初步实现了Android与pc服务器的通信之后,又碰到了传说中令人头疼不已的中文乱码问题。既然出现了乱码,那么原因自然是协议不通了。
我们知道eclipse中默认的编码标准是GBK,而安卓程序开发所默认的布局文件编码标准则是utf-8,这样一来,我们双方通信的时候便难免出现乱码。要解决它,就要从二者转换方面着手。
首先我们知道,从安卓手机界面上获得的文字,其编码字符集是utf-8,所以,当我们的java文件获得它时,它是以utf-8形式编译的。所以这里,在得到EditText中的文字之后,用输出流将其输出,而服务器端再用一个字符串接收从输入缓冲流中获得的一行字符。
Java代码
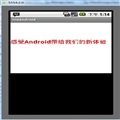
不用猜,这时由于服务器端的编码标准是GBK,读出来的字符串必然是乱码。于是在下面,我们将得到的字节数组用utf-8的格式编译。于是,期盼已久的汉字终于出来了。

但是有没有发现,当输入偶数个汉字时,得到了正确的结果,而输入奇数个时,最后一个字变成了“??”?
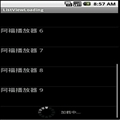
这又是为什么?这里纠结了很久,于是去搜索字符集编码的标准,终于发现了原因。对于gbk这种编码而言,中文所对应的字节数是2byte;而在utf-8中,中文则是对应三个字节。于是在输入奇数个汉字时,最后一个字节在gbk中则无法编译。譬如说utf-8编码的3个字,编码是123|456|789 ,在传输到服务器中时,系统认为这9个字节是gbk编码,于是就变成了12|34|56|78|9。后面多出的一个字节不能够编译成汉字,此时常用“?”来代替。于是最后一个byte变成了“?”(ASCII码为63)。这时再将它转成utf-8时,则变成了123|456|78?。这个时候第三个字也不能正确地读取了,于是出现了上图的结果(两个问号)。
现在,要怎样解决呢?在尝试过各种编码的转换,徘徊于各种各样的乱码之间依然无法解决的时候,突然想到,之前的读取方式是通过bufferedreader一行一行的读取的,这样一来得到的输入流在字符缓冲区的时候,已经破坏了最后一个字节。那么,如果直接得到字节数组而不破坏它,是不是能解决呢?在这里改了一下代码,直接用得到的字节数组构成一个String,然后……


可以看到,奇数个汉字也能读取啦!(耶!)虽然说这个小问题纠结了很久,但也让自己更了解了编码的奥义,收获还是很大的。
最后,解释一下new String(str.getBytes( "dd "), "cc ")的方法。简单来说,这种方法的用处是,当你的字符串的实际编码是“CC”,而被系统当成“DD”时,用这行代码可以得到正确的编码。

![[原] Intellij IDEA开发Android,祝还在使用eclipse的早日脱离苦海](/Upload/SmallIMG/2014072314/FDAC95D7604A8A71.jpg)