上周美国政府宣布禁止向中国四家单位出口超级计算机相关技术,Intel 显然备受伤害,因为国内的天河 2 号使用了 Intel 的 Xeon 处理器及 Xeon Phi 加速卡,而且连续四次获得了 TOP500 冠军,这不仅给 Intel 带来大笔利润,而且有很强的示范效应,现在这笔生意黄了,后续升级估计没戏了,只能靠中国特色国产了。

不管这是不是网上有些人说的美帝阴谋,不过美国在找理由阻碍他国超级计算机发展的同时也在加快自家超级计算机的研发。继去年底向 NVIDIA、IBM 投资 3.2 亿美元研发 10 亿亿次(100PFLOPS)超级计算机之后,美国能源部再次投资 2 亿美元给 Intel、Cray 公司研发 18-45 亿亿次超级计算机,主要部署在能源部下属的阿尔贡国家实验室,此前 NVIDIA、IBM 研发的 10 亿亿次计算机则部署在橡树岭、劳伦斯利弗莫尔国家实验室。
PS:虽然美国能源部下属的国家实验室名义上也是民用的,但了解过这些实验室历史的读者应该知道,核爆什么的也是他们的重点,美国用这种理由禁止 Intel 出口芯片到国内是“只许州官放火不许百姓点灯”。
这次 2 亿美金投资研发的超级计算机有两台,其中代号 Theta 的那台计算性能只有 8.5PFLOPS(8500 万亿次),使用的是 Intel 的 Xeon 处理器及代号 Kingts Landing 的 Xeon Phi 加速卡,这套 HPC 使用的都是成熟部件,性能较低,不过功耗也只有 1.7 兆瓦。
真正值得关注的是其中代号 Aurora(欧若拉,极光)的 HPC,因为要等到 2018 年才能部署,所以这台计算机,集各种黑科技高科技于一身,理论浮点性能可达 180PFLOPS(18 亿亿次),最高可扩展到 450PFLOPS(45 亿亿次),比 NVIDIA、IBM 的 10 亿亿次性能要高得多,也要比目前 TOP500 排名第一的天河 2 号的 54.9PFLOPS(5.49 亿亿次)高出2-7 倍多,除非中国能在未来两年内解决高性能计算芯片(自研不太可能,估计可以用各种小手段买到 Intel 或者其他家的芯片,毕竟美帝只禁止了国内四家单位,不是全面禁止 Intel 对中国的出口),否则 Aurora 在 2018 年登顶 TOP500 第一应该没什么悬念了,HPC 领域除了中国能与美国争锋之外,其他国家不论财力还是需求都小得多。

Intel 的 Aurora 超级计算机
我们再来详细看下 Intel 的 Aurora 超级计算机的架构组成,要想实现高达 18-45 亿亿次的性能(对比的 Mira 是目前的 HPC),Aurora 得使用新一代硬件,其中 Intel 已经证实 Xeon 处理器在其中只起到管理作用,计算主力是新一代的 Xeon Phi 处理器,代号为 Kinghts Hill,详情不多,但今年的 Kinghts Landing 已经使用了 14nm 工艺,这个 Knights Hill 加速卡不出意外将使用 2018 年的 10nm 工艺,单卡性能估计在4-4.5TFLOPS 之间,目前 Knights Landing 加速卡的性能约为 3TFLOPS。
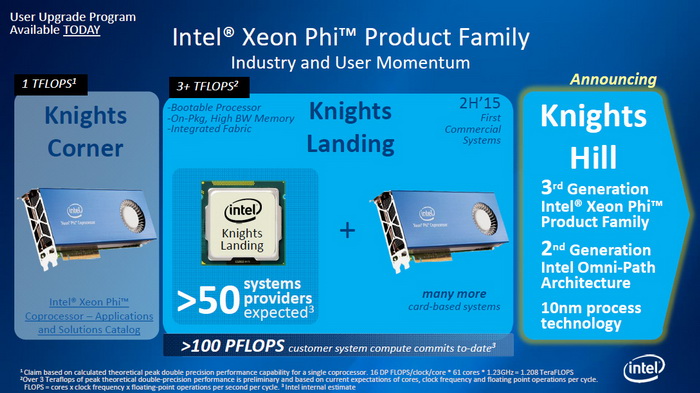
Aurora 超级计算机将使用新一代 Xeon Phi 加速卡
整套 HPC 将有超过 5 万个节点,基于 Cray 公司的 Shasta 新一代 HPC 平台设计,板载内存容量超过 7000TB,内存带宽高于 30PB/s,每个节点的带宽超过 2.5PB/s,带宽超过 500TB/s。存储系统则会使用 Intel 第一、第二代 Omni-Path 架构,容量不低于 150PB,文件吞吐量 1TB/s。
整套系统功耗为 13 兆瓦,比目前的 Mira 计算机的 4.8 兆瓦高了 1.7 倍,但其性能是后者的 18 倍还多,因此整体的每瓦性能比实际上从 2GFLOPS/W提升到了 13GFLOPS 了,能效比提升了 5 倍多。
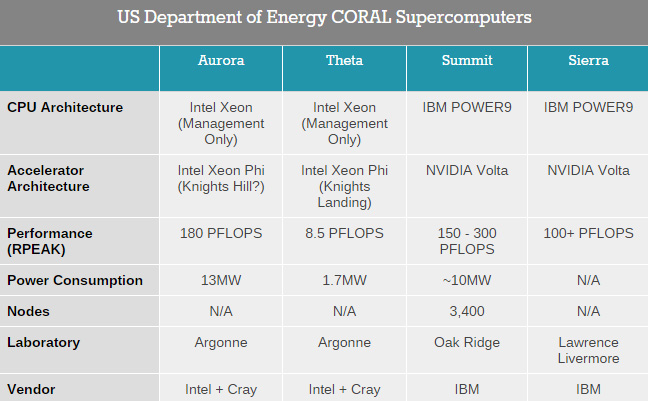
目前美国拥有或者在建的几台 HPC(Anandtech)








