协议:指的是一种约定,语法约束。用于限制数据在交互时的数据格式。
HTTP协议,用于b/s架构中,浏览器与服务器之间数据传输的规则。
HTTP协议,是一个应用层的协议,只负责程序间的数据交互格式,而不用负责程序的连接。

HTTP:超文本传输协议
一共两次数据交互;
浏览器(发出请求的程序)应该向http服务器发送什么格式的数据。
由三个子部分组成:请求行,请求头,请求主体
现行的GET请求格式如下:GET /index.php?name=itcast HTTP/1.1
请求方式 地址URL 协议版本

浏览器(请求发送端)发送给服务器端的需要服务器知道的信息。
例如:user-agent:用户代理信息,用于告知服务器,请求时谁发出的。


在服务器端,可以利用$_SERVER变量,获得该信息:

host:主机,请求需要的域名。
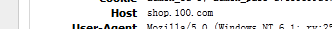
cookie:浏览器上的cookie数据
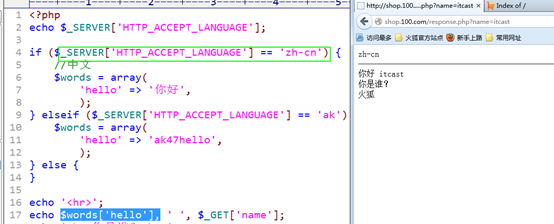
Accept-Language:浏览器可以接收的语言,通常用来判断浏览器语言,做多语言程序:
格式:
头标识:值
Host:shop.235.com
User-Agent:Firefox
注意:每个头占用一行。

采用回车+换行来表示:

使用一个空行表示头信息结束

指的是浏览器请求段发送给服务器端的数据部分。
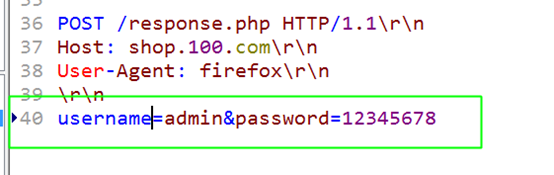
只指的是POST请求的数据。只有post请求才需要请求主体,而get没有请求主体,因为数据是在请求行中url部分传递过去的。
常规是浏览器发出请求。留啊两年期可以连接上目标服务器,并可以向目标服务器发送符合http请求协议格式的数据,此时http服务器,就知道浏览器发送了请求,做出响应。
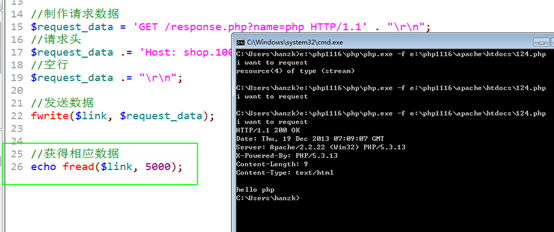
如果模拟请求,模拟浏览器做出的工作:连接上目标服务器,发送请求数据。
PHP模拟请求:

地址,端口。
利用 fsockopen 可以完成建立连接:成功后,生成链接资源。


利用连接,目标服务器写数据。

服务器处理,做出响应。
利用连接,从目标服务器读取数据的过程。
HTTP服务器(apache)应该向浏览器(请求来源)发送什么格式的数据。
分成三部分:响应状态行,响应头,响应主体
表示具体的响应结果
HTTP/1.1 200 OK
协议版本 状态码 状态消息
常见的状态码:
200 OK 成功
404 notFound 没有找到脚本
403 Forbidden 没有权限
302 Found 重定向
500 服务器错误
完整的查看:
1xx: 信息
2xx: 成功
3xx: 重定向
4xx: 客户端错误
5xx:服务器错误
服务器告知浏览器的信息部分
date: 响应时间
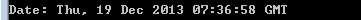
GMT时间,格林威治平时
Content-Type: 主体的类型
Content-Length: 主体的长度
注意: 每个信息占用一行,行以\r\n结束,头结束有个空行
服务器发送给请求代理端的主体数据部分
发送响应头或者响应主体。
发送响应头或者响应主体。
header()函数用于发送响应头
任何输出都算响应主体。
echo
var_dump()
php 标签外的html代码
都算响应主体。
例如,模拟cookie:

header 还可以发送响应行:


文件由服务器到浏览器,发生在响应时。
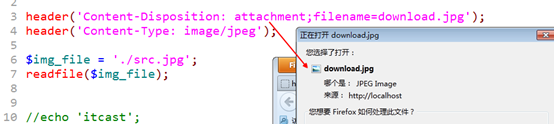
告知浏览器,响应的主体数据,作为附件来处理。不要打开,保存。
利用响应头:Content-Disposition:attachment
主体的处理方式:附件

下载图片:将图片的内容作为主体数据输出到浏览器端,并告知浏览器,将数据保存。
readfile()读取文件内容并输出。

告知浏览器保存的文件名:Content-Disposition:attachment
增加一个filename的选项即可:Content-Disposition:attachment; filename=xxx.xxx

完善的下载:处理文件格式
告知浏览器保存的文件类型:header('Content-Type: image/jpeg');
此时,建议使用fileinfo扩展,老获取文件格式:开启extension=php_fileinfo.dll(php.ini)
finfo_open();建立一个获取文件信息的资源。
finfo_file();利用资源获得某个文件的信息。

