本来是只打算写一篇关于中文乱码的blog的,但是发现要讲的东西跨度有点大,不好写到同一篇里面,所以分开了。
另一篇是 《【原创】通俗易懂地解决中文乱码问题(2) --- 分析解决Mysql插入移动端表情符报错 ‘incorrect string value: '\xF0...》 。
这一篇重点在编码的理论,另一篇重点在解决问题及思路。
一、问题的开始
中文乱码问题经常出现在实际工程中,尤其容易发生在经验不足的团队对问题预估不足的情况下。网站开发,社交聊天等对输入信息不可控的应用往往是重灾区。再加上移动互联网的火热,新兴字符和表情也开始频繁被使用,如果不能达到足够的支持,对用户体验来说是个灾难。所以,在设计系统的开始,要严格把控字符编码。以大体明确怎么做是不会出错的(严格按规则限制往往难以把控,并且容易漏掉被钻空子,所以做到不出错是出发点)。
二、Unicode
Unicode是本文的重点。
Unicode是一种通用字符集,是对字符的定义。和之对应的也有,比如 ISO 8859-1。但Unicode被广泛使用并成为业界的标准,所以我们可以认为Unicode就是对计算机里字符的定义,在内存中的表现是0,1串。
而且,Unicode的编码很干净,它为 字符而非字形定义唯一的代码。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器。举个例子,如 “class="Unicode">ɑ/a”、“強/强”、“戶/户/戸”。(引自wiki)
这样,Unicode本身要做的任务很明确,就是合适的扩充编码。
三、UTF-8
UTF-8是Unicode的一种实现方式,是可变长的字符编码。与之对应的还有GBK(固定长度),Latin,UTF-16(Unicode的完全式)等等。
这些为什么是实现方式呢?不是Unicode已经定义好了吗?其实这也是计算机学科经常用的方法,这些不同的编码就类似于针对Unicode的各种trick。
举个简单的例子,一个整形数组A[],那么给A[]排序这个定义就相当于Unicode。那么是采用快排、堆排还是归并,用正序还是倒序排列结果,这些方法就相当于编码格式。而这些都是对这个定义的具体实现过程,但是方法不同。
因此,不论是UTF-8、GBK、Latin等,其还原的编码结果都是同一个Unicode编码。
四、Unicode和UTF-8的关系及转换过程
那么对于Unicode和UTF-8的关系,可以用上面的例子理解。不过真实情况应该是类似下面这样的。
比如"国"字的Unicode编码定义为 00000000 00000000 00110100 11000000 (假设)。
由于其低16位都是0,为了减少存储和传输这个字在字节上的浪费,就选择高16位来表示。同时由于UTF-8是可变长的,所以需要标识位来标识这个编码到底使用了几个字节。
所以 “国”字 对应的 UTF-8的编码应该是 11100011 10010011 10000000(加粗的是原编码的高16位)。
转换公式:1110xxxx(E0-EF) 10yyyyyy 10zzzzzz,显示标明的是标志位)。
以下附上UTF-8的编码方式:(引自wiki)

五、中文跨平台乱码及解决办法
有了以上知识的积累,我们可以分析为什么跨平台会出现乱码?明明好好的Unicode怎么就乱了呢?
那么很直观我们会想到应该是编码格式不兼容。
对于windows平台,编码格式是GBK,对应的汉字是两个字节长度。对于Linux平台,编码格式是UTF-8,对应的汉字是3个字节。(这里都是默认情况)
那么我们还用上面 排序这个例子来解释。
比如现在Unicode用 {1,2,3}定义,GBK代表正序排列,UTF-8代表倒序排列。那么现在Unicode在GBK下的编码是{1,2,3},在UTF-8下的编码是{3,2,1}。
现在由GBK编码还原Unicode编码,那么正向解析GBK就是Unicode。而由UTF-8编码还原Unicode编码,需要逆向解析UTF-8编码。这都是和自身对应的。
但是如果一个把GBK编码误认为是UTF-8,那么逆向解析后的结果是{3,2,1}。首先这个结果不是原始的Unicode编码,那么其转换的结果不是我们需要的。其次,很可能这个编码结果在Unicode中还没有定义,可能会出现类似空格一样的空白符。
因此这就是跨平台中文乱码的原因,编码和解码方式出现了差别。
解决办法:
解决办法其实有很多种,根据自身应用的不同既可以选择在代码端进行编码的转换(比如java的 String str = new String(str.getBytes("GBK"), "UTF-8");),也可以在输入端进行编码格式的调整。
不过归结下来只有一点,即 如果当前输入是GBK编码,而你需要的又是UTF-8编码,那么:
1. 用GBK的解码方式转换成Unicode。
2. 使用UTF-8编码进行编码。
六、中文编码一些有趣的应用
这里我只想到了11游戏对战平台上面一些搞笑的名字(一不小心貌似暴露了什么。。不过很久不玩11了),后面想到其它还会更新的。
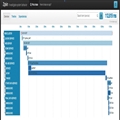
比如下面这个图:

蓝圈里面的玩家名字是正常显示的,为绿色。红圈里面的是蓝色,相当于突破了11客户端的限制显示了其它特殊颜色。
这个做法就是对应名字后面加上|r。这是一个转义符,合理的利用了11平台给用户开放的字符集并产生了特殊效果。所以这也是我开篇说的严格把控字符集是很难的,控制到不出错(比如系统乱码)已经挺好了。
转载请注明出处,谢谢~ http://www.cnblogs.com/xiaoboCSer/p/4175361.html