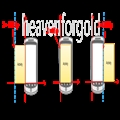
��DelimiterBasedFrameDecoder��API�������
���յ���ChannelBuffer���£�
class="java" name="code"> +--------------+
| ABC\nDEF\r\n |
+--------------+
����DelimiterBasedFrameDecoder(Delimiters.lineDelimiter())֮�õ���
+-----+-----+
| ABC | DEF |
+-----+-----+
������
+----------+
| ABC\nDEF |
Ϊʲô ��
����Ҫ��ȷ�������ָ����DelimiterBasedFrameDecoderĬ�ϻ�ȥ���ָ���
��ο���Delimiters.lineDelimiter()������������delimiter���ֱ��Ӧwindows��linux�Ļ��з�
public static ChannelBuffer[] lineDelimiter() {
return new ChannelBuffer[] {
ChannelBuffers.wrappedBuffer(new byte[] { '\r', '\n' }),
ChannelBuffers.wrappedBuffer(new byte[] { '\n' }),
};
}
����������ָ���
����һ
���á�\r\n����Ϊ�ָ�����
frameA = "ABC\nDEF"
������
���á�\n������
frameB_0 = "ABC"
frameB_1 = "DEF\r"
����frameB_0�ij��ȱ�frameA�̣���������
�����У�����÷�����
���и����⣬Ϊʲô���DZȽ�ȫ��������ֻ�Ƚ�frameB_0��
Ҫ֪����length(frameA) = length(frameB_0) + length(frameB_1)���������
�տ�ʼ���һ���Ϊ��splitһ������������һ���Է��ء�ABCDEF\r��
ʵ���ϲ���
��������һ���ָ������ͷ���һ�����
����ͨ������Ĵ���֤����
public class ClientHandler extends SimpleChannelUpstreamHandler {
@Override
public void channelConnected(ChannelHandlerContext ctx, ChannelStateEvent e)
throws Exception {
String msg = "ABC\nDEF\r\n";
ChannelBuffer buff = ChannelBuffers.buffer(msg.length());
buff.writeBytes(msg.getBytes());
e.getChannel().write(buff);
}
}
Server��
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() throws Exception {
ChannelPipeline pipeline = Channels.pipeline();
//�������ã���ɾ���ָ���������۲�
pipeline.addLast("handler1", new DelimiterBasedFrameDecoder(8192, false, Delimiters.lineDelimiter()));
pipeline.addLast("handler2", new ServerStringHandler()); //��ӡdecode��Ľ��
return pipeline;
}
});
ServerStringHandler��
public class ServerStringHandler extends SimpleChannelUpstreamHandler{
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e)
throws Exception {
ChannelBuffer buff = (ChannelBuffer)e.getMessage();
String msg = (String)buff.toString(Helper.CHARSET_UTF8);
//String s = "abc\n"; ��msg_escape ��ԭ�������abc\n���������ǡ�abc�����һ������
String msg_escape = StringEscapeUtils.escapeJava(msg);
System.out.println("msg = " + msg_escape);
}
}
���ServerStringHandler������������
msg = ABC\n
msg = DEF\r\n
�鿴Դ�룬��������
public class DelimiterBasedFrameDecoder extends FrameDecoder {
private final ChannelBuffer[] delimiters;
private final int maxFrameLength;
/*���ؽ���У��Ƿ�ȥ���ָ���
ͨ���ĵ�����ȥ���ָ���������
new DelimiterBasedFrameDecoder(8192, Delimiters.lineDelimiter())
�ȼ���
new DelimiterBasedFrameDecoder(8192, /*stripDelimiter=*/true, Delimiters.lineDelimiter())
*/
private final boolean stripDelimiter;
@Override
protected Object decode(
ChannelHandlerContext ctx, Channel channel, ChannelBuffer buffer) throws Exception {
// Try all delimiters and choose the delimiter which yields the shortest frame.
int minFrameLength = Integer.MAX_VALUE;
ChannelBuffer minDelim = null;
/*����ÿһ��delimiter�������Խ���decode��
Ȼ��ѡ�ء�shortest frame�����Ǹ�delimiter
�ص���indexOf�������
*/
for (ChannelBuffer delim: delimiters) {
int frameLength = indexOf(buffer, delim);
if (frameLength >= 0 && frameLength < minFrameLength) {
minFrameLength = frameLength;
minDelim = delim;
}
}
if (minDelim != null) {
int minDelimLength = minDelim.capacity();
ChannelBuffer frame;
if (stripDelimiter) {
frame = buffer.readBytes(minFrameLength);
buffer.skipBytes(minDelimLength);
} else {
frame = buffer.readBytes(minFrameLength + minDelimLength);
}
return frame;
}
}
/*
��frame��haystack�������������ҵ���һ��delimiter��needle�������λ�ü�Ϊi
���� ��i - haystack.readerIndex����Ҳ���Ƿָ����һ��sub frame�ij���
���Կ��������ǡ��ҵ�һ�����ͷ���һ����
*/
private static int indexOf(ChannelBuffer haystack, ChannelBuffer needle) {
//����haystack��ÿһ���ֽ�
for (int i = haystack.readerIndex(); i < haystack.writerIndex(); i ++) {
int haystackIndex = i;
int needleIndex;
/*haystack�Ƿ������delimiter��ע��delimiter��һ��ChannelBuffer��byte[]��
�������haystack="ABC\r\nDEF"��needle="\r\n"
��ô��haystackIndex=3ʱ���ҵ��ˡ�\r������ʱneedleIndex=0
����ִ��ѭ����haystackIndex++��needleIndex++��
�ҵ��ˡ�\n��
���ˣ�����needle��ƥ�䵽��
����Ȼ��ִ�е�if (needleIndex == needle.capacity())�����ؽ��
*/
for (needleIndex = 0; needleIndex < needle.capacity(); needleIndex ++) {
if (haystack.getByte(haystackIndex) != needle.getByte(needleIndex)) {
break;
} else {
haystackIndex ++;
if (haystackIndex == haystack.writerIndex() &&
needleIndex != needle.capacity() - 1) {
return -1;
}
}
}
if (needleIndex == needle.capacity()) {
// Found the needle from the haystack!
return i - haystack.readerIndex();
}
}
return -1;
}
}