Apache Lucene? 和 Solr? 是强大的开源搜索技术,使组织能够轻松地显著增强数据访问。借助 4.x 版的 Lucene 和 Solr,向数据驱动应用程序中添加可扩展的搜索功能变得比以往更加轻松。Lucene 和 Solr 提交者 Grant Ingersoll 介绍了与相关性、分布式搜索和分面 (facet) 相关的最新 Lucene 和 Solr 功能。本文将学习如何利用这些功能构建快速、高效、可扩展的下一代数据驱动应用程序。
class="ibm-no-print ibm-ind-link" style="padding-bottom: 10px; border: 0px; font-size: 0.95em; vertical-align: baseline; font-family: HelveticaNeue-Light, 'Helvetica Neue Light', 'Helvetica Neue', Helvetica, Arial; width: 620px; line-height: 1.3em; color: #333333;">0![]() ?评论:
?评论:
2013 年 12 月 05 日
 内容
内容
我 6 年前开始为 developerWorks 编写 Solr 和 Lucene(参见?参考资料)。这些年来,Lucene 和 Solr 将自身建设成了一项坚不可摧的技术(Lucene 作为 Java? API 的基础,Solr 作为搜索服务)。举例而言,它们支持着 Apple iTunes、Netflix、Wikipedia 等许多公司的基于搜索的应用程序,它们还帮助为 IBM Watson 答问系统提供支持。
多年来,大部分人对 Lucene 和 Solr 的使用主要集中在基于文本的搜索上。与此同时,新的、有趣的大数据趋势以及对分布式计算和大规模分析的全新(重新)关注正在兴起。大数据常常还需要实时的、大规模的信息访问。鉴于这种转变,Lucene 和 Solr 社区发现自己走到了十字路口:Lucene 的核心支柱开始在大数据应用程序的压力下呈现老态,比如对 Twittersphere 的所有消息建立索引(参见?参考资料)。此外,Solr 在原生分布式索引支持上的匮乏,使得 IT 组织越来越难以富有成本效益的方式扩展他们的搜索基础架构。
该社区开始全面改革 Lucene 和 Solr 支柱(并在某些情况下改革公共 API)。我们的关注点已转向实现轻松的可伸缩性、近实时的索引和搜索,以及许多 NoSQL 功能 ― 同时利用核心引擎功能。这次全面改革的结晶是 Apache Lucene 和 Solr 4.x 版本。这些版本首当其冲的目标是解决下一代、大规模、数据驱动的访问和分析问题。
本文将介绍 4.x 的要点功能并展示一些代码示例。但是首先,您将动手体验一个实用的应用程序,它演示了将搜索引擎用于搜索以外的用途的一些概念。要充分理解本文,您应熟悉 Solr 和 Lucene 的基础知识,尤其是 Solr 请求。如果不熟悉这些知识,请参见?参考资料,获取可帮助您了解 Solr 和 Lucene 的链接。
搜索引擎仅用于搜索文本,对吧?不对!在其核心,搜索引擎关乎快速的、高效的过滤,然后依据某种相似性概念(一种在 Lucene 和 Solr 中灵活地定义的一个概念)对数据进行归类。搜索引擎还会有效地处理稀疏数据和模糊数据,这些数据是现代数据应用程序的标志性特征。Lucene 和 Solr 能够处理数字,分析复杂的地理空间问题(您很快会看到),等等。这些功能模糊了搜索应用程序与传统的数据库应用程序(以及甚至 NoSQL 应用程序)之间的界线。
例如,Lucene 和 Solr 现在:
一个搜索引擎不是所有数据问题的良方。但文本搜索在过去是 Lucene 和 Solr 的主要用途,这一事实不应阻止您使用它们解决现在或未来的数据需求。您可以考虑跳出众所周知的思维模式(搜索),以新的方式使用搜索引擎。
为了演示搜索引擎如何执行搜索以外的工作,本节剩余部分展示了一个将航空相关计数摄取到 Solr 中的应用程序。该应用程序将会查询数据(其中大部分是文本数据),并使用 D3 JavaScript 库(参见?参考资料)处理它们,然后再显示它们。该数据集来自美国运输部运输统计局的研究与创新计数管理局 (RITA) 和 OpenFlights。该数据包含某个特定时间段的所有航班的一些详细信息,比如起飞机场、目标机场、晚点时间、晚点原因和航空公司信息。通过使用该应用程序查询此数据,您可分析特定机场之间的晚点、特定机场上的流量增长等信息。
首先让该应用程序正常运行,然后查看它的一些接口。在此过程中请牢记,该应用程序可通过各种方式查询 Solr 与该数据进行交互。
首先,您需要满足以下先决条件:
monospace; line-height: 1.5em; color: #000000 !important;">bash(或类似)shell 进行终端访问。对于 Windows,您需要使用 Cygwin。我仅在 OS X 上使用?bash?shell 进行了测试。wget,如果您选择使用示例代码包中的下载脚本来下载该数据。您也可以手动下载航班数据。请参见?参考资料,获取 Lucene、Solr、wget?和 Ant 下载站点的链接。
