谢谢园子朋友的支持,已经找到个VPS进行测试,国外的服务器: h31bt.com 大家可以给提点意见...
服务器在抓取和处理同时进行,所以访问速度慢是有些的,特别是搜索速度通过SQL的like来查询慢,正在通过分词改进中。。
http://h31bt.com:666/ 采用了hubbledotnet框架分词 来加快搜索速度,后面会用此来代替h31bt.com的网站。
DHT抓取程序开源地址:https://github.com/h31h31/H31DHTDEMO
数据处理程序开源地址:https://github.com/h31h31/H31DHTMgr
-----------------------------------------------------
目前在数据库数量从量的增加到100多万条数据时,数据库的查询插入就会面临着比较慢的问题,下面就个人在整个设计过程中的方法与大家交流学习下。
个人目前采用的方法有:
1.对每一种表进行总量限制,超过200万数据就直接分表来解决,这个主要针对种子详细列表,在主页面显示后进行的第二次显示,不会影响主页面查询速度;
http://h31bt.com/status.asp进行查看数据库表统计信息
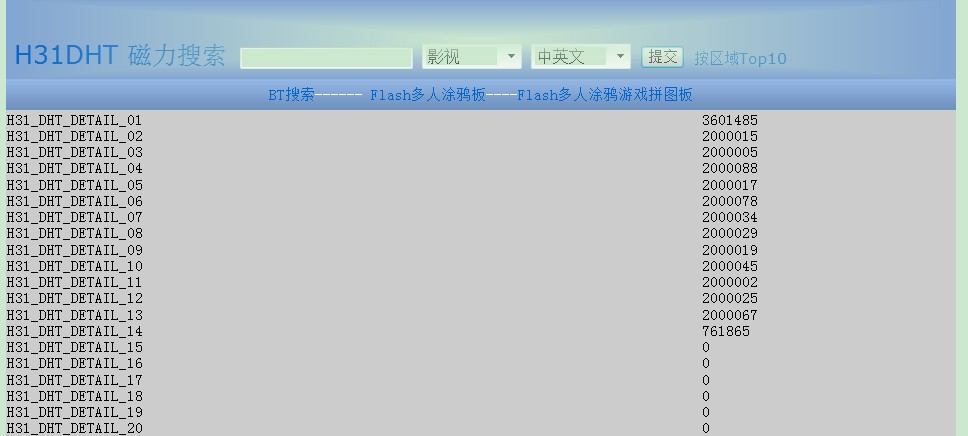
由于中间调试程序,导致第一个表数据插入过多。
2.对用户的IP进行分表存储,由于一天大概在60多万可统计IP,按照5天一分表,这样计算下来每5天差不多在300万数据左右,用来做统计分析DHT网络用户行为,当然不会在网站上显示用户的IP隐私,最多对区域的行为进行统计,大家可以到http://h31bt.com/bttop.asp 看来每个国家的前10名下载工作。

3.为了对区域排名进行显示,开始使用了group by的方式直接进行实时统计,刚开始数据量不多没有什么问题,当所有操作(网站查询,后台处理程序运行)一起的时候,会互相有影响,最后折中的方法采用程序每天定时进行统计处理,然后存储到另外的表中,这样相当于上面的表被统计后就可以直接清理了。当然网站接下来还可以显示到每个城市的下载排行。

4.数据库里面主表是每个HASH的信息,目前也采用分表的模式,主要分为1=movie 2=MUSIC 3=book 4=exe 5=PICTURE 6=other 这几大类,但信息还采用了分语言的方式,主要目前将中文和英文放到一块,然后其它语言全部在一块(主要是日语和韩语),通过分析主要是视频的数据量不小,占了大部分。

5.当程序有些错误的时候,数据库有些字段设计错误,必须将程序全部重新跑一次的时候,跑了10几天数据量需要快速来处理,如何解决速度问题,就需要考虑了,主要采用的方法还是白名单的方式,将已经处理过的正确的HASH字段存储到一个表中,然后程序多线程重新处理,1天就可以差不多跑完10天的数据量。

H31_HASH是白名单,从http://torrage.com/sync下载回来的文件批量bulkinsert到数据库中,这样就减少很多DHT网络上没有的随机HASH值,当此种方式使用后,速度能够提升30%;
但使用白名单的问题是如果此网站收集的没有最新的种子文件,那有些HASH就直接没有了,在此思路下采用黑名单的方法;
H31_HASH_BAD就产生了,下载不成功的HASH文件直接就存储到此表中,这样程序会在初期会慢很后,后来黑名单数量多了,过滤的数据当然也会多了。
使用了黑名单后,虽然最新的种子问题不需要考虑,但速度基本上没有提升,而且随着网站访问量增加 ,查询速度越来越慢,开始每天都能够处理2天的数据量的时候,现在只能处理0.5天数据量,
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
为了说明Bloom Filter存在的重要意义,举一个实例: 假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案: 1. 将访问过的URL保存到数据库。 2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。 3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。 4. Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。 方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。 以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。 方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了? 方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。 方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。 方法4消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。 实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
Bloom Filter的算法
废话说到这里,下面引入本篇的主角——Bloom Filter。其实上面方法4的思想已经很接近Bloom Filter了。方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter使用了多个哈希函数,而不是一个。 Bloom Filter算法如下: 创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。 (1) 加入字符串过程 下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程: 对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。 图1.Bloom Filter加入字符串过程 很简单吧?这样就将字符串str映射到BitSet中的k个二进制位了。 (2) 检查字符串是否存在的过程 下面是检查字符串str是否被BitSet记录过的过程: 对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。 若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了) 但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
-------------------------------
有了基本的思路后,我们采用了8个HASH生成函数来减少冲突概率,现提供代码类:
