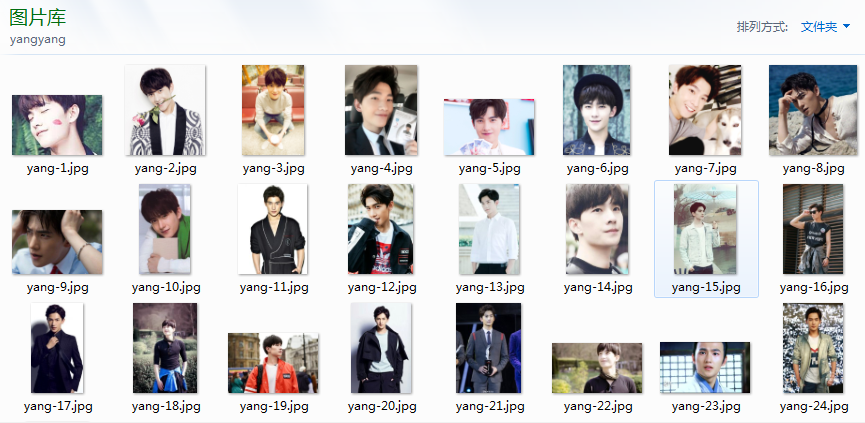
然后我们看看图片集
train_img 目录下的两个目录huge 和 yangyang 分别放如下图片

yangyang的
others图片

3)开始训练,训练集先设置huge和yangyang分别10张图片作为训练
3.1 预处理图片和分类
./util/align-dlib.py data/mydata/train_img/ align outerEyesAndNose data/mydata/aligned_images/ --size 64
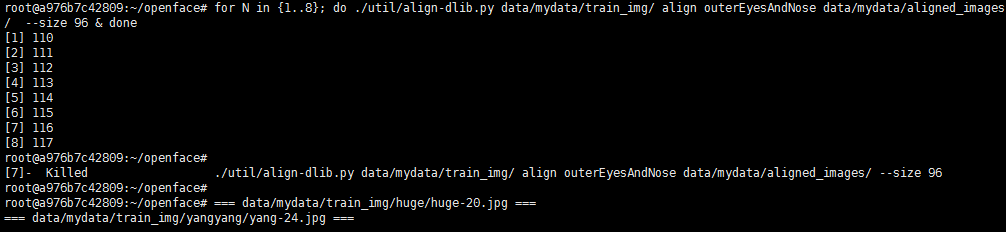
也可以启用多线程处理
for N in {1..8}; do ./util/align-dlib.py data/mydata/train_img/ align outerEyesAndNose data/mydata/aligned_images/ -size 96 & done
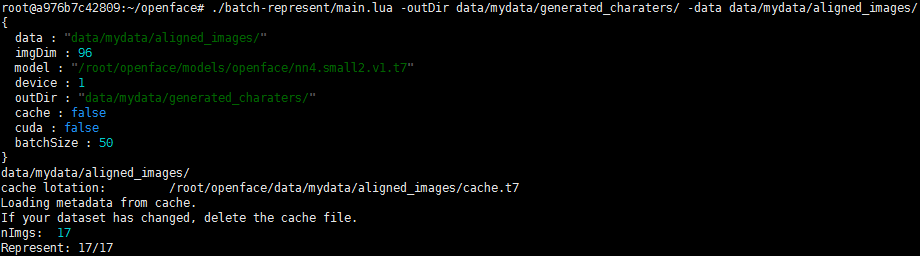
3.2 提取特征
./batch-represent/main.lua -outDir data/mydata/generated_charaters/ -data data/mydata/aligned_images/
3.3 训练图片
./demos/classifier.py train data/mydata/generated_charaters/
#将会产生data/mydata/generated_charaters/ classifier.pkl的新文件名。这个文件有你将用来识别新面部的 SVM 模型
4)验证训练结果
./demos/classifier.py infer data/mydata/generated_charaters/classifier.pkl /root/openface/data/mydata/others/{hu,other,yang}*
结果如何:

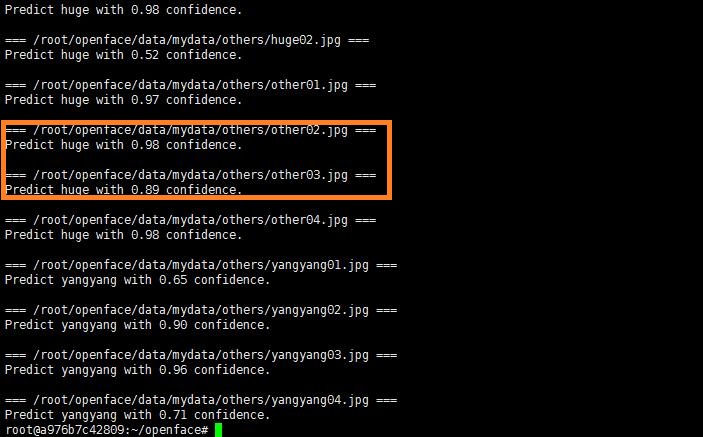
我们可以看到结果:
杨洋的预测基本比较准,可是other02.jpg 和other03.jpg预测成胡歌的概率在0.89以上,确实有问题。什么原因这样呢?