满足这些先决条件之后,执行以下步骤让应用程序正常运行:
cd $SOLR_AIR
./bin/start-solr.sh
./bin/setup.sh
./bin/download-data.sh
bin/index.sh
bin/index.sh 1987
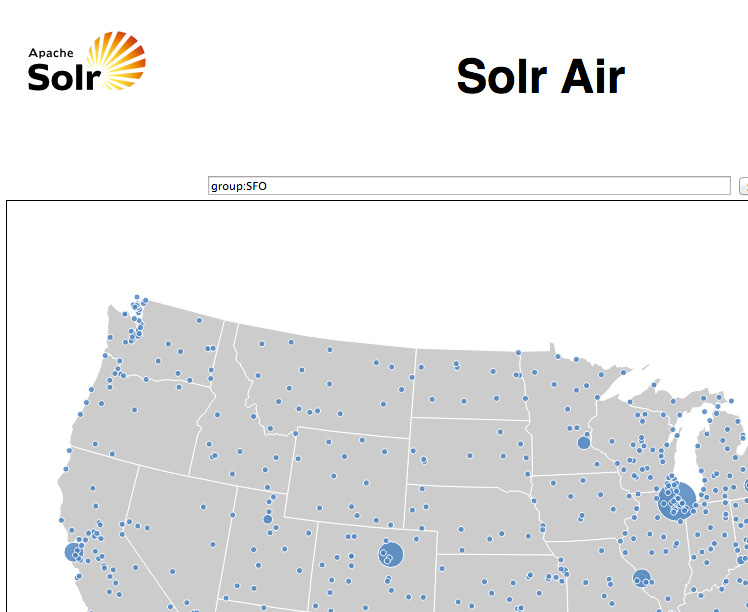
Solr Air 应用程序正常运行后,您就可以浏览该数据,查看 UI 以了解您可以询问的问题类型。在浏览器中,您应看到两个主要的接口点:地图和搜索框。对于地图,我首先从 D3 的优秀的 Airport 示例开始介绍(参见?参考资料)。我修改并扩展了该代码,以便直接从 Solr 加载所有机场信息,而不是从 D3 示例随带的示例 SCV 文件进行加载。我还对每个机场执行了一些初步的统计计算,您可以将鼠标悬停在一个特定机场上来查看该信息。
我将使用搜索框展示一些可帮助您构建复杂的搜索和分析应用程序的重要功能。要理解该代码,请参阅 solr/collection1/conf/velocity/map.vm 文件。
重要的关注区域包括:
每个区域都可以帮助您回答一些问题,比如抵达一个特定机场的航班的平均晚点时间,或者在两个机场之间飞行的一个飞机的最常见的晚点时间(根据航线进行确定,或者根据某个起飞机场与所有邻近机场之间的距离来确定)。该应用程序使用 Solr 的统计功能,再结合 Solr 存在已久的分面功能来绘制机场 “点” 的初始地图并生成基本信息,比如航班总数,平均、最短和最长晚点时间。(单单此功能就是一种查找坏数据或至少查找极端异常值的出色方法。)为了演示这些区域(并展示如何轻松地集成 Solr 与 D3),我实现了一些轻量型 JavaScript 代码,以执行以下操作:
结果类型包括:
RDU?或?SFO)的查找。SFO TO ATL?或?RDU TO ATL。(不支持多个跃点。)near?运算符查找邻近的机场,比如?near:SFO?或?near:SFO TO ATL。likely:SFO?中一样。/travel?请求处理程序的任意 Solr 查询,比如?&q=AirportCity:Francisco。上面列表中前 3 种查询类型都属于同一种类型的变体。这些变体展示了 Solr 的中心点分面功能,举例而言,显示每条路线、每个航空公司、每个航班编号最常见的抵达晚点时间(比如?SFO TO ATL)。near?选项利用新的 Lucene 和 Solr 空间功能执行大大增强的空间计算,比如复杂多边形交集。likely?选项展示了 Solr 的分组功能,以显示距离某个起飞机场的一定范围内的抵达晚点超过 30 分钟的机场。所有这些请求类型都通过少量的 D3 JavaScript 来显示信息,这增强了地图功能。对于列表中的最后一种请求类型,我只返回了关联的 JSON。这种请求类型支持您自行浏览该数据。如果在您自己的应用程序中使用这种请求类型,那么您自然地想要采用某种特定于应用程序的方式使用响应。
现在请自行尝试一些查询。例如,如果搜索?SFO TO ATL,您应看到类似图 3 的结果:
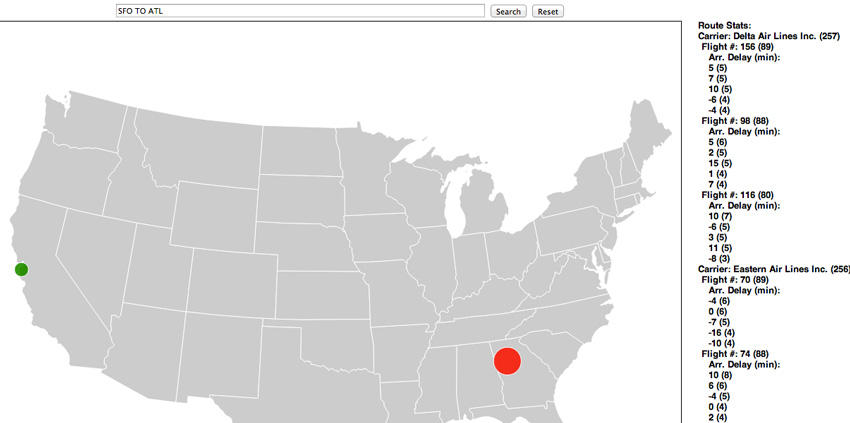
在?图 3?中,地图左侧突出显示了两个机场。右侧的 Route Stats 列表显示了每个航空公司的每个航班最常见的抵达晚点时间。(我只加载了 1987 年的数据。)例如,该列表会告诉您,Delta 航班 156 有 5 次晚点五分钟到达亚特兰大,而且有 4 次提前 6 分钟到达。
您可以在浏览器的控制台(比如在 Mac 上的 Chrome 中,选择 View -> Developer -> Javascript Console)和在 Solr 日志中查看基础的 Solr 请求。我使用的 SFO-TO-ATL 请求(在这里为了格式化用途而分为 3 行)是:
/solr/collection1/travel?&wt=json&facet=true&facet.limit=5&fq=Origin:SFO AND Dest:ATL&q=*:*&facet.pivot=UniqueCarrier,FlightNum,ArrDelay& f.UniqueCarrier.facet.limit=10&f.FlightNum.facet.limit=10
facet.pivot?参数提供了此请求中的关键功能。facet.pivot?从航空公司(称为?UniqueCarrier)移动到?FlightNum,再到?ArrDelay,因此提供了?图 3?的 Route Stats 中显示的嵌套结构。
如果尝试一次?near?插入,如?near:JFK?中所示,您的结果将类似于图 4:
支持?near?查询的 Solr 请求利用了 Solr 新的空间功能,本文后面将会详细介绍这项功能。至于现在,您可能已通过查看请求本身(这里出于格式化用途而进行了精减)而认识到这项新功能的强大之处:
... &fq=source:Airports&q=AirportLocationJTS:"IsWithin(Circle(40.639751,-73.778925 d=3))" ...
