原文:http://kate-butenko.blogspot.tw/2012/07/investigating-issues-with-unmanaged.html
I want to write this blogpost really fast, until I forget everything, despite I have absolutely no time and need to work on other cases :( Let's count this as part of my work, okay?
Prologue.
You can scroll it down to scene 1, if you want to concentrate on concrete steps.
This case had a long story - starting from OOM troubles on 32-bit process, when process 32-bit mode was considered as main boundary for a large solution. BTW, my troubles with opening dumps at that point resulted in this blog post, if you remember it.
After switching to 64bit solution was running smoothly for some time, we even closed the support case. Suddenly (oh, I love this word!) our poor process had eaten 66Gb of memory, which is unbelievably huge. Actually, it was all of the memory available - 16Gb of RAM and 50Gb of page file.
Customer managed to gather a dump when process memory usage was at something like 6Gb. I was almost sure, that issue solution is struggling because of was this bad guy - Lucene analyzer. Luckily, we have script that counts all related to this issue data structures (and also counts cache sizes), so I thought that I will just run this script on the dump and confirm my assumptions.
I was a bit shocked when script has shown only 140Mb of Lucene-related things in memory. Cache sizes were in healthy range. So this is something new. I loaded our good old friend WinDBG and started analyzing memory as usually.
Scene 1.
1. !dumpheap -stat. One suspicious thing that I noticed in the dumpheap was that largest memory eater was not that large:

Approximate size of strings is ~775mb, and a lot of Free objects were telling me that a lot of memory is not compacted. Other objects are related to different Sitecore caches.
But what even 1.7Gb means against having a ~5.8Gb dump? That was a question.
2.!address -summary. This command will output all memory usage for the process. Managed, unmanaged, commited, available virtual memory - whatever you can imagine:

Ok, that's a bit better. At least I can see that there is ~5.5Gb of committed memory (MEM_COMMIT), which corresponds approximately to process' Private Bytes, so size of dump is not coming from nowhere. But from somewhere.
3. !eeheap -gc. This nice command shows us all our managed heaps one by one, and for each heap shows its Small object heap and Large object heap addresses and sizes.
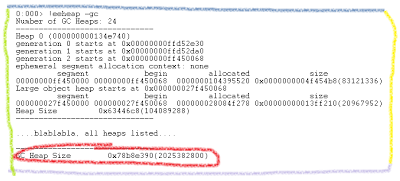
That's what I was interested in - total size of managed memory heap. Sadly, it says that GC heap is only 2Gb it size - the same that we may assume from !dumpheap results. If it was not this case, we can take more from output of !eeheap -gc, for example search for largest LOH, take a look at sizes of generations in GC and possibly derive something useful.
But commited memory 5.5Gb against 2Gb of GC managed memory shows us that we face this scary unmanaged memory thing. Oh no :(
I searched through ton of sites looking for concrete steps of debugging such issues in WinDBG. Steps below are currently the one and only scenario, that worked for me. I'm sure that there are much more possible ways of solving, but we are not able to know everything in this world, aren't we?
Scene 2.
So later in this article we are investigating our native heaps. Native means unmanaged - our GC has nothing to do with native memory, it will never be collected or compacted until application is closed and everything that belongs to it is freed.
4. !heap -s

Let's look at the native heaps. One of the heaps takes ~3Gb. So this is the place where most part of our lost memory goes! Remember this heap number 12240000. We'll see it again later.
Now let's take a closer look at the structure of native heaps, using following command:
5. !heap -stat -h 0

Among all allocation statistic information for all heaps find the ones that are the most exhausted. It means that most of total busy bytes is close to 100. In my dump I had several such heaps, but most of them aren't causing problems, according to results of step 4. This 12240000 is under big question now.
From the output above we can also see that all this heap is filled with blocks of equal size - 7c10. Next command will allow us filter heaps to find blocks of this only size.
6. !heap -flt s 7c10

Good explanation of each of the columns: http://stackoverflow.com/questions/6687414/what-do-the-different-columns-in-the-heap-flt-s-xxxx-windbg-command-represe
Now be careful. Most of the sites and guides on the Internet will now offer you to go through UserPtrs and look at the stacks that are pointing to this UserPtrs. For example, this one: http://windbg.info/doc/1-common-cmds.html#20_memory_heap, scroll down to "Finding memory leaks", steps 5-8. I recognize that this scenario may be useful sometimes, but nobody says that in 90% of cases stacks are not present there :)
First my thought was that I have nothing else to admit except of the fact that I'm stuck here. Searching for anything related leaded me to the steps like in article above, but this scenario was of no use. I even asked my other experienced colleagues and US support about any ideas, but seems that nobody have ever seen this before.
Occasionaly, while hopelessly searching for just general information on native memory leaks, I bumped into a simple blog post http://www.manicai.net/comp/debugging/oom/. Man, I should give you all the credit for this post, as you saved my head from explosion.
Frankly saying, I wasn't able to repeat all the steps from the blog above, but even the beginning has given me a chance to find out what is wrong.
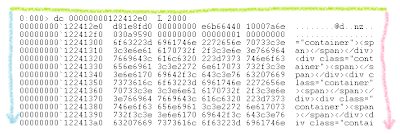
7. dc 00000000122412e0 L 2000
Address is taken as the first HEAP_ENTRY from previous screenshot - address of first block of that size. "dc" command display us raw memory in double word bytes and ASCII characters corresponding to them. L 2000 means that we will take 2000 of these double words.
We will get a large output, scroll over it and find interesting places, if you have them:
 beginning of the "dc" output
beginning of the "dc" output
Cool. There is definitely some repeating string, like <div class="container"><span></span></div>... and this string is being repeated forever.
 somewhere in the middle of the "dc" output
somewhere in the middle of the "dc" output
Another eye-catching place. Among all these repeating spans some piece of the content is jumping into: Fredagsklumme-Faellesskab-og-ho... and some styling before this content.
 end of dots-range in "dc"-output
end of dots-range in "dc"-output
Then our content piece is followed by a lot of dots and ends up with all this div-span thing again.
Actually, it was the brilliant moment - find some meaningful strings in all this garbage-looking native heap.
My next step was just to ask customer about nature of this string, and he has successfully found something similar in their XSLT files and found related content in one of the Sitecore fields. Most of all, this memory leak was caused by incorrect parsing some content markup by this xslt.
Epilogue.
...and the moral of this story:
Guys, please keep posting! Especially about the things that are not that obvious and that you spent a lot of time on.