using System; using System.Collections; using System.Collections.Generic; using System.Text; using System.Runtime.Serialization.Formatters.Binary; using System.IO; namespace H31DHTMgr { public static class H31BloomFilter { /// <summary> /// BitArray用来替代内存块,在C/C++中可使用BITMAP替代 /// </summary> private static BitArray bitArray = null; private static int size = 200000000; private static string m_saveFilename = null; /// <summary> /// 构造函数,初始化分配内存 /// </summary> public static int Initialize(string savepath) { try { m_saveFilename = Path.Combine(savepath, "BadHashList.txt"); if(File.Exists(m_saveFilename)&&bitArray==null) bitArray = LoadBitArray(m_saveFilename); if (bitArray==null||bitArray.Count == 0) { bitArray = new BitArray(size, false); } } catch (System.Exception ex) { H31Debug.PrintLn("H31BloomFilter"+ex.StackTrace); return 0; } return 1; } /// <summary> /// 退出保存 /// </summary> public static int Finalize() { SaveBitArray(bitArray, m_saveFilename); return 1; } /// <summary> /// 保存 /// </summary> private static void SaveBitArray(BitArray BA, string FileName) { BinaryFormatter BF = new BinaryFormatter(); using (FileStream FS = new FileStream(FileName, FileMode.Create)) { BF.Serialize(FS, BA); } } /// <summary> /// 加载 /// </summary> private static BitArray LoadBitArray(string FileName) { BinaryFormatter BF = new BinaryFormatter(); BitArray BA = null; using (FileStream FS = new FileStream(FileName, FileMode.Open)) { BA = (BitArray)(BF.Deserialize(FS)); } return BA; } /// <summary> /// 将str加入Bloomfilter,主要是HASH后找到指定位置置true /// </summary> /// <param name="str">字符串</param> public static void Add(string str) { int[] offsetList = getOffset(str); if (offsetList != null) { put(offsetList[0]); put(offsetList[1]); put(offsetList[2]); put(offsetList[3]); put(offsetList[4]); put(offsetList[5]); put(offsetList[6]); put(offsetList[7]); } else { throw new Exception("字符串不能为空"); } } /// <summary> /// 判断该字符串是否重复 /// </summary> /// <param name="str">字符串</param> /// <returns>true重复反之则false</returns> public static Boolean Contains(string str) { int[] offsetList = getOffset(str); if (offsetList != null) { int i = 0; while (i < 8) { if ((get(offsetList[i]) == false)) { return false; } i++; } return true; } return false; } /// <summary> /// 返回内存块指定位置状态 /// </summary> /// <param name="offset">位置</param> /// <returns>状态为TRUE还是FALSE 为TRUE则被占用</returns> private static Boolean get(int offset) { return bitArray[offset]; } /// <summary> /// 改变指定位置状态 /// </summary> /// <param name="offset">位置</param> /// <returns>改变成功返回TRUE否则返回FALSE</returns> private static Boolean put(int offset) { //try //{ if (bitArray[offset]) { return false; } bitArray[offset] = true; //} //catch (Exception e) //{ // Console.WriteLine(offset); //} return true; } /// <summary> /// 计算取得偏移位置 /// </summary> private static int[] getOffset(string str) { if (String.IsNullOrEmpty(str) != true) { int[] offsetList = new int[8]; string tmpCode = Hash(str).ToString(); // int hashCode = Hash2(tmpCode); int hashCode = HashCode.Hash1(tmpCode); int offset = Math.Abs(hashCode % (size / 8) - 1); offsetList[0] = offset; // hashCode = Hash3(str); hashCode = HashCode.Hash2(tmpCode); offset = size / 4 - Math.Abs(hashCode % (size / 8)) - 1; offsetList[1] = offset; hashCode = HashCode.Hash3(tmpCode); offset = Math.Abs(hashCode % (size / 8) - 1) + size / 4; offsetList[2] = offset; // hashCode = Hash3(str); hashCode = HashCode.Hash4(tmpCode); offset = size / 2 - Math.Abs(hashCode % (size / 8)) - 1; offsetList[3] = offset; hashCode = HashCode.Hash5(tmpCode); offset = Math.Abs(hashCode % (size / 8) - 1) + size / 2; offsetList[4] = offset; // hashCode = Hash3(str); hashCode = HashCode.Hash6(tmpCode); offset = 3 * size / 4 - Math.Abs(hashCode % (size / 8)) - 1; offsetList[5] = offset; hashCode = HashCode.Hash7(tmpCode); offset = Math.Abs(hashCode % (size / 8) - 1) + 3 * size / 