您可能已经猜到,该请求查找以纬度 40.639751 和经度 -73.778925 为中心,以 3 度(大约为 111 千米)为半径的圆圈内的所有机场。
现在您应很好地认识到 Lucene 和 Solr 应用程序能够以有趣的方式对数据(数字、文本或其他数据)执行切块和切片。而且因为 Lucene 和 Solr 都是开源的,所以可以使用适合商用的许可,您可以自由地添加自己的自定义。更妙的是,4.x 版的 Lucene 和 Solr 增加了您可以插入自己的想法和功能的位置数量,您无需大动干戈修改代码。在接下来查看 Lucene 4(编写本文时最新版为 4.4)的一些要点功能和随后查看 Solr 4 要点功能时,请记住这些功能。
?回页首
Lucene 4 几乎完全重写了 Lucene 的支柱功能,以实现更高的性能和灵活性。与此同时,这个版本还代表着社区开发软件的方式上的一次巨变,这得益于 Lucene 新的随机化单元测试框架,以及与性能相关的严格的社区标准。例如,随机化测试框架(可作为一个套装工件供任何人使用)使项目能够轻松测试变量之间的交互,这些变量包括 JVM、语言环境、输入内容和查询、存储格式、计分公式,等等。(即使您绝不使用 Lucene,也会发现该测试框架在您自己的项目中很有用。)
对 Lucene 的一些重要的增补和更改涉及到速度和内存、灵活性、数据结构和分面等类别。(要了解 Lucene 中的变化的所有详细信息,请查阅每个 Lucene 发行版中包含的 CHANGES.txt 文件。)
尽管之前的 Lucene 版本被普遍认为已足够快(具体来讲,该速度是相对于类似的一般用途搜索库而言),但 Lucene 4 中的增强使得许多操作比以前的版本快得多。
图 5 中的图表采集了 Lucene 索引的性能(以 GB 每小时来度量)。(感谢 Lucene 提交者 Mike McCandless 提供的夜间 Lucene 基础测试图表;请参见?参考资料。)图 5 表明,在 [[?年]] 5 月的前半个月发生了巨大的性能改进:
![Lucene 索引性能图表,表明在 [[?年]] 5 月的前半个月从每小时 100GB 增长到了大约每小时 270GB](/Upload/Images/2014080713/51991DCF24E362A6.jpg)
Lucene 4 包含重大的 API 更改和增强,这些都对该引擎有益,而且最终使您能够执行许多新的和有趣的功能。但从之前的 Lucene 版本升级可能需要做大量工作,尤其在您使用了任何更低级或 “专家” API 的时候。(IndexWriter?和?IndexReader?等类仍然在以前的版本中得到了广泛认可,但举例而言,您访问检索词矢量的方式已发生显著变化。)制定相应的计划。
图 5?显示的改进来自对 Lucene 构建其索引结构和方式和它在构建它们时处理并行性的方式所做的一系列更改(以及其他一些更改,包括 JVM 更改和固态驱动器的使用)。这些更改专注于在 Lucene 将索引写入磁盘时消除同步;有关的详细信息(不属于本文的介绍范畴),请参阅?参考资料,以获取 Mike McCandless 的博客文章的链接。
除了提高总体索引性能之外,Lucene 4 还可执行近实时?(NRT) 的索引操作。NRT 操作可显著减少搜索引擎反映索引更改所花的时间。要使用 NRT 操作,必须在您应用程序中,在 Lucene 的?IndexWriter?和?IndexReader?之间执行一定的协调。清单 1(来自下载包的 src/main/java/IndexingExamples.java 文件的一个代码段)演示了这种相互作用:
...
doc = new HashSet<IndexableField>();
index(writer, doc);
//Get a searcher
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(directory));
printResults(searcher);
//Now, index one more doc
doc.add(new StringField("id", "id_" + 100, Field.Store.YES));
doc.add(new TextField("body", "This is document 100.", Field.Store.YES));
writer.addDocument(doc);
//The results are still 100
printResults(searcher);
//Don't commit; just open a new searcher directly from the writer
searcher = new IndexSearcher(DirectoryReader.open(writer, false));
//The results now reflect the new document that was added
printResults(searcher);
...
在?清单 1?中,我首先为一组文档建立了索引,并将提交到?Directory,然后搜索该?Directory?― Lucene 中的传统方法。在我继续为另一个文档建立索引时,NRT 就会派上用场:无需执行全面提交,Lucene 从?IndexWriter?创建一个新?IndexSearcher,然后执行搜索。要运行此示例,可将目录更改为 $SOLR_AIR 目录并执行以下命令序列:
ant compilecd build/classesjava -cp ../../lib/*:.IndexingExamples备注:我将本文的多个代码示例分组到 IndexingExamples.java 中,所以您可使用同一个命令序列运行清单 2 和清单 4 中的示例。
打印到屏幕的输出为:
... Num docs: 100 Num docs: 100 Num docs: 101 ...
Lucene 4 还包含内存改进,利用了一些更高级的数据结构(我将在?有限状态自动机和其他好功能?中进行更详细的介绍)。这些改进不仅减少了 Lucene 的内存占用,还大大加快了基于通配符和正则表达式的查询速度。此外,代码库从处理 Java?String?对象转变为管理字节数组的大量分配。(BytesRef?类目前在 Lucene 中似乎随处可见。)结果,String?开销减小了,Java 堆上的对象数量得到了更好的控制,这减少了导致所有工作停止的垃圾收集的发生几率。
一些?灵活性增强?还带来了性能和存储改进,因为您可为您的应用程序使用的数据类型选择更好的数据结构。例如,您接下来将会看到,可在 Lucene 中选择一种方式来索引/存储惟一键(它们是稠密的且没有很好地压缩),选择一种更适合文本的稀疏性的完全不同的方式来索引/存储文本。
Lucene 4.x 中的灵活性改进为想要从 Lucene 中榨取最后一点质量和性能的开发人员(和研究人员)提供了大量的机会。为了增强灵活性,Lucene 提供了两个新的明确定义的插件点。两个插件点都显著影响着开发和使用 Lucene 的方式。
Lucene 分段是整个索引的一个子集。从许多方面来看,分段是一个自成一体的微型索引。Lucene 使用了分段平衡索引的搜索可用性和写入速度,以便构建其索引。分段是索引期间只需编写一次的文件,在写入期间,每次提交时都会创建一个新分段。在后台,默认情况下,Lucene 会定期将较小的分段合并到已交到的分段中,以提高读取性能和减少系统开销。您可练习完全掌控这一过程。
第一个新插件点设计用来为您提供对 Lucene?分段?的编码和解码的深入控制。Codec?类定义了这项功能。Codec?为您提供了控制帖子列表的格式(也就是倒排索引)、Lucene 存储、加权因子(也称为范数 (norm))等的能力。
在一些应用程序中,您可能想要实现自己的?Codec。但您可能更想要更改用于索引中的一个文档字段子集的?Codec。为了理解这一点,考虑您放入应用程序中的数据类型可能会对您有所帮助。例如,标识字段(例如您的主键)通常是惟一的。因为主键在一个文档中仅出现一次,所以您可能希望采用与编码文章正文文本不同的方式对它们进行编码。在这些情况下,您不会实际更改?Codec。相反,您更改的是?Codec?所委托的一个更低级类。
为了演示之目的,我将展示一个代码示例,其中使用了我最喜爱的?CodecSimpleTextCodec。SimpleTextCodec?从名称就可以明白其含义:一个用于编码简单文本中的索引的?Codec。(SimpleTextCodec?编写并通过 Lucene 庞大的测试框架的事实,就是对 Lucene 增强的灵活性的见证。)SimpleTextCodec?太大、太慢,不适合在生产环境中使用,但它是了解 Lucene 索引的幕后工作原理的不错方式,这正是我最喜爱它的原因。清单 2 中的代码将一个?Codec?实例更改为?SimpleTextCodec:
Codec?实例的示例...
conf.setCodec(new SimpleTextCodec());
File simpleText = new File("simpletext");
directory = new SimpleFSDirectory(simpleText);
//Let's write to disk so that we can see what it looks like
writer = new IndexWriter(directory, conf);
index(writer, doc);//index the same docs as before
...
