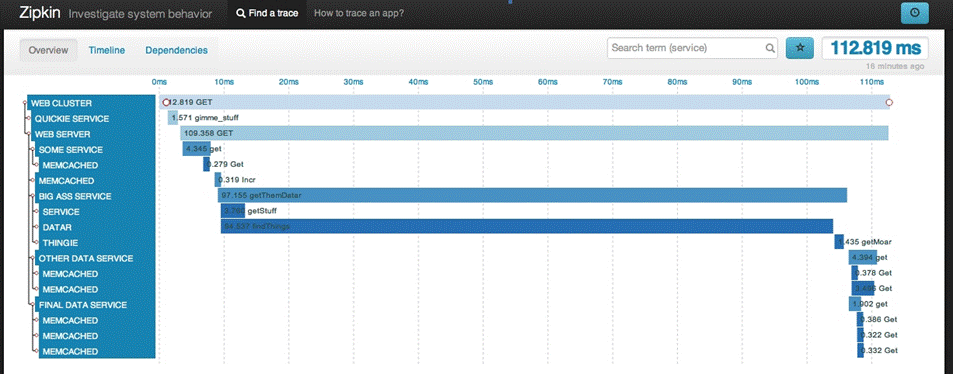
 图1 twitter zipkin 调用链
图1 twitter zipkin 调用链
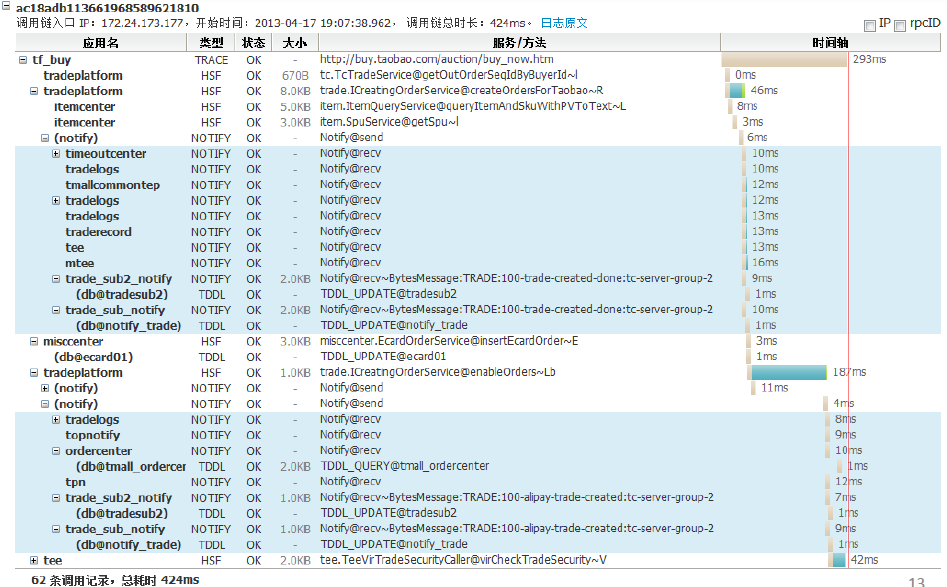 图2 淘宝鹰眼的调用链
图2 淘宝鹰眼的调用链
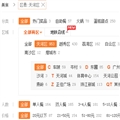
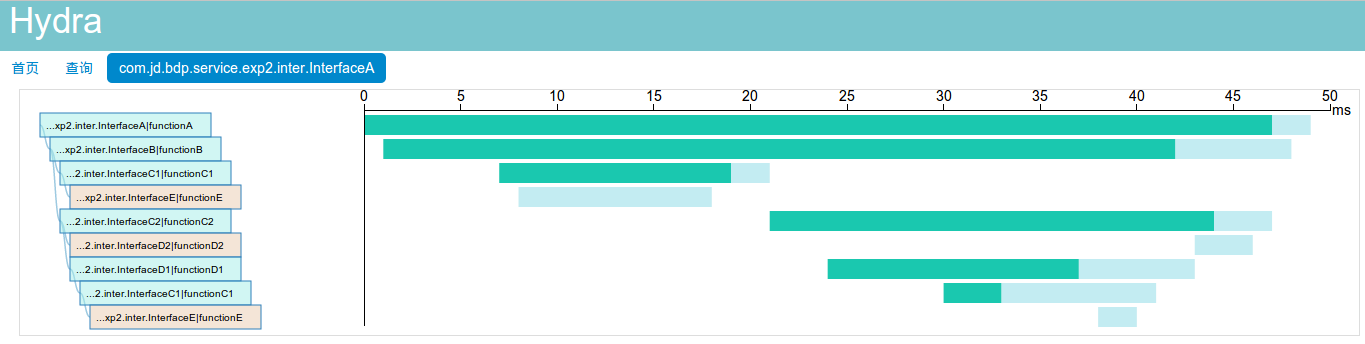 图3 京东商城hydra调用链