控制浏览器端的缓存数据。
利用响应头实现:
Expires:响应头,表示当前响应结果的有效期到什么时候:
????是一个GMT时间。
date()得到是本地时间
gmdate()得到格林威治平时

告知响应数据的有效期:
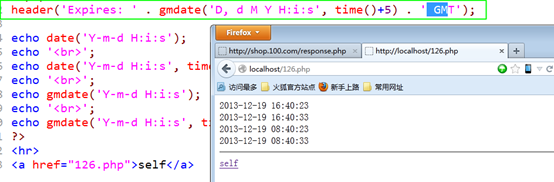
禁用浏览器缓存,应该设置失效的一个时间。
为了兼容:禁用缓存还可以如下写:

????
利用请求头重的:referer:当前请求的来源,由哪里发出的请求。

因此程序中判断请求来源,决定是否显示该图片了:

与get请求相比,post请求数据存在请求主体。
请求行:POST URL协议
请求行头:增加对请求主体的描述部分:
Content-Type:
Content-Length:
描述的请求的主体的内容:

请求主体:是请求数据即可:
不需要\r\n结束。

模拟URL请求的客户端扩展。
php支持的一个可以快速模拟请求的功能。
开启扩展:extension=php_curl.dll(php.ini)
可能需要将动态库,拷贝到windows目录:(libeay32.dll????ssleay32.dll)
?
curl_init();


利用函数:
curl_setopt(curl资源,选项标识,选项值);
?
利用选项 CURLOPT_POST 来设置是否是post请求
利用选项 CURLOPT_POSTFIELDS 来设置post 数据,支持数组形式。

在 post 数据上做操作即可:
在 post 数据 数组内,使用绝对地址前增加 @ 符号,表示该数据是个文件数据。

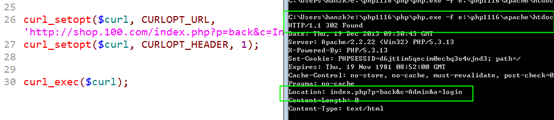
利用正确的用户名和密码,获得登陆标识,获得 cookie 中的 SESSIONID
请求 signinAction
http://shop.235.com/index.php?p=back&c=Admin&a=signin POST
需要使用 CURLOPT_COOKIEJAR 选项,可以设置一个保存服务器设置 cookie 的文件。
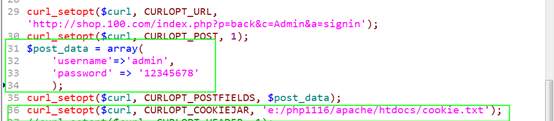

再拿着 cookie 中的 sessionID 去请求需要登陆验证脚本,服务器就认为我们认证用户,看页面。
选项:CURLOPT_COOKIEFILE 请求时,携带的 cookie 所保存的文件。
?
选项,CURL_RETURNTRANSFER

利用函数curl_exec(curl资源)

e:\Server\PHP\php.exe -f e:\Server\Apache\htdocs\129.php
在实际使用中,速度最快的排序算法。
体现的分治原则,分而治之
将困难的问题,拆分成相对简单的问题
解决难度N的问题的效率,要低于解决2个难度为N/2的问题
6个元素,做冒泡排序:5+4+3+2+1 = 15
2个3个元素,冒泡排序:2+1=3*2 = 6
步骤:

将分成两个部分,拆分的原则,找到参考源,将小于参考元分成一部分,将大于参考元的分层一部分:
典型的选择第一个元素作为参考元:

再对拆分的两个部分分别排序(还是使用该原则),最后将排序的结果与参考元再组合起来。当,序列号总,只有一个或者零个时,认为序列是排序好的,不用在拆分。
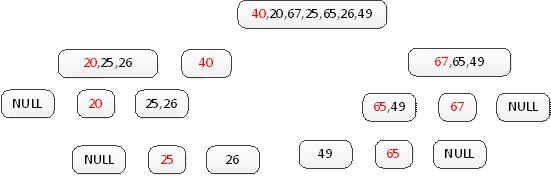
编程实现:
递归点:对任何一个拆分出来的部分排序方式一致,调用同一个函数完成。
递归出口:当需要排序的序列内,只有一个或者没有元素时,不需要递归,认为该序列已经排序完毕。
定义函数:
参数:
需要排序的序列:数组



采用同一个较大的数组
生成较大的数组

利用函数 var_export(); 将数据导出字符串,是符合PHP语法的定义数据的字符串:


使用 microtime 函数,获得当前的时间戳,精确的微秒。
形成一个桶:由待排序序列中,最小数,到,最大数之间所有的数的一个桶。先假设每个元素都出现0次。
一个数组,键表示数,值表示次数。
遍历所有待排序的序列元素,统计出现次数,并记录
遍历桶,将对应数量的元素得到即可!

20
21
25
26
…
30
40
41
…
48
49
50
..
66
67
?????1
0
2
0
?0
1
0
?0
1
0
?0
2
??????????????????????????????????????????????????????????????????????????????????????????????????????????
PHPMyAdmin
一个web版的操作mysql的工具:默认使用mysqli作为数据库操作扩展。
MySQL-Front
Navicat For MySQL