作业说明详见:http://www.cnblogs.com/jiel/p/3978727.html
1.安装Microsoft Visual Studio Ultimate 2012,之前安装过一次,预计2小时左右,但是安装过程中可以继续进行其它任务。
2.阅读题目要求,理解要实现的功能,预计20min左右。
3.根据题目,设计程序框架,预计10min左右。
4.阅读相关文档,学习所需要的类的命名空间,属性和方法,预计1小时左右。
5.初步完成程序编写,预计3小时左右。
6.设计测试数据,对出现的Bug进行改进,预计2小时左右。
1.安装Microsoft Visual Studio Ultimate 2012,网址如下:
http://www.microsoft.com/zh-cn/download/confirmation.aspx?id=30678
网速较快用时1小时。
2.阅读题目要求,理解要实现的功能:实现一个文本词频统计器,可以实现统计单词数目,2联短语数目,3联短语数目。单词比较忽略大小写,输出时按照词频从大到小排序,相等时按字典序排序,用时15min。
3.根据题目,设计程序框架,完善代码:(用时大约4小时)
(1)根据读入目录路径,获取目录子文件:
1 String[] files = Directory.GetFiles(path);View Code
(2)读取每个文件的内容:

1 foreach (String i in files) 2 { 3 String extension = i.Substring(i.LastIndexOf(".")+1, i.Length - i.LastIndexOf(".")-1); 4 if (!extension.Equals("txt") && 5 !extension.Equals("cpp") && 6 !extension.Equals("h") && 7 !extension.Equals("cs")) continue;//只处理特定格式的文件 8 if (i.Equals(path+"\\"+"12061162.txt")) continue; 9 String[] text = rgxwords.Split(File.ReadAllText(i)); 10 }View Code
(3)对于获取的文本信息整理:先将文本拆分成若干行或者句子,设定三个Regex类,分别匹配单个单词,2两个由单个空格隔开的单词,3个由单个单词隔开的单词。调用Regex.Match()方法和Regex.NextMatch方法匹配所有可匹配项:
数据存放数组定义如下:
1 ArrayList data = new ArrayList();//当前小说的单词数据 2 ArrayList word_word = new ArrayList();//e2模式短语的数据 3 ArrayList word_word_word = new ArrayList();//e3模式短语的数据View Code
模板定义如下:
1 Regex rgxwords = new Regex("[\n\r,.\\(\\)\\{\\}\\{\\]:\"!;]+");//将文本拆分成一句或一行一个 2 Regex regword1 = new Regex("[a-zA-Z]{3}[0-9a-zA-Z]*");//Simple mode的模式 3 Regex regword2 = new Regex("[a-zA-Z]{3}[0-9a-zA-Z]* [a-zA-Z]{3}[0-9a-zA-Z]*");//Extended mode2的模式 4 Regex regword3 = new Regex("[a-zA-Z]{3}[0-9a-zA-Z]* [a-zA-Z]{3}[0-9a-zA-Z]* [a-zA-Z]{3}[0-9a-zA-Z]*");//Extended mode3的模式View Code
具体过程如下:
1 Match match = regword1.Match(text[j], 0); 2 while (match.Success) 3 { 4 data.Add(new Data(match.Value, 1));//simple mode的数据更新 5 match = match.NextMatch(); 6 } 7 Match match2 = regword2.Match(text[j], 0); 8 Match match1 = regword1.Match(text[j],match2.Index); 9 while (match2.Success) 10 { 11 word_word.Add(new Data(match2.Value, 1)); 12 match2 = regword2.Match(text[j], match1.Index+1); 13 match1 = match1.NextMatch(); 14 }//extend mode2的数据更新 15 match2 = regword3.Match(text[j], 0); 16 match1 = regword1.Match(text[j],match2.Index); 17 while (match2.Success) 18 { 19 word_word_word.Add(new Data(match2.Value, 1)); 20 match2 = regword3.Match(text[j], match1.Index + 1); 21 match1 = match1.NextMatch(); 22 }//extend mode3的数据更新View Code