通过运行?清单 2?的代码,您会创建一个本地 build/classes/simpletext 目录。要查看?Codec?的实际运用,可更改到 build/classes/simpletext 并在文本编辑器中打开 .cfs 文件。您可看到,.cfs 文件确实是简单文本,就像清单 3 中的代码段一样:
...
term id_97
doc 97
term id_98
doc 98
term id_99
doc 99
END
doc 0
numfields 4
field 0
name id
type string
value id_100
field 1
name body
type string
value This is document 100.
...
在很大程度上,只有在您处理极大量索引和查询量时,或者如果您是一位喜爱使用裸机的研究人员或搜索引擎内行,更改?Codec?才有用。在这些情况下更改?Codec?之前,请使用实际数据对各种可用的?Codec?执行广泛的测试。Solr 用户可修改简单的配置项来设置和更改这些功能。请参阅 Solr 参考指南,了解更多的细节(参见?参考资料)。
第二个重要的新插件点让 Lucene 的计分模型变得完全可插拔。您不再局限于使用 Lucene 的默认计分模型,一些批评者声称它太简单了。如果您喜欢的话,可以使用备用的计分模型,比如来自 Randomness 的 BM25 和 Divergence(参见?参考资料),或者您可以编写自己的模型。为什么编写自己的模型?或许您的 “文档” 代表着分子或基因;您想要采用一种快速方式来对它们分进行类,但术语频率和文档频率并不适用。或者您可能想要试验您在一篇研究文章中读到的一种新计分模型,以查看它在您内容上的工作情况。无论原因是什么,更改计分模型都需要您在建立索引时通过?IndexWriterConfig.setSimilarity(Similarity)?方法更改该模型,并在搜索时通过IndexSearcher.setSimilarity(Similarity)?方法更改它。清单 4 演示了对?Similarity?的更改,首先运行一个使用默认?Similarity?的查询,然后使用 Lucene 的?BM25Similarity?重新建立索引并重新运行该查询:
Similarity
conf = new IndexWriterConfig(Version.LUCENE_44, analyzer);
directory = new RAMDirectory();
writer = new IndexWriter(directory, conf);
index(writer, DOC_BODIES);
writer.close();
searcher = new IndexSearcher(DirectoryReader.open(directory));
System.out.println("Lucene default scoring:");
TermQuery query = new TermQuery(new Term("body", "snow"));
printResults(searcher, query, 10);
BM25Similarity bm25Similarity = new BM25Similarity();
conf.setSimilarity(bm25Similarity);
Directory bm25Directory = new RAMDirectory();
writer = new IndexWriter(bm25Directory, conf);
index(writer, DOC_BODIES);
writer.close();
searcher = new IndexSearcher(DirectoryReader.open(bm25Directory));
searcher.setSimilarity(bm25Similarity);
System.out.println("Lucene BM25 scoring:");
printResults(searcher, query, 10);
运行?清单 4?中的代码并检查输出。请注意,计分确实不同。BM25 方法的结果是否更准确地反映了一个用户想要的结果集,最终取决于您和您用户的决定。我建议您设置自己的应用程序,让您能够轻松地运行试验。(A/B 测试应有所帮助。)然后不仅对比了?Similarity?结果,还要对比了各种查询结构、Analyzer?和其他许多方面的结果。
对 Lucene 的数据结构和算法的全面修改在 Lucene 4 中带来两个特别有趣的改进:
DocValues 和 FSA 都为某些可能影响您应用程序的操作类型提供了重大的新性能优势。
在 DocValues 端,在许多情况下,应用程序需要非常快地顺序访问一个字段的所有值。或者应用程序需要对快速查找这些值来进行排序或分面,而不会导致从索引构建内存型版本(这个过程也称为非反转 (un-inverting))的成本。DocValues 设计用来满足以下需求类型。
一个没有大量通配符或模糊查询的应用程序应该看到使用 FSA 带来的重大性能改进。Lucene 和 Solr 现在支持利用了 FSA 的查询自动建议和拼写检查功能。而且 Lucene 默认的?Codec?显著减少了磁盘和内存空间占用,在幕后使用 FSA 来存储术语字典(Lucene 在搜索期间用于查询术语的结构)。FSA 在语言处理方面拥有许多用途,所以您也可能发现 Lucene 的 FSA 功能对其他应用程序很有益。
图 6 显示了一个使用单词?mop、pop、moth、star、stop?和?top?以及关联的权重,从 http://examples.mikemccandless.com/fst.py 构建的 FSA。在这个示例中,您可以想象从?moth?等输入开始,将它分解为它的字符 (m-o-t-h),然后按照 FSA 中的弧线运行。

清单 5(摘自本文的示例代码下载中的 FSAExamples.java 文件)显示了使用 Lucene 的 API 构建您自己的 FSA 的简单示例:
String[] words = {"hockey", "hawk", "puck", "text", "textual", "anachronism", "anarchy"};
Collection<BytesRef> strings = new ArrayList<BytesRef>();
for (String word : words) {
strings.add(new BytesRef(word));
}
//build up a simple automaton out of several words
Automaton automaton = BasicAutomata.makeStringUnion(strings);
CharacterRunAutomaton run = new CharacterRunAutomaton(automaton);
System.out.println("Match: " + run.run("hockey"));
System.out.println("Match: " + run.run("ha"));
在?清单 5?中,我从各种单词构建了一个?Automaton?并将它提供给?RunAutomaton。从名称可以看出,RunAutomaton?通过自动化来运行输入,并在这种情况下与从?清单 5?末尾的打印语句中捕获的输入字符串进行匹配。尽管这个示例很普通,但它为理解我将留给读者探索的 Lucene API 中的更多高级功能(和 DocValues)奠定了基础。(请参见?参考资料?以获取相关链接。)
在其核心,分面生成一定数量的文档属性,为用户提供一种缩小其搜索结果的轻松方式,无需他们猜测要向查询中添加哪些关键词。例如,如果有人在一个购物网站上搜索电视,那么分面功能会告诉他们哪些制造商生产了多少种电视型号。分面也常常用于增强基于搜索的业务分析和报告工具。通过使用更高级的分面功能,您为用户提供了以有趣方式对分面进行切片和切块的能力。
分面很久以来都是 Solr 的标志性特性(自 1.1 版开始)。现在 Lucene 拥有自己独立的分面模块可供 Lucene 应用程序使用。Lucene 的分面模块在功能上没有 Solr 丰富,但它确实提供了一些有趣的权衡。Lucene 的分面模块不是动态的,因为您必须在索引时制定一些分面决策。但它是分层的,而且它没有将字段动态非反转 (un-invert) 到内存中的成本。
清单 6(包含在示例代码的 FacetExamples.java 文件中)显示了 Lucene 的一些新的分面功能:
...
