上次我们分析了博客园闪存数据,为什么分析?那是出于个人想看看,意义不大,反正闲着也是闲着捣鼓捣鼓没神马不好,后来没有分享技术,这次我们分享一下技术,不过再分享之前,我们先来看看我又趁着,这热乎劲抓取了一把博文首页的数据分析了一下(数据来自2013-05-28 08:27至2013-08-26 15:40,大概三个月的时间,共计4k数据,也就是说这三个月总计首页发布了4k的文章,不错的效益。这次有点意外3个线程花了1min多一点的时间跑完),热腾腾的结果出炉了,这次加点个人点评。
博文数据分析
1.1发帖总人数

1.2文章发布量top30(看看发布文章数量排行前30的有哪些人?)

1.3推荐top30(看看推荐量高文章的前30人,看看谁是牛1,牛2,牛3,牛逼,有木有?哈哈哈)

1.4评论top30(文章受到评论排行前30人)

1.5阅读top30(文章阅读量排行前30,我没记错的话,有几个排行里面靠前的,恰好就是讨论岛奶车薪资的文章。看看谁是神1,神2,神9)

1.6每天发帖量

x轴由于日期太多挤在一起了,为了良好阅读我截取了日期,将峰值较低的标注了出来,翻看黄历6-11是星期二,不知为何出现低峰这个貌似不科学?是不是节假日?7-14,8-3日前者是周日,后者是周六,这个可以理解,从图中可以目测出低峰的基本都是周末的时候、其余都是工作日,大概目测下来平均每天的发文章量保持在45+左右的样子、还算可以哦、
1.7每天发布人数

同上x轴截取了,可以看出基本和上图保持一致,这样可以看出基本每天的发帖是人均一片的样子、月经贴拉低了人均值,当然也有博文小子拉高了人均值、哈哈哈、
1.8每天所有文章的阅读总量

同上x轴截取了,可以看出低峰依旧是文章量较少的日期。目测一下每天的文章阅读总量保持在4w+的数量,哈哈哈,dudu啊网站的流量不少吧,哈哈哈,照这样计算还不算闪存,其他网站流量,就这个已经够可以的了。还有博客园网站博文静态化处理百度、google的检索之靠前,敢不敢爆爆网站流量?不过没关系,我前不久看博客园还是极具价值的网站,不错!
总结:基本就统计了这些,统计这个不是目的,只是简单了解一下,数据完全真实可靠。有机会抓抓stackoverflow上面的数据分析分析。得出结论博客园人气高,流量高,文章发布量高。出现三高的势态,压力也高,所以这个就不难解释为什么前不久总是出现高血压的症状(500 错误),免费的为阿里爸爸做了云服测试?好了,这个不是大伙关心的问题,下面分享技术。
技术分享
1.方案思路:
我是在我以前写的一个网络爬虫上面扩展出来的(对网络爬虫感兴趣的可以看看《自己动手写网络爬虫》),由于当时闪存抓取的时候发现不登录只有一页的数据,所以我们要想抓取167页数据,我们要首先登录账号,发起http请求get/post请求,解析response,html数据即可,然后保存本地数据库即可至于如何分析,这个就看你数据分析的能力了。我这里就做了一下简单的数据查询。看了看我想看的数据。这里的博文还是套用闪存分析的模块,只是多加了一个html解析器(用了一下java的jsoup解析html很好,比用C#那个封装的方便多了,个人觉得是这样。)思路就是这样。
2.实现方案:
2.1所需要的工具库:
jsoup.jar 解析html用(官方:http://jsoup.org/需要神马下神马,学学学学学学)
httpclient.jar 发起http(这里不一一列举了,了解的到httpclient 官方下吧,这里不做入门官方:http://hc.apache.org/httpclient-3.x/)
数据库连接我采用mysql需要mysql-connector-java.jar (这个看你用神马数据库)
Highcharts 前端报表库,很好很强大,个人免费。
ORM 我采用hibernate(这个你也自己学,不入门网站我就不贴了,如果这也要贴网站,那你就不用学java了,不要骂我,这个是编码人员最基本的常识。不懂可以教,但是教你了,你要是不call google大神官方文档就是你的错,扯远了)
2.2模块设计:
先看看目录结构:
2.2.1发起http get、post请求。这里用到了爬虫的一个http封装模块贴一下图(这里我用windows live写上面木有装代码插件所以就只能截图了,谅解)

这个方法用了synchronized 由于我的数据抓取是线程池的方式,所以方法安全,而且这个已经是以前封装好的,所以拿过来直接用了,很好已经适用我这个需求了、不用改直接用。
2.2.2 包装登陆信息(本来这里可以通过保存cookie到本地,然后每次拿cookie访问即可,不过为了方便我就直接请求一次完成,登陆完成立刻访问uri翻页)
2.2.3 解析response html(这里就用jsoup,具体如何使用看看doc即可,这个东西就像jquery一样)
2.2.4 分装entity 交给DAO 通过ORM映射到存到数据库即可。
2.2.5 报表生成(通过Highcharts 前端报表库生成,通过后台bao层处理交个servlet,servlet response一个json数据即可)
单向流程就是如上所述这样,不过考虑数据量比较大,时间有限,加入了线程池、所以还需要补充一个
2.2.6 线程池(静态化了一个3个线程数的线程池,添加了200个线程进去,这个根据翻页的数量定。每一个线程控制当前页的数据从抓取到解析到数据持久存储,最后关闭线程池)
上面就是基本实现过程,下面是贴代码呢?还是到这里就结束呢?贴代码貌似没意义,下面结合贴图讲解代码为何这样实现。根据上面的模块设计我们一步一步来,http封装就跳过了,上面已经提过了。
2.3 模块实现及分析
2.3.1包装登陆信息
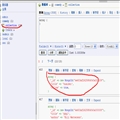
需要登陆,那我们就需要提交登陆所需要的信息然后发起http post请求给server,如果你用过httpclient,那你该知道发起post请求需要实例化一个HttpPost,下面看图识字。