4; offsetList[6] = offset; // hashCode = Hash3(str); hashCode = HashCode.Hash8(tmpCode); offset = size - Math.Abs(hashCode % (size / 8)) - 1; offsetList[7] = offset; return offsetList; } return null; } /// <summary> /// 内存块大小 /// </summary> public static int Size { get { return size; } } /// <summary> /// 获取字符串HASHCODE /// </summary> /// <param name="val">字符串</param> /// <returns>HASHCODE</returns> private static int Hash(string val) { return val.GetHashCode(); } } public static class HashCode { // BKDR Hash Function public static int Hash1(string str) { int seed = 131; // 31 131 1313 13131 131313 etc.. int hash = 0; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { hash = hash * seed + (bitarray[bitarray.Length - count]); count--; } return (hash & 0x7FFFFFFF); } //AP hash function public static int Hash2(string str) { int hash = 0; int i; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; for (i = 0; i < count; i++) { if ((i & 1) == 0) { hash ^= ((hash << 7) ^ (bitarray[i]) ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ (bitarray[i]) ^ (hash >> 5))); } count--; } return (hash & 0x7FFFFFFF); } //SDBM Hash function public static int Hash3(string str) { int hash = 0; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { // equivalent to: hash = 65599*hash + (*str++); hash = (bitarray[bitarray.Length - count]) + (hash << 6) + (hash << 16) - hash; count--; } return (hash & 0x7FFFFFFF); } // RS Hash Function public static int Hash4(string str) { int b = 378551; int a = 63689; int hash = 0; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { hash = hash * a + (bitarray[bitarray.Length - count]); a *= b; count--; } return (hash & 0x7FFFFFFF); } // JS Hash Function public static int Hash5(string str) { int hash = 1315423911; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { hash ^= ((hash << 5) + (bitarray[bitarray.Length - count]) + (hash >> 2)); count--; } return (hash & 0x7FFFFFFF); } // P. J. Weinberger Hash Function public static int Hash6(string str) { int BitsInUnignedInt = (int)(sizeof(int) * 8); int ThreeQuarters = (int)((BitsInUnignedInt * 3) / 4); int OneEighth = (int)(BitsInUnignedInt / 8); int hash = 0; unchecked { int HighBits = (int)(0xFFFFFFFF) << (BitsInUnignedInt - OneEighth); int test = 0; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { hash = (hash << OneEighth) + (bitarray[bitarray.Length - count]); if ((test = hash & HighBits) != 0) { hash = ((hash ^ (test >> ThreeQuarters)) & (~HighBits)); } count--; } } return (hash & 0x7FFFFFFF); } // ELF Hash Function public static int Hash7(string str) { int hash = 0; int x = 0; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; unchecked { while (count > 0) { hash = (hash << 4) + (bitarray[bitarray.Length - count]); if ((x = hash & (int)0xF0000000) != 0) { hash ^= (x >> 24); hash &= ~x; } count--; } } return (hash & 0x7FFFFFFF); } // DJB Hash Function public static int Hash8(string str) { int hash = 5381; int count; char[] bitarray = str.ToCharArray(); count = bitarray.Length; while (count > 0) { hash += (hash << 5) + (bitarray[bitarray.Length - count]); count--; } return (hash & 0x7FFFFFFF); } } }H31BloomFilter
此类有保存到文件和从文件中加载数据的功能,方便程序退出保存黑名单。
此类存储了200000000条数据,占用内存在20M左右,使用后就减少从数据库查询工作,从而让网站的查询速度也快些。
以20M的内存来代替SQL数据库的查询工作还是值得的,虽然两都都很花费CPU,但内存的比对肯定比数据库快。
希望大家多多推荐哦...大家的推荐才是下一篇介绍的动力...
![[搜片神器]DHT后台管理程序数据库流程设计优化学习交流](/Upload/SmallIMG/2013090213/F64B7BA46EE0F5CE.jpg)




