JVM������⣺http://www.cnb
logs.com/redcreen/archive/2011/05/04/2037057.html
Java������У��������Ϳ��Է�Ϊ���ࣺ�������ͺ��������͡��������͵ı�������ԭʼֵ��������������ֵ������ֵ���������������͵ı�����������ֵ��������ֵ��������ij����������ã������Ƕ�������������������������ֵ����ʾ�ĵ�ַ��λ�á�
�������Ͱ�����byte,short,int,long,char,float,double,Boolean,returnAddress
�������Ͱ����������ͣ�
�ӿ����ͺ����顣
����ջ
�Ѻ�ջ�dz������еĹؼ������б�Ҫ��
�����Ĺ�ϵ˵�����
ջ������ʱ�ĵ�λ�������Ǵ洢�ĵ�λ��
ջ���������������⣬���������ִ�У�����˵��
�δ������ݣ��ѽ���������ݴ洢�����⣬��������ô�š������Ķ���
��Java��һ��
�߳��ͻ���Ӧ��һ���߳�ջ��֮��Ӧ����������
��������Ϊ��ͬ���߳�ִ����������ͬ�������Ҫһ���������߳�ջ���������������̹߳����ġ�ջ��Ϊ�����е�λ���������洢����Ϣ���Ǹ���ǰ�̣߳�����������Ϣ�ġ������ֲ���������������״̬����������ֵ�ȵȣ�����ֻ����洢������Ϣ��
ΪʲôҪ�ѶѺ�ջ���ֳ����أ�ջ�в���Ҳ���Դ洢������
��һ����������ƵĽǶȿ���ջ�����˴����������Ѵ��������ݡ������ֿ���ʹ�ô�������Ϊ�������ֶ���֮��˼�롣���ָ��롢ģ�黯��˼����������Ƶķ������涼�����֡�
�ڶ�������ջ�ķ��룬ʹ�ö��е����ݿ��Ա����ջ������Ҳ��������Ϊ����̷߳���ͬһ���������ֹ����������Ǻܶ�ġ�һ�������ֹ����ṩ��һ����Ч�����ݽ�����ʽ(�磺����
�ڴ�)����һ���棬���еĹ��������ͻ�����Ա�����ջ���ʣ���ʡ�˿ռ䡣
������ջ��Ϊ����ʱ����Ҫ�����籣��ϵͳ���е������ģ���Ҫ���е�ַ�εĻ��֡�����ջֻ��������������˾ͻ�
����סջ�洢���ݵ����������Ѳ�ͬ�����еĶ����ǿ��Ը�����Ҫ��̬�����ģ����ջ�ͶѵIJ�֣�ʹ�ö�̬������Ϊ���ܣ���Ӧջ��ֻ���¼���е�һ����ַ���ɡ�
���ģ����������ǶѺ�ջ������
�������ʵ���������ʽ�ij�������ǰ�ṹ���ij�����ִ����û���κ����𡣵��ǣ������������룬ʹ�öԴ������˼����ʽ�����˸ı䣬�����ӽ�����Ȼ��ʽ��˼���������ǰѶ�������
�����������������ʵ�������ݣ�����ڶ��У����������Ϊ��������������������������ջ�С������ڱ�д�����ʱ����ʵ����д�����ݽṹ��Ҳ��д�Ĵ������ݵ��������ò����ϣ�����������ƣ�ȷʵ������
��Java�У�Main��������ջ����ʼ�㣬Ҳ�dz������ʼ�㡣
����Ҫ����������һ�����ġ�ͬC����һ����java�е�Main�����Ǹ���㡣����ʲôjava�����ҵ�main���ҵ��˳���ִ�е���ڣ���
���д�ʲô��ջ�д�ʲô��
���д���Ƕ���ջ�д���ǻ����������ͺͶ��ж�������á�һ������Ĵ�С�Dz��ɹ��Ƶģ�����˵�ǿ��Զ�̬�仯�ģ�������ջ�У�һ������ֻ��Ӧ��һ��4btye�����ã�
��ջ����ĺô���������
Ϊʲô���ѻ������ͷŶ����أ���Ϊ��ռ�õĿռ�һ����1~8���ֽڡ�����Ҫ�ռ�Ƚ��٣�������Ϊ�ǻ������ͣ����Բ�����ֶ�̬����������������ȹ̶������ջ�д洢���ˣ�����������ڶ�����û��ʲô
