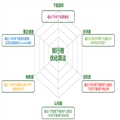
? ? ? ? ?最近在学数据结构,数据结构就我看来就是数据与数据之间的关系,比如链表就是将多个数据元素通过一定关系链接起来,只要找到第一个数据,就能找到别的所有的数据,链表的好处在于删除数据比较快捷,但查找效率就比较低,在比如树就是链表的一个延展,可以将树看成是由链表组成的,而栈只要清楚栈的定义是先来后出,后来先出,就可以通过数组实现啦,对啦 , 链表和树是要自己定义节点的。
? ? ? ? ?下面是我写的一个树类和栈类:
class="java" name="code">/**
* 栈
* @author
*
*/
public class Stack<E> {
public int temp=0;//定义栈顶
public int x;
Object[] ob=new Object[0];
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
/**
* 向栈中添加数据
* @param e 要添加的数据
*/
public void add(E e){
Object[] se=new Object[ob.length+1];
for(int i=0;i<ob.length;i++){
se[i]=ob[i];
}
se[ob.length]=e;
ob=se;
temp++;
}
/**
* 从栈中取得数据
*/
public E get(){
E relust=(E) ob[temp-1];
Object[] se=new Object[ob.length-1];
for(int i=0;i<ob.length-1;i++){
se[i]=ob[i];
}
ob=se;
temp--;
return relust;
}
/**
* 得到栈中的所有元素
* @return 所有元素
*/
public E[] getall(){
return (E[]) ob;
}
}
?
/**
* 树
* @author
*
*/
public class JTree {
private JTreeNode root;//树的根节点
/**
* 向树中添加数据
* @param e 要添加的数据
*/
public void add(int e){
JTreeNode node=new JTreeNode();
node.values=e;
//判断根节点是否为空
if(root==null){
root=node;
return;
}
else
add(root, node);
}
/**
* 建树
* @param root 树的根节点
* @param JTreeNode 要添加的节点
*/
public void add(JTreeNode root,JTreeNode node){
//首先判断节点的大小
//节点比根节点小
if(node.values<=root.values){
if(root.leftchild!=null){
//节点左孩子节点非空
add(root.leftchild, node);
}else {
//节点左孩子节点为空
root.leftchild=node;
}
}else if(node.values>root.values){//节点比根节点大
if(root.rightchild!=null){
//节点右孩子节点非空
add(root.rightchild, node);
}else{
//节点右孩子节点为空
root.rightchild=node;
}
}
}
/**
* 遍历树
*/
public void traver(){
if(root==null)
return;
System.out.println("root.values=:"+root.values);
traver(root.leftchild);
traver(root.rightchild);
}
public void traver(JTreeNode node){
if(node!=null){
// System.out.println("node.valuse=:"+node.values);
traver(node.leftchild);
// System.out.println("node.valuse=:"+node.values);
traver(node.rightchild);
System.out.println("node.valuse=:"+node.values);
}
}
}
?