图3 京东商城hydra调用链
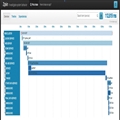
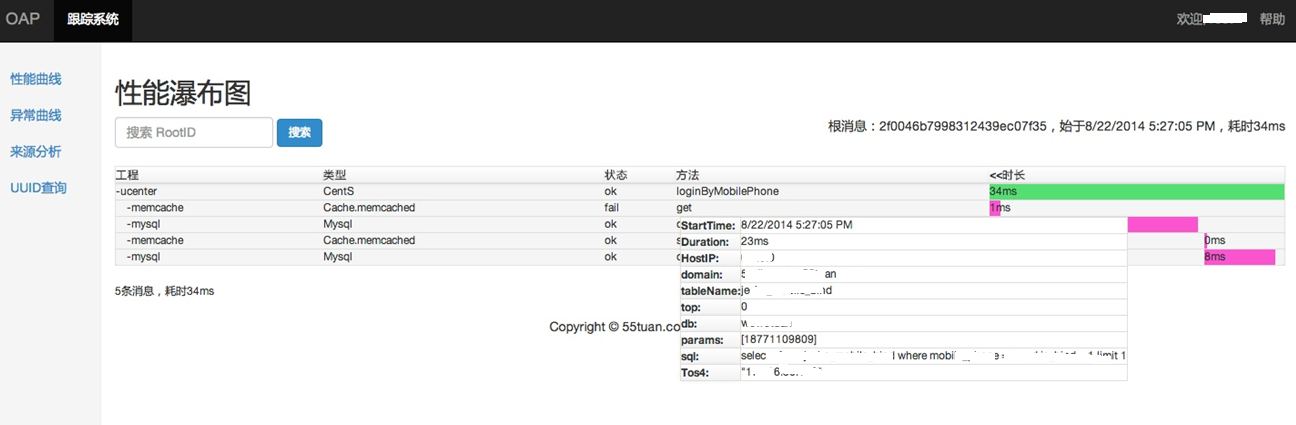 图4 窝窝tracing调用链
?
? 鼠标移动到调用链的每一层点击,可以看到执行时长、宿主机IP、数据库操作、传入参数甚至错误堆栈等等具体信息。
?
图4 窝窝tracing调用链
?
? 鼠标移动到调用链的每一层点击,可以看到执行时长、宿主机IP、数据库操作、传入参数甚至错误堆栈等等具体信息。
?
