class="topic_img" alt=""/>
class="topic_img" alt=""/>
����Ӣ��ԭ�ģ�SQL Server Source Control and Deployment with Visual Studio
�������Ľ�Ϊ��������� Visual Studio 2013 �� SQL Server Data Tools��SSDT����һ���ԣ������Կ���������Դ����������һ�������й������ݿ⡣����˵���������ݿ������ͼ�ȶ�����ģ�������Դ����ķ�ʽ�� Visual Studio ����ɡ�Դ����������������������ݿ���бȽϣ������ڱ���������һ�ݲ����ű���
����ǰ��
�������������ʹ�� SQL Server 2014����ȷ�����Ѿ������� SSDT�������� Visual Studio �е�“��������չ”�˵����н��и��¡�
���������ݿ���з���
����ͨ��“����”ָ�SQL Server Data Tools ���Զ�һ�����е����ݿ���з��̣�����ת����һ���յ���Ŀ�С���Ҫָ�����ǣ�����Ŀ���뱣֤����ȫ�յģ�һ�����������Ŀ�м������κ��ļ���“����”ָ�����Ӧ�������ݿ����ˡ�
�������ȣ�����һ��ȫ�µ� SQL Server Database ��Ŀ���Ҽ����� Solution Explorer �е���Ŀ����ѡ��“����”����ѡ��“���ݿ�”��
�������ݿ���Ŀ����ǿ����ʹ���κ�������ļ��нṹ���� C# ��ͬ����ʹ���ļ��нṹ��ΪĬ�ϵ������ռ䣬�� SSDT �����㽫ij�� schema �еĶ������Ϊ����� schema ���������ļ����С�������ˣ��õ��빤����Ȼ��Ϊ���Ƽ�һЩ�ļ��нṹ����Ϊ��Ŀ����㡣��������ѡ�
����������С�����ݿ��У���Ҳ������ʹ�� Schema/�������ͽṹ�������ֻʹ�� Schema �ṹ��������ͻ�������ͣ�ش����ļ���������Ϊ�˲鿴���ļ���ʲô���͵ġ��������ֻʹ�ö������ͽṹ���Ǿͻ��ʹ�������������ڽ����ж������� dbo ��� schema �¡�
�������ݿ�����
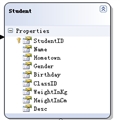
������“��Ŀ����”�����ǩҳ�¿����ҵ����ݿ��ͨ�����á������û���ҵ���Ҫ�������Ҳ����ͨ�� SQL ���ֱ�����ӡ��ڱ����Ժ��“�洢”��һ�����㽫������ص�ʾ����


��������ѡ��
�����������뿪��Ŀ�����������ǰ���㻹��Ҫ����һ���������ݿ⡣ÿ�����Ӧ�ó���ʼ����ʱ�����ݻ��Զ���������������ݿ��С������ѡ������ݿ����Ʋ����ڣ���ô�������Ŀ��������ʱ�����Զ�����������ݿ⡣
����һ����˵����Ӧ�û�ѡ��“��Ŀ�����ݿ���ɾ����������Ŀ�б���”��һѡ�������ĵ������ݿ�ͻ��ۻ��ڿ�����������һ�ȴ���������ɾ������Щ����
����ֻ������һ������Ϳ���������ݿ�����ã�����֧���Զ������ˡ�����Ҫ����������������������������ݿ���Ŀ����Ϊ������Ŀ��һ�������

�����洢