DirectoryTaxonomyWriter taxoWriter =
new DirectoryTaxonomyWriter(facetDir, IndexWriterConfig.OpenMode.CREATE);
FacetFields facetFields = new FacetFields(taxoWriter);
for (int i = 0; i < DOC_BODIES.length; i++) {
String docBody = DOC_BODIES[i];
String category = CATEGORIES[i];
Document doc = new Document();
CategoryPath path = new CategoryPath(category, '/');
//Setup the fields
facetFields.addFields(doc, Collections.singleton(path));//just do a single category path
doc.add(new StringField("id", "id_" + i, Field.Store.YES));
doc.add(new TextField("body", docBody, Field.Store.YES));
writer.addDocument(doc);
}
writer.commit();
taxoWriter.commit();
DirectoryReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
DirectoryTaxonomyReader taxor = new DirectoryTaxonomyReader(taxoWriter);
ArrayList<FacetRequest> facetRequests = new ArrayList<FacetRequest>();
CountFacetRequest home = new CountFacetRequest(new CategoryPath("Home", '/'), 100);
home.setDepth(5);
facetRequests.add(home);
facetRequests.add(new CountFacetRequest(new CategoryPath("Home/Sports", '/'), 10));
facetRequests.add(new CountFacetRequest(new CategoryPath("Home/Weather", '/'), 10));
FacetSearchParams fsp = new FacetSearchParams(facetRequests);
FacetsCollector facetsCollector = FacetsCollector.create(fsp, reader, taxor);
searcher.search(new MatchAllDocsQuery(), facetsCollector);
for (FacetResult fres : facetsCollector.getFacetResults()) {
FacetResultNode root = fres.getFacetResultNode();
printFacet(root, 0);
}
清单 6?中的重要代码(除正常的 Lucene 索引和搜索外)包含在?FacetFields、FacetsCollector、TaxonomyReader?和?TaxonomyWriter?类的使用中。FacetFields?在文档中创建了合适的字段条目,在建立索引时可与?TaxonomyWriter?结合使用。在搜索时,可结合使用TaxonomyReader?与?FacetsCollector,以获取每个类别的正确计数。另请注意,Lucene 的分面模块创建了一个辅助索引,要让该索引生效,必须让它与主要索引保持同步。使用您在前面示例的相同命令中使用的顺序来运行?清单 6?的代码,但将?java?命令中的?FacetExamples?替换为IndexingExamples。您应该得到:
Home (0.0) Home/Children (3.0) Home/Children/Nursery Rhymes (3.0) Home/Weather (2.0) Home/Sports (2.0) Home/Sports/Rock Climbing (1.0) Home/Sports/Hockey (1.0) Home/Writing (1.0) Home/Quotes (1.0) Home/Quotes/Yoda (1.0) Home/Music (1.0) Home/Music/Lyrics (1.0) ...
请注意,在这个特定的实现中,我未包含?Home?分面的计数,因为包含它们可能需要很高的成本。该选项可通过设置适当的FacetIndexingParams?来提供支持,这里没有提供有关介绍。Lucene 的分面模块拥有我未介绍的额外功能。您可以查阅?参考资料?中的文章,探索它们本文未涉及的其他新的 Lucene 功能。现在,我们来看一看 Solr 4.x。
回页首