? 在前端请求到达服务器时,应用容器在执行实际业务处理之前,会先执行 EagleEye 的埋点逻辑(类似 Filter 的机制),埋点逻辑为这个前端请求分配一个全局唯一的调用链ID。这个ID在 EagleEye 里面被称为 TraceId,埋点逻辑把 TraceId 放在一个调用上下文对象里面,而调用上下文对象会存储在 ThreadLocal 里面。调用上下文里还有一个ID非常重要,在 EagleEye 里面被称作 RpcId。RpcId 用于区分同一个调用链下的多个网络调用的发生顺序和嵌套层次关系。对于前端收到请求,生成的 RpcId 固定都是0。
? 当这个前端执行业务处理需要发起 RPC 调用时,淘宝的 RPC 调用客户端 HSF 会首先从当前线程 ThreadLocal 上面获取之前 EagleEye 设置的调用上下文。然后,把 RpcId 递增一个序号。在 EagleEye 里使用多级序号来表示 RpcId,比如前端刚接到请求之后的 RpcId 是0,那么 它第一次调用 RPC 服务A时,会把 RpcId 改成 0.1。之后,调用上下文会作为附件随这次请求一起发送到远程的 HSF 服务器。
? HSF 服务端收到这个请求之后,会从请求附件里取出调用上下文,并放到当前线程 ThreadLocal 上面。如果服务A在处理时,需要调用另一个服务,这个时候它会重复之前提到的操作,唯一的差别就是 RpcId 会先改成 0.1.1 再传过去。服务A的逻辑全部处理完毕之后,HSF 在返回响应对象之前,会把这次调用情况以及 TraceId、RpcId 都打印到它的访问日志之中,同时,会从 ThreadLocal 清理掉调用上下文。如图6-1展示了一个浏览器请求可能触发的系统间调用。
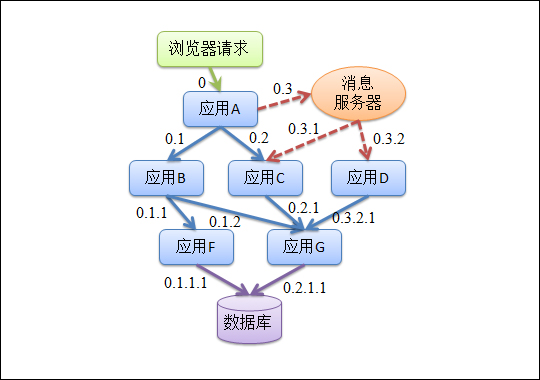
图6-1-一个浏览器请求可能触发的系统间调用
? 图6-1描述了 EagleEye 在一个非常简单的分布式调用场景里做的事情,就是为每次调用分配 TraceId、RpcId,放在 ThreadLocal 的调用上下文上面,调用结束的时候,把 TraceId、RpcId 打印到访问日志。类似的其他网络调用中间件的调用过程也都比较类似,这里不再赘述了。访问日志里面,一般会记录调用时间、远端IP地址、结果状态码、调用 耗时之类,也会记录与这次调用类型相关的一些信息,如URL、服 务名、消息topic等。很多调用场景会比上面说的完全同步的调用更为复杂,比如会遇到异步、单向、广播、并发、批处理等等,这时候需要妥善处理好 ThreadLocal 上的调用上下文,避免调用上下文混乱和无法正确释放。另外,采用多级序号的 RpcId 设计方案会比单级序号递增更容易准确还原当时的调用情况。