(4)对于存取数据的ArrayList类整理排序:主要运用ArrayList.sort(IComparer)方法,需要自己实现IComparer接口。
1 class myReverserClass1 : IComparer 2 //自定义比较器,用于字典序排序 3 { 4 int MyStringCompare(String x, String y) 5 //自定义了字符串比较方法: 6 //忽略大小写排序,但是大写相对靠前 7 //如hello,world,World,zoo 8 //排序后变成hello,World,world,zoo 9 { 10 int lx = x.Count(), ly = y.Count(), i; 11 String xx = x.ToUpper(); 12 String yy = y.ToUpper(); 13 for (i = 0; i < lx && i < ly; i++) 14 if (xx[i] == yy[i]) continue; 15 else return xx[i] - yy[i]; 16 if (i == lx && i < ly) return -1; 17 else if (i < lx && i == ly) return 1; 18 else 19 { 20 for (i = 0; i < lx && i < ly; i++) 21 if (x[i] == y[i]) continue; 22 else return y[i] - x[i]; 23 return 0; 24 } 25 } 26 int IComparer.Compare(Object x, Object y) 27 { 28 return MyStringCompare(((Data)y).word, ((Data)x).word); 29 } 30 } 31 class myReverserClass2 : IComparer 32 //自定义比较器,用于单词频率排序 33 { 34 int MyStringCompare(String x, String y) 35 //自定义了字符串比较方法: 36 //忽略大小写排序,但是大写相对靠前 37 //如hello,world,World,zoo 38 //排序后变成hello,World,world,zoo 39 { 40 int lx = x.Count(), ly = y.Count(), i; 41 String xx = x.ToUpper(); 42 String yy = y.ToUpper(); 43 for (i = 0; i < lx && i < ly; i++) 44 if (xx[i] == yy[i]) continue; 45 else return xx[i] - yy[i]; 46 if (i == lx && i < ly) return -1; 47 else if (i < lx && i == ly) return 1; 48 else 49 { 50 for (i = 0; i < lx && i < ly; i++) 51 if (x[i] == y[i]) continue; 52 else return y[i] - x[i]; 53 return 0; 54 } 55 } 56 int IComparer.Compare(Object x, Object y) 57 { 58 if (((Data)x).num > ((Data)y).num) return -1; 59 else if (((Data)x).num < ((Data)y).num) return 1; 60 else return MyStringCompare(((Data)x).word, ((Data)y).word); 61 } 62 }View Code
设计相关方法去掉重复单词,记录次数:
1 static ArrayList Redelete(ArrayList array) 2 //删掉重复出现的单词,并统计出现次数 3 { 4 IComparer myComparer1 = new myReverserClass1(); 5 array.Sort(myComparer1); 6 for (int i = 0; i < array.Count - 1; i++) 7 { 8 9 Data now = (Data)array[i]; 10 Data nxt = (Data)array[i + 1]; 11 now.word = now.word.ToUpper(); 12 nxt.word = nxt.word.ToUpper(); 13 if (now.word.Equals(nxt.word) == true) 14 { 15 array.RemoveAt(i + 1); 16 Data temp = (Data)array[i]; 17 temp.num++; 18 array[i] = temp; 19 i--; 20 } 21 } 22 return array; 23 } 24 static ArrayList Resort(ArrayList array) 25 //按频率排序 26 { 27 IComparer myComparer2 = new myReverserClass2(); 28 array.Sort(myComparer2); 29 return array; 30 }View Code