从 API 角度讲,Solr 4.x 的外观与以前的版本很相似。但是 4.x 包含众多增强,使它比以往更容易使用并且更容易扩展。Solr 还使您能够回答新的问题类型,同时利用我刚列出的许多 Lucene 增强。其他更改主要针对开发人员的上手体验。例如,全新的 Solr 参考指南(参见?参考资料)为每个 Solr 版本(从 4.4 版开始)提供了具有图书质量的文档。而且 Solr 新的无模式功能使新数据能快速添加到索引中,无需首先定义一种模式。您稍后将看到 Solr 的无模式功能。让我们先来看一下 Solr 中一些新的搜索、分面和相关性增强,您已在 Solr Air 应用程序中看到了其中一些功能的实际应用。
一些新 Solr 4 功能设计用来在索引端和 “搜索和分面” 端更容易地构建下一代数据驱动应用程序。表 1 总结了要点功能以及适用的命令和代码示例:
http://localhost:8983/solr/collection1/travel?&wt=json&facet=true&facet.limit=5&fq=&q=*:*&facet.pivot=Origin,Dest,UniqueCarrier,FlightNum,ArrDelay&indent=true
新的相关性功能查询
在一个功能查询中访问各种索引级统计数据,比如文档频率和检索词频率。
在所有返回的文档中添加检索词?Origin:SFO?的?Document?频率:http://localhost:8983/solr/collection1/travel?&wt=json&q=*:*&fl=*, {!func}docfreq('Origin',%20'SFO')&indent=trueDocTransformers?功能。
联接
表示更复杂的文档关系,然后在搜索时联接它们。更复杂的联接计划将在未来的 Solr 版本中实现。
仅返回机场数据集中出现了其起飞机场代码的航班(并将结果与一个请求对比,而不使用联接):http://localhost:8983/solr/collection1/travel?&wt=json&indent=true&q={!join%20from=IATA%20to=Origin}*:*
Codec支持
更改索引的?Codec和各个字段的发布格式。
对一个字段使用?SimpleTextCodec:<fieldType name="string_simpletext" class="solr.StrField" postingsFormat="SimpleText" />
新的更新处理器
在建立索引之前,但在文档发送到 Solr 之后,使用 Solr 的 Update Processor 框架插入更改文档的代码。
cURL,将文档 243551 的来源更改为?FOO:curl http://localhost:8983/solr/update -H 'Content-type:application/json' -d ' [{"id":"243551","Origin":{"set":"FOO"}}]'
您可在浏览器地址栏(而不是在 Solr Air UI 中)对 Solr Air 演示数据运行?表 1?中的前 3 个示例命令。
有关相关性功能、连接和?Codec?― 以及其他新 Solr 4 功能 ― 的更多细节,请参见?参考资料?获取 Solr Wiki 和其他位置的相关链接。
或许最近几年 Solr 中最重大的变化是,构建一个多节点可扩展搜索解决方案变得简单了许多。在 Solr 4.x 中,比以往更容易将 Solr 扩展为数十亿条记录的权威的存储和访问机制 ― 同时获得 Solr 已为大家熟知的搜索和分面功能。此外,您可以在容量需求更改时重新平衡您的集群,并利用乐观锁定、内容原子更新,以及实时数据检索,即使它尚未建立索引。Solr 中新的分布式功能被统称为 SolrCloud。
SolrCloud 是如何工作的?Solr 4 在(可选的)分布式模式下运行时,发送给它的文档会依据一种哈希机制来路由到集群中的某个节点(被称为前导点 (leader))。前导点负责将文档索引到一个分片 (shard)。一个分片是一个索引,由一个前导点和 0 或多个副本组成。作为演示,我们假设您有 4 个机器和 2 个分片。在 Solr 启动时,4 个机器中的每一个与其他 3 个通信。两个机器被选为前导点,一个前导点对应一个分片。其他两个节点自动成为一个分片的副本。如果一个前导点因为某种原因而发生故障,那么分片副本(在此情况下是惟一的副本)也会成为前导点,以保证系统仍能正常运行。您可以从这个示例得出结论,在生成系统中,必须有足够多个节点参与其中,才能确保您可处理系统宕机。
要查看 SolrCloud 的实际应用,可使用一个?-z?标志运行?Solr Air 示例?中使用的 start-solr.sh 脚本,启动一个双节点、双分片的系统。从 *NIX 命令行,首先关闭您的旧实例:
kill -9 PROCESS_ID
然后重新启动系统:
bin/start-solr.sh -c -z
Zookeeper 是一个分布式协调系统,设计用来选择前导点,建立一个配额数量,并执行其他任务来协调集群中的节点。得益于 Zookeeper,Solr 集群绝不会遇到 “分裂脑” 症状,也就是说,由于一个分区事件,集群的一部分的行为与剩余部分是独立的。请参见?参考资料,了解 Zookeeper 的更多信息。
-c?标志将会擦除旧索引。-z?标志告诉 Solr 启动?Apache Zookeeper?的一个嵌入式版本。
在浏览器中打开 SolrCloud 管理页面 http://localhost:8983/solr/#/~cloud,以确认有两个节点参与到集群中。您现在可以为您的内容重新建立索引,它将分散在两个节点上。对系统的所有查询也会自动分布。您对两个节点的 “匹配所有文档” 搜索应获得与对一个节点的搜索相同的命中数。