? 最后,EagleEye 分析系统把调用链相关的所有访问日志都收集上来,按 TraceId 汇总在一起之后,就可以准确还原调用当时的情况了。

图6-2-一个典型的调用链
? 如图6-2所示,就是采集自淘宝线上环境的某一条实际调用链。调用链通过树形展现了调用情况。调用链可以清晰地看到当前请求的调用情况,帮助问题定 位。如上图,mtop应用发生错误时,在调用链上可以直接看出这是因为第四层的一个(tair@1)请求导致网络超时,使最上层页面出现超时问题。这种调 用链,可以在 EagleEye 系统监测到包含异常的访问日志后,把当前的错误与整个调用链关联起来。问题排查人员在发现入口错误量上涨或耗时上升时,通过 ?EagleEye 查找出这种包含错误的调用链采样,提高故障定位速度。
调用链数据在容量规划和稳定性方面的分析
? 如果对同一个前端入口的多条调用链做汇总统计,也就是说,把这个入口URL下面的所有调用按照调用链的树形结构全部叠加在一起,就可以得到一个新的树结构(如图6-3所示)。这就是入口下面的所有依赖的调用路径情况。
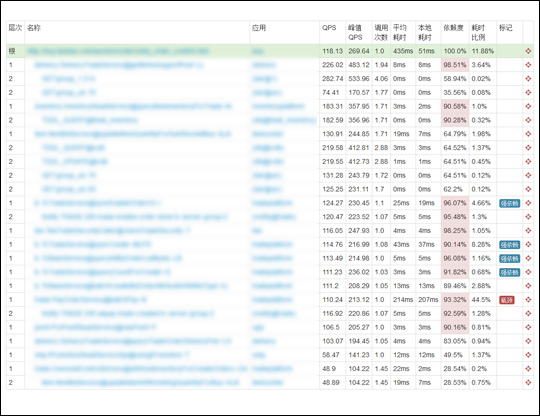
图6-3-对某个入口的调用链做统计之后得到的依赖分析
? 这种分析能力对于复杂的分布式环境的调用关系梳理尤为重要。传统的调用统计日志是按固定时间窗口预先做了统计的日志,上面缺少了链路细节导致没办法对超过 两层以上的调用情况进行分析。例如,后端数据库就无法评估数据库访问是来源于最上层的哪些入口;每个前端系统也无法清楚确定当前入口由于双十一活动流量翻 倍,会对后端哪些系统造成多大的压力,需要分别准备多少机器。有了 EagleEye 的数据,这些问题就迎刃而解了。 ? 下图6-4展示了数据流转过程。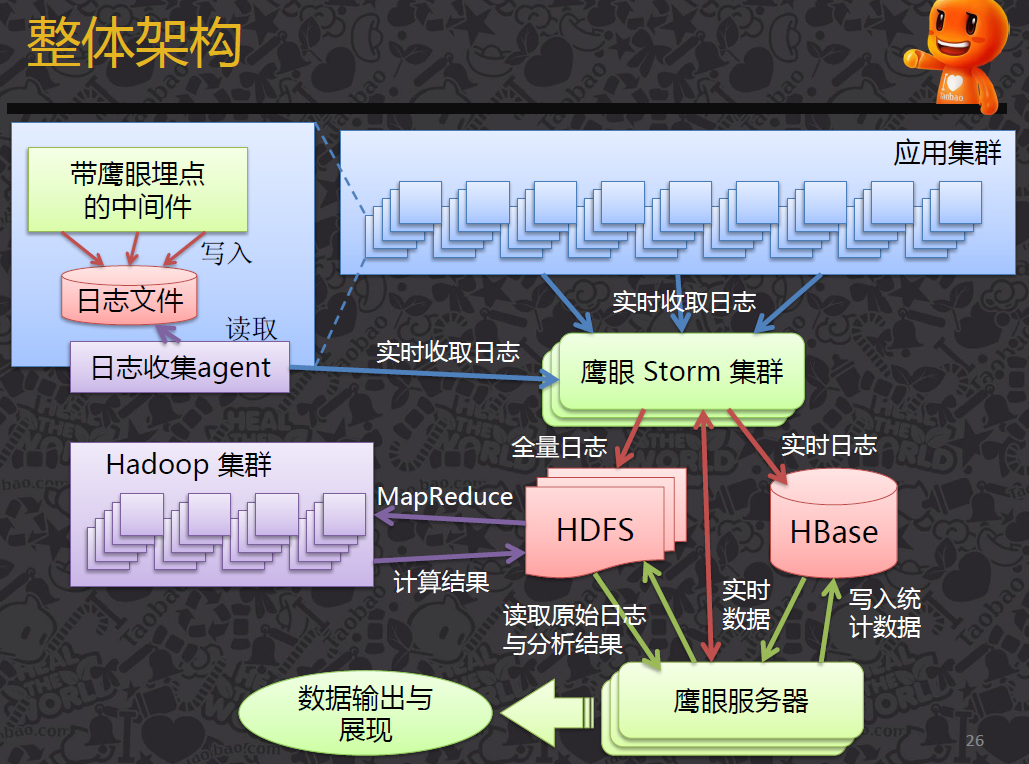 图6-4 鹰眼的数据收集和存储
?
京东如何实现的:?
? 京东商城引入了阿里开源的服务治理中间件 Dubbo,所以它的分布式跟踪 Hydra 基于 Dubbo 就能做到对业务系统几乎无侵入了。
? Hydra 的领域模型如下图7所示:
图6-4 鹰眼的数据收集和存储
?
京东如何实现的:?
