基本思想
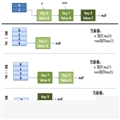
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量
=1(
<
…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法
比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比[1] 较就可能消除多个元素交换。D.L.shell于1959年在以他名字命名的排序
算法中实现了这一思想。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
算法分析编辑
优劣
不需要大量的辅助空间,和归并排序一样容易实现。希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间复杂度与增量序列的选取有关,例如希尔增量时间复杂度为O(n2),而Hibbard增量的希尔排序的时间复杂度为O(
),希尔排序时间复杂度的下界是n*log2n。希尔排序没有
快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(
)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要的个数很少,但数据项的距离很长。当n值减小时每一趟需要和动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的
结合才使希尔排序效率比插入排序高很多。
时间性能
1.增量序列的选择
Shell排序的执行时间依赖于增量序列。
好的增量序列的
共同特征:
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
有人通过大量的实验,给出了较好的结果:当n较大时,比较和移动的次数约在nl.25到1.6n1.25之间。
2.Shell排序的时间性能优于直接插入排序
希尔排序的时间性能优于直接插入排序的原因:
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和
的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(
)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
Java实现代码
public
class ShellSort {
static void sort(int[] array) {
int out, in, tmp;
int len = array.length;
int h = 1;
while(h < len / 3) // 计算间隔h最大值
h = h * 3 + 1;
while(h > 0){ // 能否继续通过缩小间隔h来分割数据列的判定
/*
* out为什么从h开始?你分割后的第一子序列应该是这样一个序列,0, h, 2h, 3h, ...
* 插入排序的while
循环是从1开始的,因为第一个数始终有序,不需要比较,这个需要了解插入排序的算法,所以比较是从第二个数据线,就是数组的第h个下标开始
* out的判定为什么是out < len?
* 控制数组下标,下面的
例子会说道
*
* 下面举一个例子来解释
* 假定有一个10个数据项的数组,数组下标从0 ~ 9 表示
* 当h = 4时的子序列情况是这样的,以下标表示
* (0 4 8)(1 5 9)(2 6)(3 7)
* 我第一次是这么
理解的,真对每一组分别进行插入排序(当然也可以这样实现,但是下标不好控制),但是对下面的代码来说这是
错误的理解。
* 正确的过程是这样的,外层for循环每次对每一分组的前两个数据项进行插入排序,然后前3个,然后前4个 ... 这个和子序列个数有关
* 排序过程只真对方括号进行
* 当out = 4时进行如下过程 ([0 4] 8)
* 当out = 5时([1 5] 9)
* 当out = 6时([2 6])
* 当out = 7时([3 7])
* 当out = 8时([0 4 8])
* 当out = 9时([1 5 9])
* h = 4执行完毕,然后h = (h - 1) / 3 = 1开始新的for循环
* h = 1时执行过程和h = 4时一样,不过这时的子数列就是原始的数列,蜕变为一个简单的插入排序,这是数组基本有序,数据项移动次数会大大减少
*
*/
for(out = h; out < len; out++){ // 外层通过out确定每组插入排序的第二个数据项
// 以下代码就是对子序列进行的插入排序算法
tmp = array[out];
in = out;
/*
* 比较插入排序while循环的写法,这里的while循环与h有关,所以判定就与h有关,包括 in -= h语句
* while(in > 0 && array[in - 1] > tmp){
* array[in] = array[in - 1];
* in--;
* }
* array[in] = tmp;
*
*/
while(in > h -1 && array[in - h] >= tmp){
array[in] = array[in - h];
in -= h;
}
array[in] = tmp;
// for(int i = 0; i < len; i++)
// System.out.print(array[i] + " ");
// System.out.println();
}
// 缩小间隔
h = (h - 1) / 3;
}
}
}