start-solr.sh 脚本使用以下命令对第一个节点启动 Solr:
java -Dbootstrap_confdir=$SOLR_HOME/solr/collection1/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
该脚本告诉第二个节点 Zookeeper 位于何处:
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
嵌入式 Zookeeper 非常适合入门,但为了确保生产系统的高可用性和容错能力,请在您的集群中设置一组独立的 Zookeeper 实例。
以 SolrCloud 功能为基础,提供了对 NRT 和许多类似 NoSQL 的功能的支持,比如:
Solr 中的许多分布式功能和 NoSQL 功能(比如文档和事务日志的自动版本控制)会开箱即用地运行。对于其他一些功能,表 2 中的描述和示例将很有帮助:
http://localhost:8983/solr/collection1/get?id=243551
分片拆分
将您的索引拆分为更小的分片,以便它们可迁移到集群中的新节点。
将?shard1?拆分为两个分片:http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=collection1&shard=shard1
NRT
使用 NRT 搜索新内容的速度比以前的版本快得多。
在您的 solrconfig.xml 文件中打开?<autoSoftCommit>。例如:?<autoSoftCommit>
<maxTime>5000</maxTime>
</autoSoftCommit>>
文档路由
指定哪些文档位于哪些节点上。
确保一个用户的所有数据位于某些机器上。请查阅 Joel Bernstein 的博客文章(参见?参考资料)。
集合
根据需要,使用 Solr 新的集合 API 以编程方式创建、删除或更新集合。
创建一个名为?hockey?的新集合:http://localhost:8983/solr/admin/collections?action=CREATE&name=hockey&numShards=2
数据集合很少没有模式。无模式?是一个营销词汇,源自数据社区引擎对 “告诉” 引擎模式是什么的数据做出适当反应的能力,而无需引擎指定数据必须采用的格式。例如,Solr 可接受 JSON 输入,可基于 JSON 中隐式定义的模式适当地为内容建立索引。正如有人在 Twitter 上对我所说的,更少模式?是一个比无模式?更好的词汇,因为您在一个位置上(比如一个 JSON 文档)定义模式,而不是在两个位置上(比如一个 JSON 文档和 Solr)。
基于我的经验,在绝大多数情况下,您都不应在生产环境中使用无模式,除非您喜欢在凌晨两点,在您的系统认为它拥有一种数据类型而实际拥有另一种类型的时候调试错误。
Solr 的无模式功能使得客户端能够快速添加内容,而不会产生首先定义一个 schema.xml 文件的开销。Solr 检查传入的数据,并通过一个级联的值分析器集合传递该数据。值分析器猜测数据的类型,然后自动向内部模式添加字段并向索引添加内容。
典型的生产系统(也有一些例外)不应使用无模式,因为值猜测并不总是完美的。例如,Solr 第一次看到一个新字段时,它可能将该字段识别为一个整数,进而在底层模式中定义一个整数?FieldType。但您可能发现,在 3 星期后该字段无法用于搜索,因为在 Solr 看到的剩余内容中,该字段都由浮点值组成。
但是,无模式对您很少能控制其格式的内容的早期开发或索引特别有帮助。例如,表 2?包含一个使用 Solr 中的集合 API 来创建一个新集合的示例:
http://localhost:8983/solr/admin/collections?action=CREATE&name=hockey&numShards=2)
创建集合后,您可以使用无模式向它添加内容。但是,首先请看看当前的模式。作为实现无模式支持的一部分,Solr 还添加了具象状态传输 (Representational State Transfer, REST) API 来访问该模式。您可通过在浏览器中打开 http://localhost:8983/solr/hockey/schema/fields(或在命令行上使用?cURL),看到为 hockey 集合定义的所有字段。您会看到 Solr Air 示例中的所有字段。该模式使用这些字段,因为我的默认配置使用create?选项作为新集合的基础。如果愿意的话,您可改写该配置。(边注:示例代码下载文件中包含的 setup.sh 脚本使用新的模式 API 来自动创建所有字段定义。)
要使用无模式添加到集合中,可运行:
bin/schemaless-example.sh
以下 JSON 添加到您之前创建的 hockey 集合中:
[
{
"id": "id1",
"team": "Carolina Hurricanes",
"description": "The NHL franchise located in Raleigh, NC",
"cupWins": 1
}
]
通过检查将此 JSON 添加到集合之前的模式可以知道,team、description?和?cupWins?字段是新的。该脚本运行时,Solr 会自动猜测它们的类型,并在模式中创建这些字段。要验证此操作,可在 http://localhost:8983/solr/hockey/schema/fields 上刷新结果。您现在应看到team、description?和?cupWins?都已在字段列表中定义。