来看一下预处理的图片也及是aligned_imgage目录里的图片:
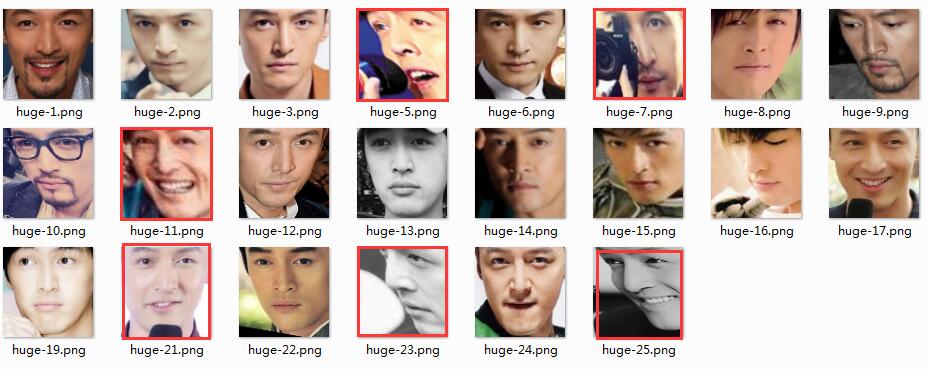
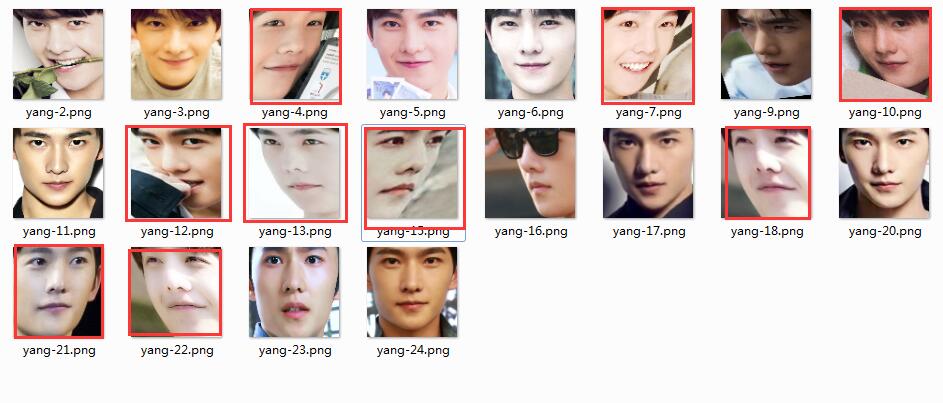
5)第二次,增加测试集到每一个人物的图片为20张,另外删除到一两张预处理变形的图片,结果如何:
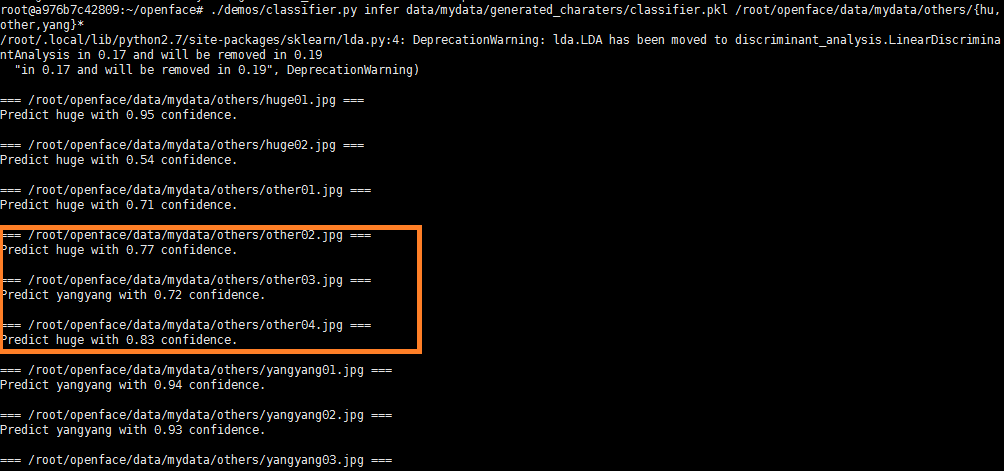
我们看到精度是有所提高的,可是远远还不足,我们试着加两张另类的照片:

就是other06.jpg和other07.jpg,来看看训练后的验证结果如何:
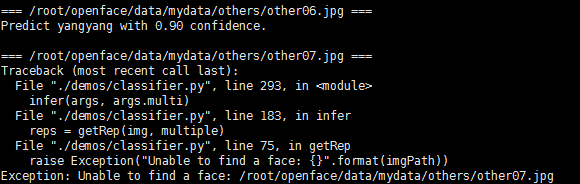
很失望的看到 :Predict yangyang with 0.90 confidence
把金三胖预测成杨洋的可靠性为百分之90-------无语了!