? 京东商城引入了阿里开源的服务治理中间件 Dubbo,所以它的分布式跟踪 Hydra 基于 Dubbo 就能做到对业务系统几乎无侵入了。
? Hydra 的领域模型如下图7所示:
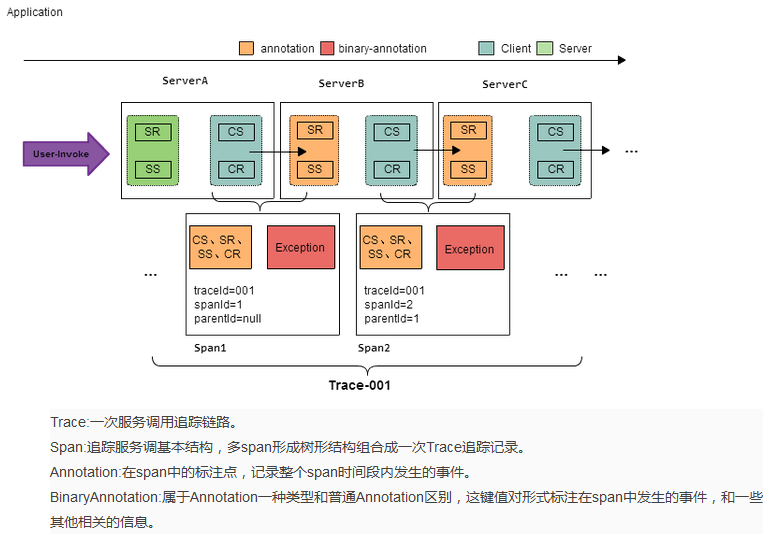 图7 hydra 领域模型以及解释
? hydra 数据存储是 HBase,如下图8所示:
图7 hydra 领域模型以及解释
? hydra 数据存储是 HBase,如下图8所示:
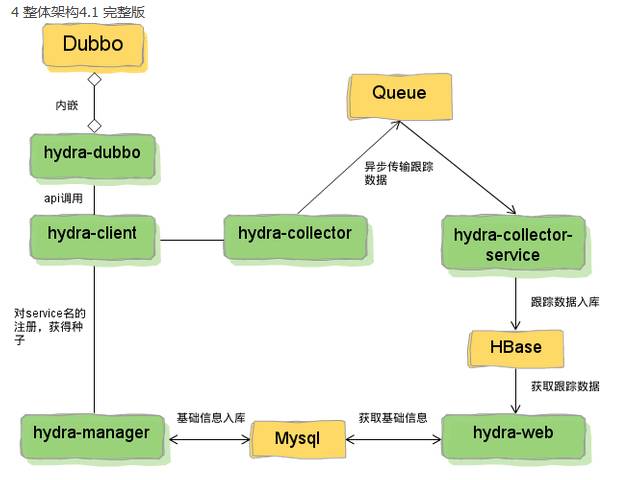 图8 hydra 架构
?
窝窝如何实现的:?
? 2012年,逐渐看到自建分布式跟踪系统的重要性,但随即意识到如果没有对 RPC 调用框架做统一封装,就可能侵入到每一个业务工程里去写埋点日志,于是推广 Dubbo 也提上日程。2013年,确定系统建设目标,开始动手。由于 tracing 跟 DevOps 息息相关,所以数据聚合、存储、分析和展示由运维部向荣牵头开发,各个业务工程数据埋点和上报由研发部国玺负责。
? 经过后续向荣、刘卓、国玺、明斌等人的不断改进,技术选型大致如下所示。
图8 hydra 架构
?
窝窝如何实现的:?
? 2012年,逐渐看到自建分布式跟踪系统的重要性,但随即意识到如果没有对 RPC 调用框架做统一封装,就可能侵入到每一个业务工程里去写埋点日志,于是推广 Dubbo 也提上日程。2013年,确定系统建设目标,开始动手。由于 tracing 跟 DevOps 息息相关,所以数据聚合、存储、分析和展示由运维部向荣牵头开发,各个业务工程数据埋点和上报由研发部国玺负责。
? 经过后续向荣、刘卓、国玺、明斌等人的不断改进,技术选型大致如下所示。