Solr 对基于点的空间搜索的长久支持,使您能够找到距离某个点的一定距离内的所有文档。尽管 Solr 支持在一个?n?维空间中使用此方法,但大部分人都使用它执行地理空间搜索(例如,查找我的位置附近的所有饭店)。但是直到现在,Solr 仍不支持更加复杂的空间功能,比如对多边形建立索引或在建立了索引的多边形内执行搜索。新的空间包中的一些要点包括:
Is Within、Contains?和?IsDisjointTo?的查询支持Solr Air 应用程序的模式拥有多种字段类型,它们设置来利用这种新的空间功能。我定义了两种字段类型来处理机场数据的经度和纬度:
<fieldType name="location_jts" class="solr.SpatialRecursivePrefixTreeFieldType" distErrPct="0.025" spatialContextFactory= "com.spatial4j.core.context.jts.JtsSpatialContextFactory" maxDistErr="0.000009" units="degrees"/> <fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType" distErrPct="0.025" geo="true" maxDistErr="0.000009" units="degrees"/>
location_jts?字段类型显式使用可选的 JTS 集成来定义一个点,而?location_rpt?字段类型不会这么做。如果您希望对比简单矩形更复杂的任何内容建立索引,则需要使用 JTS 版本。该字段的属性有助于定义系统的准确性。在索引时需要使用这些属性,因为 Solr 通过 Lucene 和 Spatial4j 以多种方式编码数据,以确保可在搜索时高效地使用数据。对于您的应用程序,您可能希望对您的数据运行一些测试,以确定要在索引大小、精度和查询时性能上执行的权衡。
此外,Solr Air 应用程序中使用的?near?查询使用了新的空间查询语法(一个?Circle?上的?IsWithin)来查找指定的来源和目标机场附近的机场。
在这个介绍 Solr 的一节最后我才想起,我差点忘记展示更加用户友好的现代 Solr 管理 UI 了。这个新 UI 不仅在外观上焕然一新,还添加了针对 SolrCloud、文档添加等的新功能。
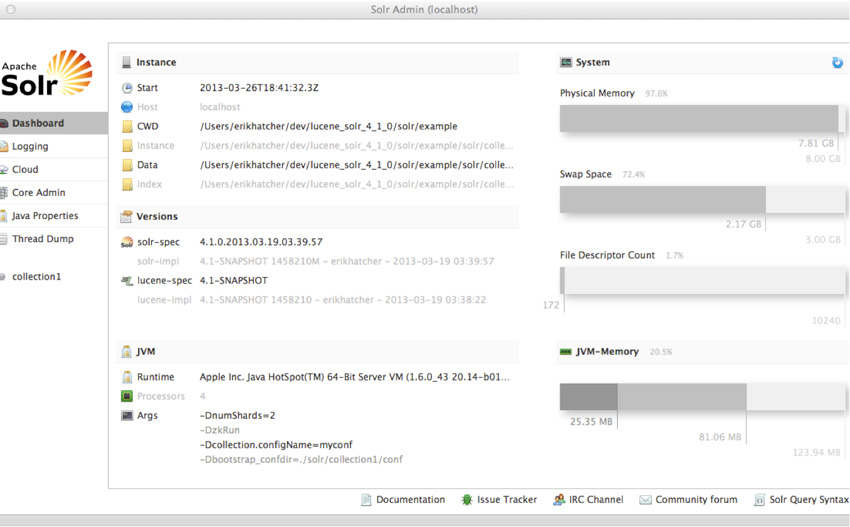
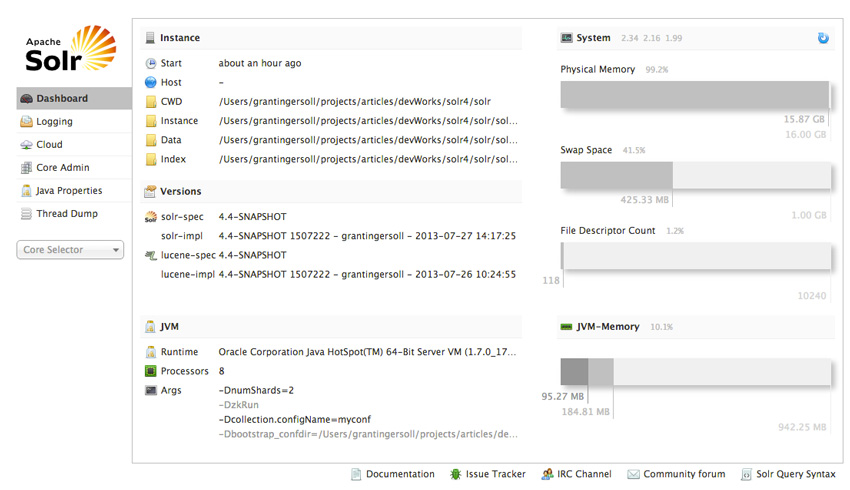
对于初学者,当首次在浏览器中打开 http://localhost:8983/solr/#/ 时,您会看到一个仪表板,简洁地显示了 Solr 的许多当前状态:内存使用、工作目录等,如图 7 所示:
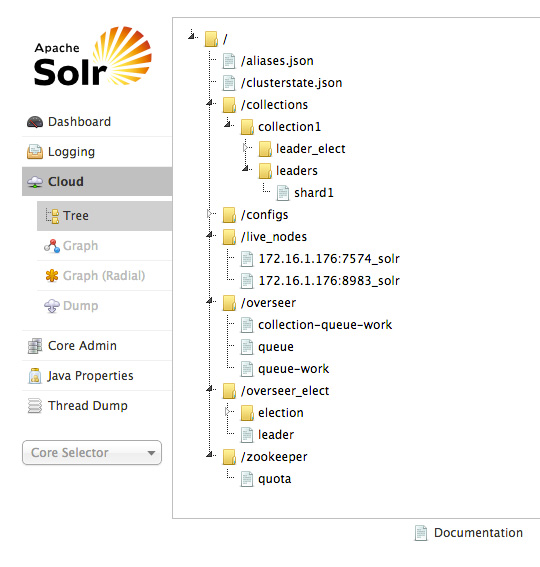
如果在仪表板左侧选择?Cloud,该 UI 将会显示 SolrCloud 的详细信息。例如,您会获得配置状态、活动节点和前导点,以及集群拓扑结构的可视化的深入信息。图 8 显示了一个示例。请花费一点时间了解一下所有云 UI 选项。(您必须在 SolrCloud 模式下运行才能看到它们。)
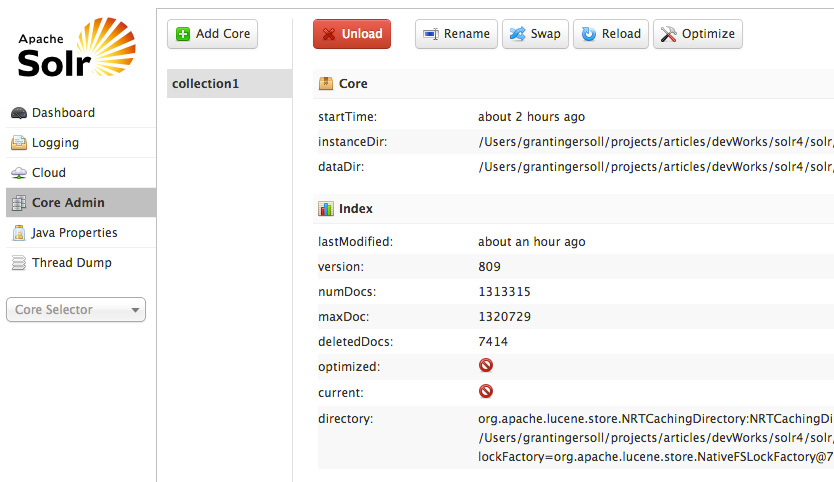
要介绍的最后一个未绑定到特定核心/集合/索引的 UI 区域是 Core Admin 屏幕集合。这些屏幕为核心的管理提供了即指即点式的控制,包括添加、删除、重新加载和交换核心。图 9 显示了 Core Admin UI:
通过从?Core?列表选择一个核心,您可以获得特定于该核心的信息和统计数据概述。图 10 显示了一个示例:
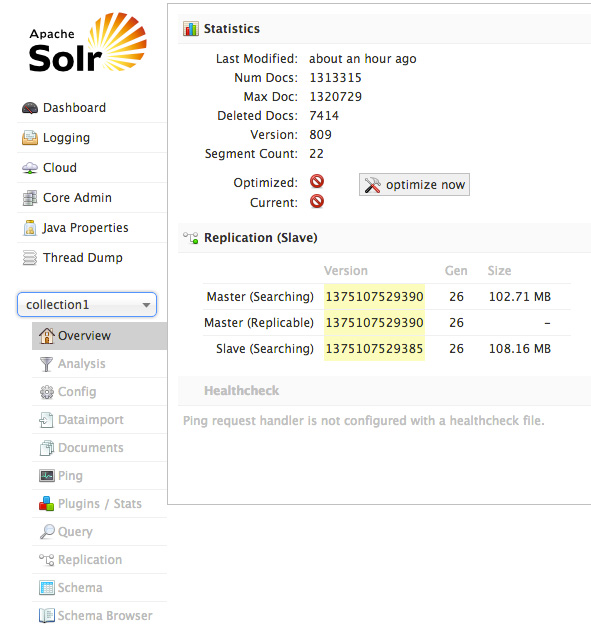
大多数针对核心的功能与 4.x 以前的 UI 的功能类似(但是使用起来更加轻松),除了?Documents?选项之外。您可以使用?Documents?选项直接从 UI 向该集合添加各种格式(JSON、CSV、XML 等)的文档,如图 11 所示:
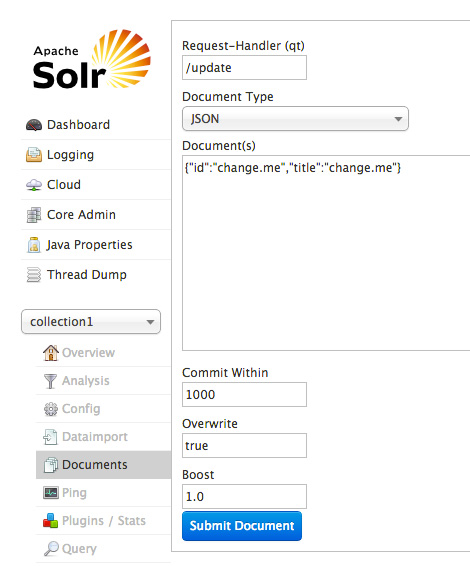
您甚至可上传富文当类型,比如 PDF 和 Word。花费片刻时间将一些文档添加到您的索引中,或者浏览其他针对集合的功能,比如?Query?接口或修改的?Analysis?屏幕。
?回页首
下一代搜索引擎技术为用户提供了决定如何处理他们的数据的权力。本文详细介绍了 Lucene 和 Solr 4 的功能,我还希望您更广泛地了解了搜索引擎如何解决涉及分析和建议的非基于文本的搜索问题。
Lucene 和 Solr 都在不断演变,这得益于一个庞大的维护社区,该社区由 30 多个提交者和数百位贡献者提供支持。该社区正在积极开发两个主要分支:目前官方发布的 4.x 分支和主干?分支,它代表着下一个主要 (5.x) 版本。在官方版本分支上,该社区致力于实现向后兼容性,实现一种专注于当前应用程序的轻松升级的增量开发方法。在主干分支上,该社区在确保与以前版本的兼容性方面受到的限制更少。如果您希望试验 Lucene 或 Solr 中的前沿技术,那么请从 Subversion 或 Git 签出主干分支代码(参见?参考资料)。无论您选择何种路径,您都可以利用 Lucene 和 Solr 实现超越纯文本搜索的基于搜索的强大分析。
http://www.ibm.com/developerworks/cn/java/j-solr-lucene/#download
?