(5)对数据调用自定义的Redelete方法和Resort方法,并输出结构到指定文件下
1 static StreamWriter writer;View Code
1 writer = new StreamWriter(dirpath + "\\" + "12061162.txt");View Code
1 data = Resort(Redelete(data)); 2 word_word = Resort(Redelete(word_word)); 3 word_word_word = Resort(Redelete(word_word_word)); 4 try 5 { 6 writer.WriteLine("文件地址:" + i); 7 writer.WriteLine("最常见2联短语:"); 8 if (word_word.Count != 0) 9 for (int j = 0; j < Math.Min(word_word.Count,10); j++) 10 writer.WriteLine(((Data)word_word[j]).word); 11 else writer.WriteLine("不存在"); 12 writer.WriteLine("最常见3联短语:"); 13 if (word_word_word.Count != 0) 14 for (int j = 0; j < Math.Min(word_word_word.Count, 10); j++) 15 writer.WriteLine(((Data)word_word_word[j]).word); 16 else writer.WriteLine("不存在"); 17 writer.WriteLine("所有单词如下:"); 18 foreach (Data j in data) 19 writer.WriteLine(j.word + "------" + j.num); 20 } 21 catch (UnauthorizedAccessException e) 22 { 23 Console.WriteLine(e.ToString()); 24 }View Code
4.设计数据,数据如下:
http://pan.baidu.com/s/1mgyYOTM虽然排序用了ArrayList.Sort()方法,但是删除重复时用了ArrayList.RemoveAt()方法,最坏可能是N^2的复杂度,这导致了算法复杂度极大升高,后来看了才意识到。可以调用Dictionary类,减少运行时间。改进代码如下:(课程网站提交的是源代码,想改时发现错过提交时间了)
1 static ArrayList Redelete(ArrayList array) 2 //删掉重复出现的单词,并统计出现次数 3 { 4 IComparer myComparer1 = new myReverserClass1(); 5 array.Sort(myComparer1); 6 Dictionary<String,int> map = new Dictionary<String,int>(); 7 for (int i = 0; i < array.Count ; i++) 8 { 9 10 Data now = (Data)array[i]; 11 map.Add(now.word,1); 12 if (i == array.Count - 1) break; 13 Data nxt = (Data)array[i + 1]; 14 String temp = now.word.ToUpper(); 15 nxt.word = nxt.word.ToUpper(); 16 while (temp.Equals(nxt.word) == true) 17 { 18 map[now.word]++; 19 i++; 20 if (i + 1 == array.Count) break; 21 nxt = (Data)array[i+1]; 22 nxt.word = nxt.word.ToUpper(); 23 } 24 } 25 array = new ArrayList(); 26 foreach (KeyValuePair<String,int> kvp in map) 27 array.Add(new Data(kvp.Key, kvp.Value)); 28 return array; 29 }View Code
这组数据在改进前无法运行
改进后运行状态为:
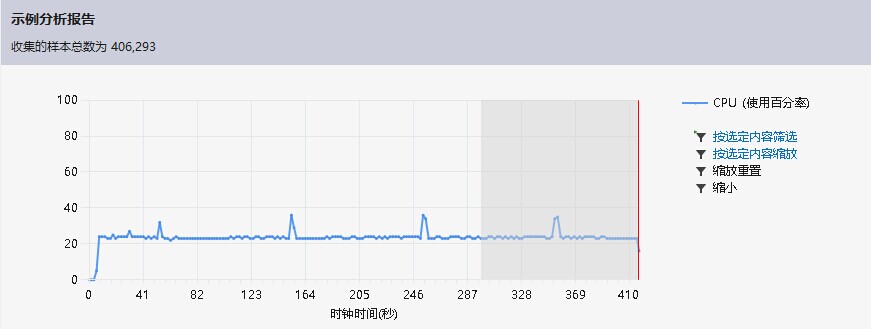
虽然也很慢,而且cpu运行有时比较高,但是可以出结果了,之前的40min也没出结果。
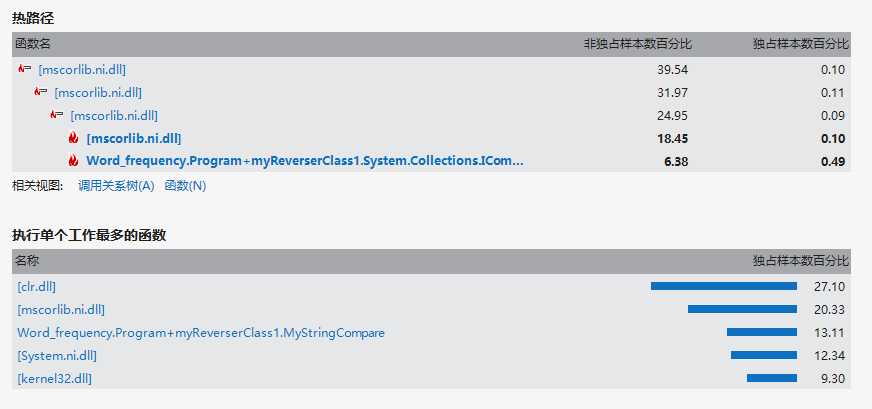
从上面看出,我的代码主要运行时间在IComparer比较上,排序时的比较总会调用MyStringCompare,比较一次,调用一次。故占用浪费时间较大。
因代码编写匆忙,故时间主要花费在实现功能上,而忽略了性能。
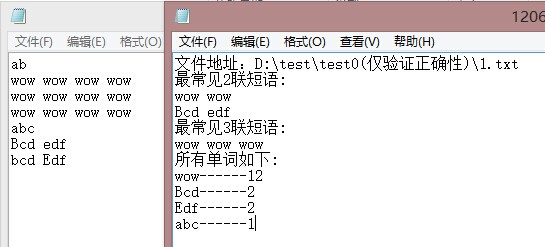
此数据可看出,可以显现扫面三联词汇,二连词汇,统计所有单词词频,可以忽略大小写。故程序正确性无误。
虽然不是第一次写C#程序了,但是完成这次作业后才发现,自己C#知识不足,写出的代码风格接近java,对C#特有的一些知识没有掌握。而且前期投入时间不足,导致后期忙于赶任务,完成的不是很好,性能不够快,代码全写在主类中,全是静态方法,风格不是很好。希望这次也给自己一个教训,总结经验,更好地完成下一次作业!