当然一张狗的图片是直接报错,说明找不到分类
这个要用到生成环境下的话,还得慎重看看源码,做一个优化;如果做一个门卫的监控识别,每增加一个人,就得提供8张图片作为训练尚可,如果提供20张以上图片确实要疯了;
如果是识别本人是挺好的,可是无法区分入侵者,这就是个问题了。
究其原因:openface 用的似乎还有蛮多的,可能是卷积层训练的数据是基于外国人的脸谱训练的,如果要可靠一点,应该重新找一些数据从底层开始训练起来;
如有时间,再做深入分析了。
希望以后会出现一些更好的人脸识别框架
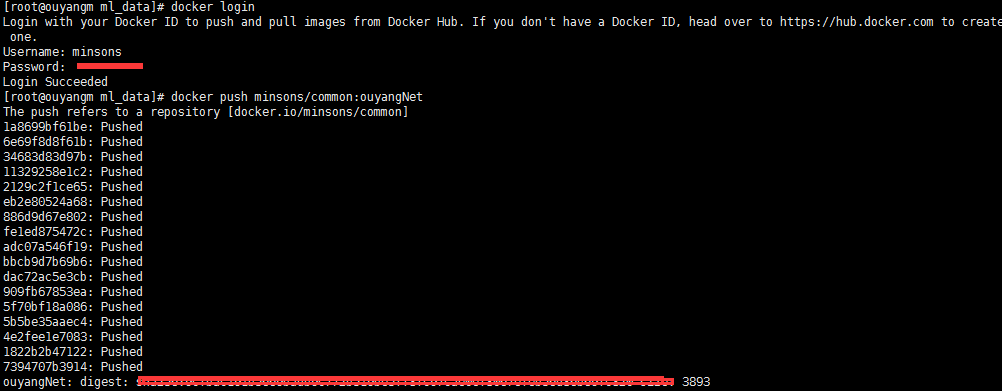
6) 最后建议你把docker容器提交一下
$ docker commit c3f279d17e0a minsons/common:ouyangNet
如果有github账户,那随便就提交上去吧
docker login #登陆
docker push minsons/common:ouyangNet
========================================================
第四 :空间定位
就是会在一定空间内区分出不同的人,从技术上来,最大的难处不是识别两个人的不同,而是空间定位。
空间定位是针对陌生人,在库里是没有经过训练的,可是一个人进入空间后被采集了图片,
那么这个人的采集数据跟本人的再次采集的图片之间的距离肯定更加趋近0,更好的识别出不同其他人,问题是如何实时空间3上上定位。
我们可能会考虑到的场景就是:阿里巴巴的无人零售店。
对于一个人在店里的定位和识别就可以根据人在进入零售店扫手机的淘宝账户的同时采集这个人的脸部数据,并实现实时的关联,接着再建立起人与空间的定位,
我个人的思路是:
1,进入关卡,建立淘宝账户与人的定位关联
2,空间定位的关联
3,实时采集人拿东西视觉识别统计(具体有种实现方式及采集媒介协助)
4,关联支付
不同的颜色来区别空间上的不同人
以下是部分官网的翻译:
在这个演示中:
我们首先使用OpenCV来获取,处理和显示摄像头的视频源。
在自己电脑上执行:
1,启动项目
2,下载3D模型,点击这里
3,执行 demos/sphere.py 用参数 --networkModel 指向3D模型
因为设备关系没能尝试,有条件的可以试试
参考:http://cmusatyalab.github.io/openface/
githup地址:https://github.com/cmusatyalab/openface