�����ģ������˷ѿռ䣬����˵������������ô˵���������ͺͶ�������ö��Ǵ����ջ�У����Ҷ��Ǽ����ֽڵ�һ����������ڳ�������ʱ�����ǵĴ�����ʽ��ͳһ�ġ����ǻ������͡��������úͶ����������������ˣ���Ϊһ����ջ�е�����һ���Ƕ��е����ݡ������һ��������ǣ�Java�в�������ʱ�����⡣
Java�еIJ�������ʱ��ֵ�أ����Ǵ����ã�
Ҫ˵��������⣬��Ҫ��ȷ���㣺
1. ��Ҫ��ͼ��C������ȣ�Java��û��ָ��ĸ���
2. ����������Զ������ջ�н��еģ������������ʱ��ֻ���ڴ��ݻ������ͺͶ������õ����⡣����ֱ�Ӵ���������
��ȷ���������Java�ڷ������ô��ݲ���ʱ����Ϊû��ָ�룬���������ǽ��д�ֵ���ã������Բο�C�Ĵ�ֵ���ã�����ˣ��ܶ������涼˵Java�ǽ��д�ֵ���ã����û�����⣬����Ҳ��C�и����ԡ�
���Ǵ����õĴ����������ɵ��أ�������ջ�У��������ͺ����õĴ�����һ���ģ����Ǵ�ֵ�����ԣ�����Ǵ����õķ������ã�Ҳͬʱ��������Ϊ��������ֵ���Ĵ�ֵ���ã������õĴ�����������������ȫһ���ġ����ǵ����뱻���÷���ʱ�������ݵ�������õ�ֵ����������ͣ����߲��ң������еĶ������ʱ��Ŷ�Ӧ�������Ķ��������ʱ�����ģ��ĵ������ö�Ӧ�Ķ����������ñ����������ĵ��Ƕ��е����ݡ�����������ǿ��Ա��ֵ��ˡ�
����ij��������˵�����ɻ���������ɵġ�����һ��������Ϊһ���������������������Ƕ�������һ����������Ҷ�ӽڵ㣩������������Ϊ����Ҷ�ӽڵ㡣�����������ʱ�������ݵ�ֵ�������Dz��ܽ����ĵģ����ǣ�������ֵ��һ����Ҷ�ӽڵ㣨��һ���������ã��������������ڵ�������������ݡ�
�Ѻ�ջ�У�ջ�dz�������������Ķ������������п���û�жѣ����Dz���û��ջ��������Ϊջ�������ݴ洢����˵���˶Ѿ���һ�鹲�����ڴ档������������Ϊ�Ѻ�ջ�ķ����˼�룬��ʹ��Java���������ճ�Ϊ���ܡ�
Java�У�ջ�Ĵ�Сͨ��-Xss�����ã���ջ�д洢���ݱȽ϶�ʱ����Ҫ�ʵ��������ֵ����������java.lang.StackOverflowError
�쳣�������ij�������쳣���������ص�
�ݹ�����Ϊ��ʱջ�б������Ϣ���Ƿ������صļ�¼�㡣
Java����Ĵ�С
�������ݵ����͵Ĵ�С�ǹ̶��ģ�����Ͳ���˵�ˡ����ڷǻ������͵�Java�������С��ֵ����ȶ��
��Java�У�һ����Object����Ĵ�С��8byte�������Сֻ�DZ������һ��û���κ����ԵĶ���Ĵ�С����������䣺
Object ob = new Object();
�����ڳ����������һ��Java�������������������ռ�Ŀռ�Ϊ��4byte+8byte��4byte�����沿����˵��Javaջ�б������õ�����Ҫ�Ŀռ䡣����8byte����Java���ж������Ϣ����Ϊ���е�Java�ǻ������͵Ķ�����ҪĬ�ϼ̳�Object������˲���
ʲô����Java�������С�������Ǵ���8byte��
����Object����Ĵ�С�����ǾͿ��Լ�����������Ĵ�С�ˡ�
Class NewObject {
int count;
boolean flag;
Object ob;
}
���СΪ���ն����С(8byte)+int��С(4byte)+Boolean��С(1byte)+��Object���õĴ�С(4byte)=17byte��������ΪJava�ڶԶ���
�ڴ����ʱ������8�����������֣���˴���17byte����ӽ�8������������24����˴˶���Ĵ�СΪ24byte��
������Ҫע��һ�»������͵İ�װ���͵Ĵ�С����Ϊ���ְ�װ�����Ѿ���Ϊ�����ˣ������Ҫ��������Ϊ��������������װ���͵Ĵ�С������12byte������һ����Object������Ҫ�Ŀռ䣩������12byteû�а����κ���Ч��Ϣ��ͬʱ����ΪJava�����С��8�������������һ���������Ͱ�װ��Ĵ�С������16byte������ڴ�ռ���Ǻֲܿ��ģ�����ʹ�û������͵�N����N>2������Щ���͵��ڴ�ռ�ø��ǿ��ţ�������¾�֪���ˣ�����ˣ����ܵĻ�Ӧ������ʹ�ð�װ�ࡣ��JDK5.0�Ժ���Ϊ������
�Զ�����װ������ˣ�Java��������ڴ洢���������Ӧ���Ż���
��������
�����������ͷ�Ϊǿ���á������á������ú������á�
ǿ����:��������һ������������ʱ��������ɵ����ã�ǿ���û����£���������ʱ��Ҫ�ϸ��жϵ�ǰ�����Ƿ�ǿ���ã������ǿ���ã��ᱻ��������
������:������һ�㱻��Ϊ������ʹ�á���ǿ���õ������ǣ�����������������ʱ�����������ݵ�ǰϵͳ��ʣ���ڴ��������Ƿ�������ý��л��ա����ʣ���ڴ�ȽϽ��ţ������������������������õĿռ䣻���ʣ���ڴ���Ը�ԣ������л��ա����仰˵��������ڷ���OutOfMemoryʱ���϶���û�������ô��ڵġ�
������:�����������������ƣ�������Ϊ������ʹ�á����������ò�ͬ���������ڽ�����������ʱ����һ���ᱻ���յ��ģ��������������ֻ������һ���������������ڡ�
ǿ���ò���˵������ϵͳһ����ʹ��ʱ�����õ�ǿ���á����������á��͡������á��Ƚ��ټ�������һ�㱻��Ϊ����ʹ�ã�����һ�������ڴ��С�Ƚ������������Ϊ���档��Ϊ����ڴ��㹻��Ļ�������ֱ��ʹ��ǿ������Ϊ���漴�ɣ�ͬʱ�ɿ��Ը��ߡ���������dz������DZ�ʹ��������Ӧ��ϵͳ�Ļ��档
���ԴӲ�ͬ�ĵĽǶ�ȥ������������
�㷨��
���ջ������ղ��Է�
���ü�����Reference Counting��:
�ȽϹ��ϵĻ����㷨��ԭ���Ǵ˶�����һ�����ã�������һ��������ɾ��һ�����������һ����������������ʱ��ֻ���ռ�����Ϊ0�Ķ����㷨����������������
ѭ�����õ����⡣
���-�����Mark-Sweep��:
���㷨ִ�з����Ρ���һ�δ����ø��ڵ㿪ʼ������б����õĶ��ڶ��α��������ѣ���δ��ǵĶ�����������㷨��Ҫ��ͣ����Ӧ�ã�ͬʱ��������ڴ���Ƭ��
���ƣ�Copying��:
���㷨���ڴ�ռ仮Ϊ������ȵ�����ÿ��ֻʹ������һ��������������ʱ��������ǰʹ����������ʹ���еĶ����Ƶ�����һ�������С����㷨ÿ��ֻ��������ʹ���еĶ�����˸��Ƴɱ��Ƚ�С��ͬʱ���ƹ�ȥ�Ժ��ܽ�����Ӧ���ڴ�������������֡���Ƭ�����⡣��Ȼ�����㷨��ȱ��Ҳ�Ǻ����Եģ�������Ҫ�����ڴ�ռ䡣
���-������Mark-Compact��:
���㷨����ˡ����-������͡����ơ������㷨���ŵ㡣Ҳ�Ƿ����Σ���һ�δӸ��ڵ㿪ʼ������б����ö��ڶ��α��������ѣ������δ��Ƕ����ҰѴ�����ѹ�������ѵ�����һ�飬��˳���ŷš����㷨�����ˡ����-���������Ƭ���⣬ͬʱҲ�����ˡ����ơ��㷨�Ŀռ����⡣
�������Դ��ķ�ʽ��
�����ռ���Incremental Collecting��:ʵʱ���������㷨��������Ӧ�ý��е�ͬʱ�����������ա���֪��ʲôԭ��JDK5.0�е��ռ���û��ʹ�������㷨�ġ�
�ִ��ռ���Generational Collecting��:���ڶԶ����������ڷ�����ó������������㷨���Ѷ����Ϊ����������ϴ����־ô����Բ�ͬ�������ڵĶ���ʹ�ò�ͬ���㷨��������ʽ�е�һ�������л��ա����ڵ���������������J2SE1.2��ʼ������ʹ�ô��㷨�ġ�
��ϵͳ�̷߳�
�����ռ�:�����ռ�ʹ�õ��̴߳��������������չ�������Ϊ�����
�߳̽�����ʵ�����ף�����Ч�ʱȽϸߡ����ǣ��������Ҳ�Ƚ����ԣ�����ʹ�ö�
�����������ƣ����Դ��ռ��ʺϵ���������������Ȼ�����ռ���Ҳ��������С��������100M���ң�����µĶദ���������ϡ�
�����ռ�:�����ռ�ʹ�ö��̴߳����������չ���������ٶȿ죬Ч�ʸߡ�����������CPU��ĿԽ�࣬Խ�����ֳ������ռ��������ơ�
�����ռ�:����ڴ����ռ��Ͳ����ռ����ԣ�ǰ�������ڽ����������չ���ʱ����Ҫ��ͣ�������л�������ֻ���������ճ��������У���ˣ�ϵͳ����������ʱ�������Ե���ͣ��������ͣʱ�����Ϊ��Խ���Խ����
�����������
����˵���ġ����ü���������ͨ��ͳ�ƿ������ɶ����ɾ������ʱ�����������жϡ��������ճ����ռ�����Ϊ0�Ķ��ɡ��������ַ��������ѭ�����á����ԣ�����ʵ�ֵ������ж��㷨�У����Ǵӳ������еĸ��ڵ���������������������ã����Ҵ��Ķ�����ô�����ַ�ʽ��ʵ���У��������մ��Ķ���ʼ���أ��������Ķ���ʼ������Щ���������ڱ���ǰϵͳʹ�õġ���������ĶѺ�ջ����������ջ���������г���ִ�еط�������Ҫ��ȡ��Щ�������ڱ�ʹ�ã�����Ҫ��Javaջ��ʼ��ͬʱ��һ��ջ����һ���̶߳�Ӧ�ģ���ˣ�����ж���̵߳Ļ�����������Щ�̶߳�Ӧ�����е�ջ���м�顣
ͬʱ������ջ�⣬����ϵͳ����ʱ�ļĴ����ȣ�Ҳ�Ǵ洢�����������ݵġ���������ջ��Ĵ����е�����Ϊ��㣬���ǿ����ҵ����еĶ����ִ���Щ�����ҵ��Զ���������������ã�������������չ��������null���û��������ͽ������������γ���һ����Javaջ����������Ӧ�Ķ���Ϊ���ڵ��һ�Ŷ����������ջ���ж�����ã������ջ��γɶ�Ŷ�����������Щ�������ϵĶ����ǵ�ǰϵͳ��������Ҫ�Ķ����ܱ��������ա�������ʣ������������Ϊ�������õ��Ķ����Ա������������л��ա�
��ˣ��������յ������һЩ������javaջ, ��̬����, �Ĵ���...���������Javaջ����Java����ִ�е�main���������ֻ��շ�ʽ��Ҳ�������ᵽ�ġ����-������Ļ��շ�ʽ
��δ�����Ƭ
���ڲ�ͬJava������ʱ���Dz�һ���ģ���ˣ��ڳ�������һ��ʱ���Ժ�����������ڴ��������ͻ������ɢ���ڴ���Ƭ����Ƭ��ֱ�ӵ�������ǻᵼ������������ڴ�ռ䣬�Լ���������Ч�ʽ��͡����ԣ��������ᵽ�Ļ������������㷨�У������ơ���ʽ�͡����-��������ʽ�������Խ����Ƭ�����⡣
��ν��ͬʱ���ڵĶ����Ͷ����������
���������߳��ǻ����ڴ�ģ������������߳��������ģ�����䣩�ڴ�ģ�һ�������ڴ棬һ�������ڴ棬����㿴��������ì�ܵġ���ˣ������е��������շ�ʽ�У�Ҫ������������ǰ��һ�㶼��Ҫ��ͣ����Ӧ�ã�������ͣ�ڴ�ķ��䣩��Ȼ������������գ�������ɺ��ټ���Ӧ�á�����ʵ�ַ�ʽ����ֱ�ӣ�����
����Ч�Ľ������ì�ܵķ�ʽ��
�������ַ�ʽ��һ�������Եıˣ����ǵ��ѿռ��������ʱ���������յ�ʱ��Ҳ������Ӧ�ij�������ӦӦ����ͣ��ʱ��Ҳ����Ӧ������һЩ����Ӧʱ��Ҫ��ܸߵ�Ӧ�ã����������ͣʱ��Ҫ���Ǽ��ٺ��룬��ô���ѿռ���ڼ���Gʱ���ͺ��п��ܳ���������ƣ�����������£��������ս����Ϊϵͳ���е�һ��ƿ����Ϊ�������ì�ܣ����˲������������㷨��ʹ�������㷨�����������߳�����������߳�ͬʱ���С������ַ�ʽ�£��������ͣ�����⣬������Ϊ��Ҫ�������ɶ����ͬʱ��Ҫ���ն����㷨�����Ի������ӣ�ϵͳ�Ĵ�������Ҳ����Ӧ���ͣ�ͬʱ������Ƭ�����⽫��Ƚ��ѽ����
ΪʲôҪ�ִ�
�ִ����������ղ��ԣ��ǻ�������һ����ʵ����ͬ�Ķ�������������Dz�һ���ġ���ˣ���ͬ�������ڵĶ�����Բ�ȡ��ͬ���ռ���ʽ���Ա������Ч�ʡ�
��Java�������еĹ����У�����������Ķ���������Щ��������ҵ����Ϣ��أ�����Http�����е�Session�����̡߳�Socket���ӣ���������ҵ��ֱ�ӹҹ�������������ڱȽϳ������ǻ���һЩ������Ҫ�dz������й��������ɵ���ʱ��������Щ�����������ڻ�Ƚ϶̣����磺String���������䲻��������ԣ�ϵͳ�������������Щ������Щ��������ֻ��һ�μ��ɻ��ա�
���룬�ڲ����ж�����ʱ�����ֵ�����£�ÿ���������ն��Ƕ������ѿռ���л��գ�����ʱ����Ի᳤��ͬʱ����Ϊÿ�λ��ն���Ҫ�������д�����ʵ���ϣ������������ڳ��Ķ�����ԣ����ֱ�����û��Ч���ģ���Ϊ���ܽ����˺ܶ�α����������������ɴ��ڡ���ˣ��ִ��������ղ��÷��ε�˼�룬���д��Ļ��֣��Ѳ�ͬ�������ڵĶ�����ڲ�ͬ���ϣ���ͬ���ϲ������ʺ������������շ�ʽ���л��ա�
��ηִ�
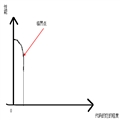
��ͼ��ʾ��
������еĹ�����Ϊ���������������Young Generation�������ϵ㣨Old Generation���ͳ־ô���Permanent Generation�������г־ô���Ҫ��ŵ���Java�������Ϣ���������ռ�Ҫ�ռ���Java�����ϵ��������������ϴ��Ļ����Ƕ������ռ�Ӱ��Ƚϴ�ġ�
�����:
���������ɵĶ������ȶ��Ƿ���������ġ��������Ŀ����Ǿ����ܿ��ٵ��ռ�����Щ�������ڶ̵Ķ������������������һ��Eden��������Survivor��(һ�����)���ֶ�����Eden�������ɡ���Eden����ʱ�������Ķ������Ƶ�Survivor���������е�һ�����������Survivor����ʱ�������Ĵ��������Ƶ�����һ��Survivor���������SurvivorȥҲ���˵�ʱ�ӵ�һ��Survivor�����ƹ����IJ��Ҵ�ʱ�����Ķ��������ơ�������(
Tenured)������Ҫע�⣬Survivor���������ǶԳƵģ�û�Ⱥ��ϵ������ͬһ�����п���ͬʱ���ڴ�Eden���ƹ��� ���ʹ�ǰһ��Survivor���ƹ����Ķ������Ƶ���������ֻ�дӵ�һ��Survivorȥ�����Ķ����ң�Survivor������һ���ǿյġ�ͬʱ�����ݳ�����Ҫ��Survivor���ǿ�������Ϊ����ģ������������������������Ӷ�����������еĴ���ʱ�䣬���ٱ��ŵ����ϴ��Ŀ��ܡ�
���ϴ�:
��������о�����N���������պ���Ȼ���Ķ��ͻᱻ�ŵ����ϴ��С���ˣ�������Ϊ���ϴ��д�ŵĶ���һЩ�������ڽϳ��Ķ���
�־ô�:
���ڴ�ž�̬�ļ������Java�ࡢ�����ȡ��־ô�����������û������Ӱ�죬������ЩӦ�ÿ��ܶ�̬���ɻ��ߵ���һЩ
class������Hibernate�ȣ�������ʱ����Ҫ����һ���Ƚϴ�ij־ô��ռ��������Щ���й������������ࡣ�־ô���Сͨ��-XX:MaxPermSize=<N>�������á�
ʲô����´�����������
���ڶ�������˷ִ����������������������ʱ��Ҳ��һ����GC���������ͣ�Scavenge GC��Full GC��
Scavenge GC
һ������£����¶������ɣ�������Eden����ռ�ʧ��ʱ���ͻᴥ��Scavenge GC����Eden�������GC������Ǵ������Ұ����Ҵ��Ķ����ƶ���Survivor����Ȼ������Survivor�������������ַ�ʽ��GC�Ƕ��������Eden�����У�����Ӱ�쵽���ϴ�����Ϊ�ֶ����Ǵ�Eden����ʼ�ģ�ͬʱEden���������ĺܴ�����Eden����GC��Ƶ�����С������һ����������Ҫʹ���ٶȿ졢Ч�ʸߵ��㷨��ʹEdenȥ�ܾ�����г�����
Full GC
�������ѽ�������������Young��Tenured��Perm��Full GC��Ϊ��Ҫ�������Խ��л��գ����Ա�Scavenge GCҪ�������Ӧ�þ����ܼ���Full GC�Ĵ������ڶ�JVM
�����Ĺ����У��ܴ�һ���ֹ������Ƕ���FullGC�ĵ��ڡ�������ԭ����ܵ���Full GC��
�� ���ϴ���Tenured����д��
�� �־ô���Perm����д��
�� System.gc()����ʾ����
����һ��GC֮��Heap�ĸ��������Զ�̬�仯
�ִ�������������ʾ��
ѡ����ʵ������ռ��㷨
�����ռ���
�õ��̴߳��������������չ�������Ϊ������߳̽���������Ч�ʱȽϸߡ����ǣ�Ҳ��ʹ�öദ���������ƣ����Դ��ռ����ʺϵ���������������Ȼ�����ռ���Ҳ��������С��������100M���ң�����µĶദ���������ϡ�����ʹ��-XX:+UseSerialGC��
�����ռ���
����������в����������գ���˿��Լ�����������ʱ�䡣һ���ڶ��̶߳ദ����������ʹ�á�ʹ��-XX:+UseParallelGC.�������ռ�����J2SE5.0����6���������룬��Java SE6.0�н�������ǿ--���Զ����ϴ����в����ռ���������ϴ���ʹ�ò����ռ��Ļ���Ĭ����ʹ�õ��߳̽����������գ���˻���Լ��չ������ʹ��-XX:+UseParallelOldGC��
ʹ��-XX:ParallelGCThreads=<N>���ò����������յ��߳�������ֵ�������������������������ȡ�
���ռ������Խ����������ã�
�������������ͣ:ָ����������ʱ�����ͣʱ�䣬ͨ��-XX:MaxGCPauseMillis=<N>ָ����<N>Ϊ����.���ָ���˴�ֵ�Ļ����Ѵ�С������������ز�������е����Դﵽָ��ֵ���趨��ֵ���ܻ����Ӧ�õ���������
������:������Ϊ��������ʱ�������������ʱ��ı�ֵ��ͨ��-XX:GCTimeRatio=<N>���趨����ʽΪ1/��1+N�������磬-XX:GCTimeRatio=19ʱ����ʾ5%��ʱ�������������ա�Ĭ�����Ϊ99����1%��ʱ�������������ա�
�����ռ���
���Ա�֤�ֹ������������У�Ӧ�ò�ֹͣ������������ֻ��ͣ���ٵ�ʱ�䣬���ռ����ʺ϶���Ӧʱ��Ҫ��Ƚϸߵ��С����ģӦ�á�ʹ��-XX:+UseConcMarkSweepGC��
�����ռ�����Ҫ�������ϴ�����ͣʱ�䣬����Ӧ�ò�ֹͣ�������ʹ�ö��������������̣߳����ٿɴ������ÿ�����ϴ��������������У����ռ����ڲ����ռ��� �������Ӧ�ý��м�̵���ͣ�����ռ��л�������ͣһ�Ρ�
�ڶ�����ͣ��ȵ�һ���Գ����ڴ˹����ж���߳�ͬʱ�����������չ�����
�����ռ���ʹ�ô������������ݵ�ͣ��ʱ�䡣��һ��N����������ϵͳ�ϣ������ռ�����ʹ��K/N�����ô��������л��գ�һ�������1<=K<=N/4��
��ֻ��һ����������������ʹ�ò����ռ���������Ϊincremental modeģʽҲ�ɻ�ý϶̵�ͣ��ʱ�䡣
����������������Ӧ�����е�ͬʱ�����������գ�������Щ�����������������ս������ʱ����������������ˡ�Floating Garbage������Щ������Ҫ���´�������������ʱ���ܻ��յ������ԣ������ռ���һ����Ҫ20%��Ԥ���ռ�������Щ����������
Concurrent Mode Failure�������ռ�����Ӧ������ʱ�����ռ���������Ҫ��֤�����������յ����ʱ�����㹻�Ŀռ乩����ʹ�ã������������ջ�δ��ɣ��ѿռ������ˡ���������½��ᷢ��������ģʽʧ�ܡ�����ʱ����Ӧ�ý�����ͣ�������������ա�
���������ռ�������Ϊ�����ռ���Ӧ������ʱ�����ռ������Ա��뱣֤�ռ����֮ǰ���㹻���ڴ�ռ乩����ʹ�ã��������֡�Concurrent Mode Failure����ͨ������-XX:
CMSInitiatingOccupancyFraction=<N>ָ�����ж���ʣ���ʱ��ʼִ�в����ռ�
��
���������
--����������������Ƚ�С��100M���ң������������²��Ҷ���Ӧʱ����Ҫ���Ӧ�á�
--ȱ�㣺ֻ������С��Ӧ��
���������
--��������������������и�Ҫ����CPU����Ӧ����Ӧʱ����Ҫ����С�����Ӧ�á���������̨��������ѧ���㡣
--ȱ�㣺�����ռ�������Ӧ����Ӧʱ����ܼӳ�
������������
--���������������Ӧʱ���и�Ҫ����CPU����Ӧ����Ӧʱ���нϸ�Ҫ����С�����Ӧ�á�������Web������/
Ӧ�÷����������Ž��������ɿ���������
����������Ҫ��Էִ����������㷨���ԡ�
�Ѵ�С����
����������úܹؼ�
JVM�����Ѵ�С�����������ƣ���ز���ϵͳ������ģ�ͣ�32-bt����64-bit�����ƣ�ϵͳ�Ŀ��������ڴ����ƣ�ϵͳ�Ŀ��������ڴ����ơ�32λϵͳ�£�һ��������1.5G~2G��64Ϊ����ϵͳ���ڴ������ơ���Windows Server 2003 ϵͳ��3.5G�����ڴ棬JDK5.0�²��ԣ���������Ϊ1478m��
�������ã�
java -Xmx3550m -Xms3550m -Xmn2g �CXss128k
-Xmx3550m������JVM�������ڴ�Ϊ3550M��
-Xms3550m������JVM��ʹ�ڴ�Ϊ3550m����ֵ����������-Xmx��ͬ���Ա���ÿ������������ɺ�JVM���·����ڴ档
-Xmn2g�������������СΪ2G�������Ѵ�С=�������С + ���ϴ���С + �־ô���С���־ô�һ��̶���СΪ64m��������������������С���ϴ���С����ֵ��ϵͳ����Ӱ��ϴ�Sun�ٷ��Ƽ�����Ϊ�����ѵ�3/8��
-Xss128k������ÿ���̵߳Ķ�ջ��С��JDK5.0�Ժ�ÿ���̶߳�ջ��СΪ1M����ǰÿ���̶߳�ջ��СΪ256K������Ӧ�õ��߳������ڴ��С���е���������ͬ�����ڴ��£���С���ֵ�����ɸ�����̡߳����Dz���ϵͳ��һ�������ڵ��߳������������Ƶģ������������ɣ�����ֵ��3000~5000���ҡ�
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:���������������Eden������Survivor���������ϴ��ı�ֵ����ȥ�־ô���������Ϊ4��������������ϴ���ռ��ֵΪ1��4�������ռ������ջ��1/5
-XX:SurvivorRatio=4�������������Eden����Survivor���Ĵ�С��ֵ������Ϊ4��������Survivor����һ��Eden���ı�ֵΪ2:4��һ��Survivor��ռ�����������1/6
-XX:MaxPermSize=16m:���ó־ô���СΪ16m��
-XX:MaxTenuringThreshold=0����������������䡣�������Ϊ0�Ļ����������������Survivor����ֱ�ӽ������ϴ����������ϴ��Ƚ϶��Ӧ�ã��������Ч�ʡ��������ֵ����Ϊһ���ϴ�ֵ����������������Survivor�����ж�θ��ƣ������������Ӷ�����������Ĵ��ʱ�䣬������������������յĸ��ۡ�
������ѡ��
JVM��������ѡ�����ռ����������ռ����������ռ��������Ǵ����ռ���ֻ������С����������������������ѡ����Ҫ��Բ����ռ����Ͳ����ռ�����Ĭ������£�JDK5.0��ǰ����ʹ�ô����ռ����������ʹ�������ռ�����Ҫ������ʱ������Ӧ������JDK5.0�Ժ�JVM����ݵ�ǰϵͳ���ý����жϡ�
���������ȵIJ����ռ���
�����������������ռ�����Ҫ�Ե���һ����������ΪĿ�꣬�����ڿ�ѧ�����ͺ�̨�����ȡ�
�������ã�
java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC��ѡ�������ռ���Ϊ�����ռ����������ý����������Ч�������������£������ʹ�ò����ռ��������ϴ��Ծ�ʹ�ô����ռ���
-XX:ParallelGCThreads=20�����ò����ռ������߳���������ͬʱ���ٸ��߳�һ������������ա���ֵ��������봦������Ŀ��ȡ�
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGC���������ϴ������ռ���ʽΪ�����ռ���JDK6.0֧�ֶ����ϴ������ռ���
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:����ÿ��������������յ��ʱ�䣬����������ʱ�䣬JVM���Զ������������С���������ֵ��
n java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy�����ô�ѡ������ռ������Զ�ѡ�����������С����Ӧ��Survivor���������ԴﵽĿ��ϵͳ�涨�������Ӧʱ������ռ�Ƶ�ʵȣ���ֵ����ʹ�ò����ռ���ʱ��һֱ��
��Ӧʱ�����ȵIJ����ռ���
�����������������ռ�����Ҫ�DZ�֤ϵͳ����Ӧʱ�䣬���������ռ�ʱ��ͣ��ʱ�䡣������Ӧ�÷���������������ȡ�
�������ã�
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC���������ϴ�Ϊ�����ռ�����������������Ժ�-XX:NewRatio=4������ʧЧ�ˣ�ԭ���������ԣ���ʱ�������С�����-Xmn���á�
-XX:+UseParNewGC: ���������Ϊ�����ռ�������CMS�ռ�ͬʱʹ�á�JDK5.0���ϣ�JVM�����ϵͳ�����������ã��������������ô�ֵ��
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction�����ڲ����ռ��������ڴ�ռ����ѹ������������������һ��ʱ���Ժ���������Ƭ����ʹ������Ч�ʽ��͡���ֵ�������ж��ٴ�GC�Ժ���ڴ�ռ����ѹ����������
-XX:+UseCMSCompactAtFullCollection�������ϴ���ѹ�������ܻ�Ӱ�����ܣ����ǿ���������Ƭ
������Ϣ
JVM�ṩ�˴��������в�������ӡ��Ϣ��������ʹ�á���Ҫ������һЩ��
-XX:+PrintGC�������ʽ��[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails�������ʽ��[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC��PrintGCTimeStamps���������������ʹ��
�����ʽ��11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-XX:+PrintGCApplicationConcurrentTime����ӡÿ����������ǰ������δ�жϵ�ִ��ʱ�䡣����������ʹ�á������ʽ��Application time: 0.5291524 seconds
-XX:+PrintGCApplicationStoppedTime����ӡ���������ڼ������ͣ��ʱ�䡣����������ʹ�á������ʽ��Total time for which application
threads were stopped: 0.0468229 seconds
-XX:PrintHeapAtGC: ��ӡGCǰ�����ϸ��ջ��Ϣ�������ʽ��
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
ת��http://zhaoshijie.iteye.com/blog/1969610