�����������Ҫָ������ģ��������ض����ļ��飬�����ʹ����Ŀ���õĶ���ģ�壬���ǽ��������������µĽű���
ALTER DATABASE [$(DatabaseName)]
ADD FILEGROUP [FileGroup1]
������ע������� sqlcmd ������ʹ��[$(DatabaseName)]�������ϣ����ͬһ̨�������ϲ���ͬһ�����ݿ���Ŀ�Ķ������������������á�
������ȫ
����������һ�������ݿ�ʱ�����Ǿ����᷸����������һ������Ϊ�����˷������еķ���Ȩ�����Ҽ��轫��ijһ�����������Щ����Ȩ����ȫ����������ʮ����ģ�������ʹ�ø�����ʱ�����ܿ��ܳ���������ϡ���ˣ����õķ�ʽ���ڴ����û��ʺŵ�ʱ��Ҫ�����κ�Ȩ�ޣ��������ҪʱΪ����������ض���������Եķ���Ȩ��
����Schema
�������ݿ�����̻Ὣ schema ���崴���� Security �ļ����У������Ǹ� schema ����Ӧ��ͬ���ļ����С����ס���ļ��е�λ�ò�����Ҫ�������ѡ�� schema �Ķ����ƶ��������ļ����С�
������¼�ʺ����û�
������Ȼ�Ӽ����Ƕ�����˵����¼�ʺ���һ�������������������ݿ��������Ȼ���Խ�����������Ŀ�С�����õ�¼�ʺ��Ѿ������ˣ���ô�ڲ���ʱ���Զ���������
���������ڴ�����¼�ʺ�ʱ���벻Ҫʹ��“USE master”ָ������Զ�Ϊ����д�����
������Ĭ������£��´����ĵ�¼�ʺź��û����������ӵ����ݿ������������ζ������Ҫ�ڽű��м���һ��“GRANT CONNECT TO [userName]”��䡣
�����������͵İ�ȫ����
�����������͵İ�ȫ���������ɫ���ǶԳ�Կ��֤��ȵ�Ҳ���������Ƶķ�ʽ���д�����
�����������ݿ��
�����ڴ���һ���±�ʱ��ֻ���Ҽ������������ñ����ļ��У���ѡ��“����һ�ű�”��������Ҫ�ṩ schema ��������м���.�ָ�������������Ϳ���ʹ��������� SQL �༭����ʼ���Ӹ����ֶ��ˡ�
��������
��������������Ϊ�������һ����һͬ���ӣ�Ҳ������Ϊһ������������������ͬһ���ļ��С������ϣ���Ҳ����Ϊÿ����������һ���������ļ����������ַ�ʽδ����Щ�����鷳�ˡ�
���������ڶ���������д�������ʱ����Ҫע����ÿ������ʹ�� GO ���Ϊ�������ķָ�����
�����ĵ�
������ Visual Studio 2013 �У�����Ҳû�������Ϊ�����ֶ������κ�ע���ˡ��������������Ϣ��Ҫ��“����”����н������ã���Ҳ����ͬ��ʹ��“����”��������ֶε���������������ϲ���ڱ�������������ֶε�ע�͡�
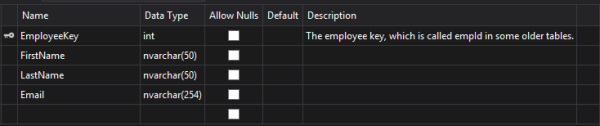
��������ʵ���� SQL Server ��һ�������ԣ����ںܾ�֮ǰ SQL Server ��֧��Ϊ�����ֶ�����ע���ˡ���һ����ֻ�ǽ������滻Ϊ sp_addextendedproperty ��һ���µ�����ѡ�
EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'The employee key, which is called empId in some older tables.', @level0type=N'SCHEMA', @level0name=N'dbo', @level1type=N'TABLE', @level1name=N'Employee', @level2type=N'COLUMN', @level2name=N'EmployeeKey'
��������
�����ڵ���ʱ�����Զ�����
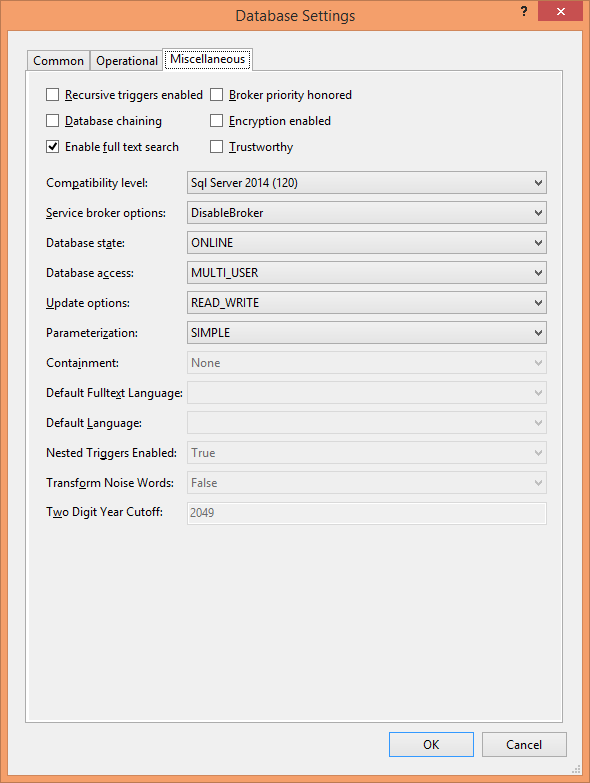
����Ҫ���Զ������ܣ�����Ҫ���ȴ����ݿ���Ŀ�����е� Debug ��ǩҳ�����ġ�һ����˵������Ҫ�������ַ�����Ϣ����������ݿ�Ƚ�С���������ܹ�ͨ���ű����¼����������ݣ���ôѡ���Զ��ؽ����ݿ�Ҳ����һ�������⡣��������Ҫ����ɾ�����в���Դ�������ϵͳ�еĶ����������Ա�����������ʹ����ijЩ�����������в������ڵ����ݿ����
����������������Ҫ�������ݿ���Ŀ����Ϊ������Ŀ��һ�����������Ҫ��“�������”���öԻ�����������Ŀ�����������һ���衣
��������
����ͨ���Ҽ��������ݿ���Ŀ����Ϳ��Դ����Ի�����������Ŀ�����ݿ�������ַ���������������Դ�“��”��ǩҳ����Ӧ�ó����������á�������˵�������������У�����ܻ�ѡ���ڷ���ʱ�������ݲ��衣���ڿ�����Ԥ�����������ϣ�������������Ŀ�еĶ���ȫ��ɾ��Ҳ�Ǻ���Ҫ��һ�㡣������ϸ�����Щ���ã����������ಿ����Ҫ���濼�ǡ�
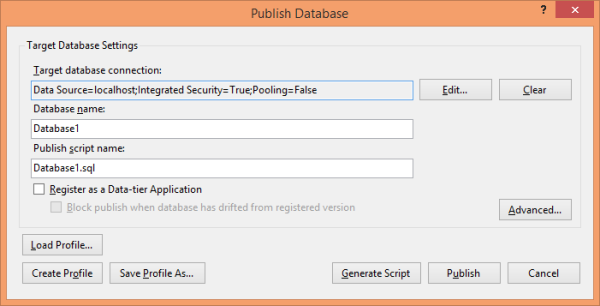
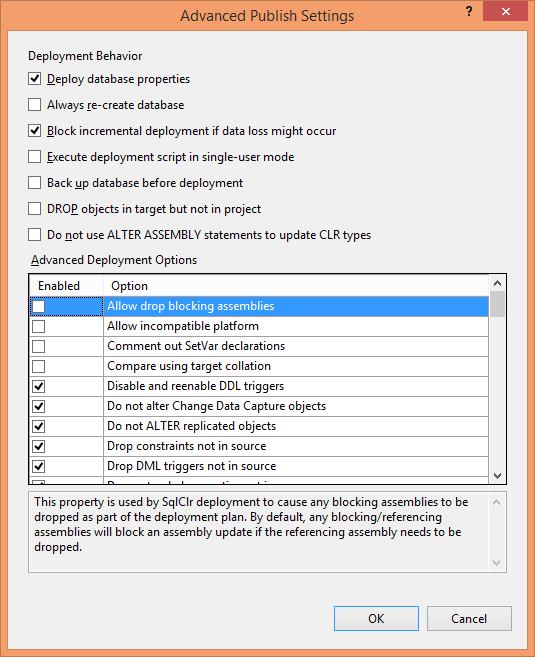
������������Ӧ�ñ�����������ű�����������һ�� .publish.xml �ļ��������ᾭ���õ�����Ҫ��������ļ�ʱ��ֻ���� Solution Explorer �����˫�����Ϳ����ˡ�
���������ѡ�����Լ��Ĺ��������ϣ�����ֱ�ӵ���“����”��ť������������Dz����������ϣ��Ǿ�Ӧ��ѡ��“���ɽű�”ѡ���������£��㲻����ȥ������ɵ��ļ��������� Data Tools Operations ����е���“���Ԥ��”�������г��ýű����ݵ�һ��С�ᡣ
����������������Щ�������ö�û�����ˣ��Ϳ���ͨ��“����”ѡ������������η����ű���
�����IJ���ű�
������Щʱ������Ҫ�Է����ű�����һЩ�ֶ��ġ��������ͨ�������ڶ�ij�����IJ�����������ݶ�ʧ������¡����罫ij���ֶ���Ϊ��������ֵ�����������ֶ��������͡�
������ Visual Studio ���Dz��ܹ�ֱ���IJ���ű��ģ�����Ҫ���ű������� SQL Server Management Studio �С���ȷ������“��ѯ”�˵��д��� SQLCMD ģʽ����Ϊ����Ҫ����ijЩ���ã��������ݿ����Ƶȵȡ�
��������һ��������������Ҫ�IJ���ű������ǽ��ű��ֽ�Ϊ���С��Ƭ�Ρ��ȷ�˵������ijЩ��������֮�⣬����ܻ���ҪΪij���������ܴ�ı�����һЩ���������ڴ�����Щ�����Ĺ���ʱ����ܻ�ܳ����������������������ĸĶ��ڼ���Сʱ֮���ٽ��У�������֮ǰ��ȻҪ���нű����������֡�
�����ع���־
����SQL Server Data Tools �ڲ�ά����һ���ع���־����Ҳ���������ֶ��༭����ű�����Ҫ�����ҵ�����һ���Ժ�����������֮�б����ԡ�����������������������ij���ֶε����ƣ���θĶ��ͻ��¼����־�С��������ֱ�Ӷ������ű������ԭʼ SQL ���б༭����ô��־�оͲ����������ĵļ�¼��
�����������������������һ���⣬�����㿪���������ݿ�ʱ����νű��᳢��ɾ��ij���ֶΣ����������һ�����ֶΣ����������������Ķ��ֶ�ֱ����������һ��������������������ѡ��Ҫô�����ع���ĸĶ���������“��ȷ�ķ���”����һ�飬��ζ������Ҫʹ�ñ���������в�����������Ҳ����ѡ��Բ���ű������ֶ��ġ�
����������ͼ���Զ��������ʹ洢����
����������Ӧ�ó����ǻ��� ORM �����ģ���ô�����Ͽ��Ժ�����һ�����ݡ�
��������
��������Ĵ���һ���������㽫��ͼ���Զ��庯���ʹ洢���̷������ﲢû��ǿ�ƵĹ涨�������ѡ��ʹ�� Schema/����������һ�ļ��ṹ����ôĬ�ϵ�������Ϊ�����ֶ�����Դ���һ���������ļ��С�����һ��ѡ���Dzο� SQL Server Management Studio ��ģʽ�������Ǹ��Էֽϸ���ȵ��ļ����С�
���������ַ�ʽ���Խ��¶��������Ŀ�У������ѡ�����ģ�崴��������������������ݣ���������б�������ͼ���ݡ�������Ҳ����ѡ���� SQL Server Management Studio �д����øö���������Ҳ�ȷ���ö���ľ������ݣ�����Ԥ�ƻ����������ʱ��ͨ���һ�ѡ�����ַ�ʽ��һ����ȷ�������е����ݣ��ҾͻὫ�䱣��Ϊһ�� SQL �ļ�������뵽�ҵ���Ŀ�С�
�������Ӱ�ȫ����
��������������ݿ��Ѿ������˺��ʵİ�ȫ�����������������Ҫ�����ֶ�����û�������Ȩ�ˡ���Ȼ�ж��ַ�ʽ���������һ�����һ��ǽ��齫 GRANT �������붨����ͼ���Զ��庯���ʹ洢������ͬ���ļ��С�����һ������һ�۾��ܿ�������ִ����ι��̵��û��Ƿ�����Ȩ�ޡ�
��������֮ǰ��֮��Ľű�
����SQL Server Data Tools �����㴴��һ�������IJ���ǰ�ű����Լ�һ�������IJ����ű�����Щ�ű�����һ���Ե�Ǩ�ƽű���������ÿ�β���ʱ�������е����ݡ�
�����������ű��������ֱ�Ϊ Script.PreDeployment.sql �� Script.PostDeployment.sql�����Dz��������� SQL �ű�������һ�ֳ�Ϊ SQL CMD �ı��塣ͨ�� SQL CMD ���Զ����� SQL �ű��������á�
������ʶ������������Ҫ����Ϊ��IJ���ǰ�벿���ű������ױ�û��ң�Ϊ�˱�����ҵIJ������ҽ����㽫����ű���ΪĿ¼һ����������ÿһ��IJ����ֱ�洢�ڲ�ͬ�Ľű��ļ��С�������һ�����͵IJ���ǰ�ű���ʾ����
PRINT N'Enabling CLR'; EXEC sp_configure 'clr enabled' , '1'; RECONFIGURE; :r ".\OneTimeScripts\Migrate records to not use customer type 6.sql"
�������������Ӧ�IJ����ű���
:r .\Data\UserType.sql
:r .\Data\CustomerType.sql
:r .\Data\AccountLevel.sql
����ʱ��
��������ǰ�ű���ִ��ʱ���������ݿⴴ��֮������������������ݿ�֮ǰ�����������ķ����������ݿ⼶������ã�����Щ���ò�û��ֱ��ͨ�� SSDT ��¶������
���������ű�ִ�е�ʱ�����������������������ʾ��һ���������������������ݿ�����º�����еġ�
������дһ���Խű�
������дһ���Խű��������ס����ȣ�SSDT �в�û��һ���Խű��ĸ����Ϊ���������ij�νű��Ƿ��������й���������������ľ��Ǿ����� if ��串����Ľű����Դ˽����жϡ�
��������һ���Խű�����һ�ַ������ֶ��IJ���ű������ַ�ʽ���и߶�����ԣ���ȴ�Dz����ظ��ģ�������ÿ����������Ӧ�����еĸĶ���
�������ر����ݵ�ģʽ
����SSDT ����ȱ�ٵ���һ�������DZ��ļ��أ����������£����еIJ��ұ����ݶ�Ӧ�ñ�����Դ��������У���ͬ�������ݿ����һ������������һ���Ե�ȱ�������Dz��ò�ͨ���������;��ʵ����һ���ܡ�
��������һ��;����ʹ�� MERGE ��䡣���ȣ�Ϊ���Ŀ�������һ���ṹ���Ƶ���ʱ��������ڸ���ʱ���м�������������ݡ������Ϳ���ʹ�� MERGE ���ִ�б�Ҫ�IJ��롢���º�caozuo.html" target="_blank">ɾ��������
��������һ��;���DZ�дһ���������µĴ洢���̣�Ȼ��Ϳ���ͨ�����øô洢���̶�Ŀ����е�ÿһ�н��в����ˡ����ַ��������㴦�����ӵ���������ͨ�����ַ�ʽɾ�����ڵ����ݡ�
�����������ݿ�
�������ڴ���ϵͳ��˵������ʹ�� schema ��Ϊ�����ռ������Dz����ġ����ڶ��ֲ�ͬ��ԭ�����粿�����ڡ���ȫ�������ܺ��ֱ��������Ὣ����ֲ��ڶ�����ݿ⡢������̨�������ϡ�
����ֻҪ�����Щ������üƻ���SSDT ���ܹ�����������Ҫע���һ����ѭ�����õ�������ij���� SSDT ���������ݿ���Զ���һ�����ݿ�������ã����º��ߴ��ڲ�ͬ�ķ������ϣ�ֻҪ���ܹ�����һ�������ı���˳��Ϳ���ʵ����һ�㡣�������κ� .net ��Ŀ����������ȫһ���ġ�
����һ�ֳ����������ǣ�ij���½������ݿ���Ҫ����ij������ϵͳ�����ݿ⡣����ҪΪ�����ݿⴴ���ű��������䵼�뵽һ���յ���Ŀ�С��㲢����Ҫʹ�� SQL Server Data Tools ��������������ݿ⣬ֻ��Ҫ������Ӧ��Ԫ���ݾͿ����ˡ������Ҫ����Ҳ���Խ���������Щ�����ݿ��������Ķ���
��������������Ҫ����һ�����ݿ����ã�����������Ҫ����һ����Ҫ�ľ������Ƿ��þɵ����ݿ�Ҳפ����ͬһ̨�������ϡ���Ȼ��Ҳ�����º�ı��뷨�������̼��鷳�����׳������������������õĶԻ���
�������е����ݿ�����Լ���ѡ�ķ����������������Զ��庯�����洢���̵�ʵ�����Ʋ���Ӱ�죬�����ȷ����ʹ����[$(variable)]��һģʽ����������ܻ��������������ʵ�ʷ���ʱ��ϵͳ��Ҫ����Ϊ��Щ��������ʵ�����ơ�
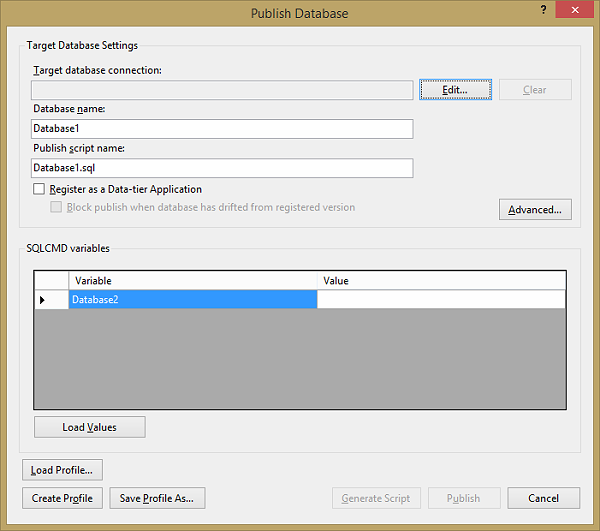
�������㰴��“����ֵ”��ťʱ������Ŀ�����������Ĭ��ֵ����Ϊʵ�ʵ�ֵ������Щ�����С�Ϊ���ڽ��IJ����н�Լʱ�䣬��Ҳ���Խ���Щ��ֵ����Ϊ����������һ���֡�
����SQL CLR
������Ȼ�� SQL Server ��ʹ�� C# �������������һ������һЩ���飬����ijЩ����»��Ƿdz����õġ���ijЩ�����У��� JIT ����� .NET �����������͵�T-SQL ��õ����õ����ܡ�������ijЩ����������˵�����缸�����������λ�ã�����ȫû������ѡ��
����ʹ�� SQL CLR ��һ����Ҫ�������ڲ���ͨ����˵��Ҫ��һ�� .NET ������ SQL Server �У���Ҫ�ֶ��� DLL ������ij�������һ��һ���ؽ����ֶ����ӡ�SSDT �ķ��������ܹ�������һ���⣬���Ὣ������������Ϊһ�� SQL ��䣬�벿��ű������ಿ�ֽ���������
�����ⲿ��Ŀ�����
��������Լ�������� SSDT ��Ŀ�ij����������ӵ�һ����Ϊ“Assemblies”���ļ����С���Ȼ�Ⲣ�DZ��룬������ʹ�ö� DLL �Ĺ����������ס�����������ѭ��һ���飬�����������һ���衣
�����������������ͨ�����õ� .NET“��������”�Ի������Ӷ�ij����Ŀ���dz������á�
�������һ���ǽ�����Ҫ�� SQL ��ʹ�õ������뺯����¶�������������“������Ŀ”�Ի����е� SQL CLR �ļ���ѡ�����ҵ���Ӧ��ģ�塣�����������ֶ�ע�� SQL CLR ���ͺͺ���û�зֱ�
�����ڲ���Ŀ
�����ڲ���Ŀ��ָפ�������ݿ���Ŀ�е�ij�� C# ��Ŀ�������������ݿ��Զ���������������㲻�ص��Ķ����ü����Ĺ�������Ȼ����ʵ�� CLR �汾�ľ�̬����������ܣ�������֮��������Ϊ������ C# ��Ŀ�����ȫһ�¡�
�����ڲ���Ŀ��һ�����õ��������ڣ��㲻��Ҫ��ʽ��ͨ�� SQL ע�ắ�������������� SqlFunction ����֮���Զ�����Ŀ�����Ĭ�������ռ��д�����ȷ�� SQL ԭ�͡�
�����ر�������
��������Ӧ�� CLR ��Ŀʱ���������ڲ���Ŀ�����ⲿ��Ŀ���ر��붼���Ϊ���⡣�����ǵ�����ij�������ֶ���ʹ����ij�� SQL CLR ������ʱ��
���������ϣ��������� Visual Studio �ᾭ���� C# ��Ŀ�����ر��룬����û���κθı䡣�����µİ汾��ʹ����һ���µ� hash �룬�������߾ͻ���Ϊ����Ŀ�Ǹ��µİ汾���������²�������������֮ǰ���ᵽ�ļ����ֶεij����У��������߾���Ҫ����Ӱ��ı��е�ÿһ�н������¼��㡣
����������������ʱ�����Խ� SQL CLR ����Ǩ�Ƶ�ij���ⲿ��Ŀ�У����������Ŀ���ŵ� Assemblies �ļ����У�����ͬһ�����������һ����Ҫע��������ַ�ʽ��һ�����գ��Ǿ�����ܿ����ڽ��б����ʱ�����˸��¸ó���
����ȫ������
����SQL Server Data Tools ��ȫ���������ṩ�˲���֧�֣������ڴ��������ȫ������Ŀ¼�ṩ�����õ�֧�֣���Ҳ���Խ� FTS �������ӵ��κ���Ҫʹ�����ı��С�������������������ڣ�SSDT ��֧�ֿյķ������ֱ���StopList����������Ϊ�������ֱ��е����ݱ���Ϊ���ݣ������� schema����� SSDT ��֪����ν��������ݱ��ָ��¡�
������һ��Ӧ�Ը��������ʱ����������ʹ�ò����ű��������е����ݣ�����ͬ���ڲ��ұ����ݵĴ�����ʽһ����һ�������˷������ֱ�֮�������߽������������е����ݡ�
�����汾��
����SQL Server �������ڰ汾�Ų�û��һ��ǿ�ҵĸ���������ϣ��������ij����������ݲ��Ӧ�ã�dacpac���м���汾�ţ������ַ�ʽ��ʵ�������������еġ�Ŀǰ��û��һ�ַdz����õķ�ʽ�ܹ���ȡ�����ֵ����ֻ��ѡ���ڹ�����ű��ж� dacpac �汾�����Զ���ֵ������
��������Կ��Dz�ȡ���ַ�ʽ������һ���ڲ���Ŀ������ֻ����һ����Ϊ dbo.GetDatabaseVersion �ĺ������ú����ܹ��� C# �����ж�ȡ�汾�š�������ڳ��汾��ʹ����ͨ������汾�ž��ܹ��Զ����ӡ�
������һ��ѡ���Ǵ���һ����Ϊ dbo.GetDatabaseVersion ��T-SQL ���������᷵��һ��Ӳ�����ֵ�����������Ҫʱ�ֶ���������ֵ��
����Brett Gerhardi �Ľ����ǣ�Ϊ���ݿ�汾����һ����չ���ԡ��ο�����������
EXEC sp_addextendedproperty @name='DbVersion', @value ='1.015', @level0type = NULL, @level0name = NULL, @level1type = NULL, @level1name = NULL, @level2type = NULL, @level2name = NULL
���������ʹ�ù���ǰ�ű�����ô������ֶ���������ֵ��
������������
�����������ϣ������ʹ�� SqlPackage.exe �Զ��������ݿ⡣Anuj Chaudhary �ڲ����з�����һƪ���ӣ���Ϊ“SqlPackage.exe —— �Զ��� SSDT ����”��Ϊ���������һ���̡�����ʵ���У���ᷢ����ijЩ������������Ը��½����ֶ����������� SSDT ��˵�������Եù��ڸ��ӡ