上图是封装的一个httppos方法,接受一个url和一个map的参数,url就是发起post提交的url,map就是post需要的参数,其中UrlEncodedFormEntity顶级父类是AbstractHttpEntity,而AbstractHttpEntity是实现HttpEntity接口理清这个关系下面我们来看 ,http.setEntity(HttpEntity httpEntity)看到这个明白了吧,我们的post参数就是通过setEntity设置进去的,而setEntity接受的是HttpEntity,官方API是这样描述的:An entity that can be sent or received with an HTTP message. Entities can be found in some requests and in responses, where they are optional.这个大概的意思就是提供request提交参数,或者得到response的数据。entity.setContentType("application/x-www-form-urlencoded");这个头一定要设置,一般情况下server有时候接受一个json有时候接受form,所以我们要根据server的头规定来设置想要的,如果是json我们就要entity.setContentType("application/json");还可以通过httpPost.setHeader("Content-type", "application/json");来设置具体这里就不唠叨了,就是设置好头信息,及参数。(官方参考API:http://hc.apache.org/httpcomponents-client-ga/httpclient/apidocs/index.html)
下面以博客园为例完整的登陆:

通过单例化的httpClient 提交httpPost,Map就是设置cnblogs需要提交的参数,这里的httpResponse,getEntity().getContent();就是获取的响应流,前面我们提到的HttpEntity 就是从过这个来获取到的。这里我通过静态化方法saveHTMLToData();读取成String放到内存中,包裹登陆完毕,接下来就是解析html了。
2.3.2 解析response的data
解析我采用java友好的jsoup库,具体API请参考这里(http://jsoup.org/apidocs/)这里我不做多解析,根据响应得到的数据解析的方法也大致不同。讲解API这个还不如你自己翻里面都是官方解释,我就不混淆视听了。
2.3.3 ORM映射持久到数据库
通过上面的解析我们分装给定义的entity对象,然后让hibernate保存到数据库即可。这里大家根据自己喜好自行选择,跳过,不是文章重点。
2.3.4 报表生成
通过我们获取到的数据通过查询生成报表,报表我选择的是Highcharts个人免费,API文档在这里http://api.highcharts.com/highcharts 官方:http://www.highcharts.com/你可以自己下载例子,里面很多的报表,选择自己的喜欢的,后台解析成前端data需要的数据格式数据即可,一般都是json数据,根据报表的复杂程度可能需要json对象数组等。这个看看官方定义。
2.3.5 线程池
好了,上面跳了很多有人就会说,那你这不是教我看文档去嘛?有神马分享的?线程池这个或许才是我认为的重点,线程大家多少都听过实际项目用过的没几个吧?我们先不买乖子,先讲讲我这里的实现方式。通过上面的一些步骤我们逻辑处理完了,现在该线程池闪亮登场了,贴图识字。

好了,上面就是我的线程池class,也是我的main函数入口,不错run一下这个数据控制台就稀里哗啦的下雨般跑,有点像帝国的绿色背景。不闲扯我们说正题,通过Executors newFixedThreadPool(int nThreads) 我们可以生产一定数量的线程,提供给ExecutorService来管理我们生产的线程,至于为什么选择newFixedThreadPool(int nThreads)这个方法 API中是这样描述的:“创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。”也就是说我们创建固定数量的线程,我这里是3个,我们就以3个为例子,线程池帮我们管理了3个线程,运行事如果execute数大于我们线程池数3,3个线程同时抢占cpu资源(忽略安全问题等会说),当某一个线程运行完毕,只要我们后续还有线程在等待执行,这里的等待指的就是pool.execute(new Thread());那么交出cpu锁的那个线程池,处于空闲状态(也就是说3个线程池中,同时运行3个线程,其中1个已经运行完毕了,2个还在运行)只要后续还有线程执行,立刻加入到线程池可执行的队列拿到CPU锁线程开始执行,直到完毕,交出CPU锁给下一个,直到所有的线程池线程执行完毕。
好了有些人听到这里有点蒙了,不要桌急我们再理一下,你如果用过数据库连接池,这个和那个大致基本相同,类似于一个大池子里面已经为我们准备好了泡澡的水,等我们洗,你洗完了走人,后面还会有人排队的人来洗,而不是来一个人放一次水。CPU锁,可能有的人不知道或者不理解,其实我们的线程每次执行都是需要获取CPU锁这样才能执行,谁来分配不知道,为什么?线程就是像一群狼一样,一旦放开就控制不住谁先抢到只有看运气了,哈哈哈!前几天有人还问道为什么他的线程运行顺序不一样,就是这个原因,那我们认为能不能控制?可以通过线程的优先级,与线程休眠类似,线程的优先级仍然无法保障线程的执行次序。只不过,优先级高的线程获取CPU资源的概率较大,优先级低的并非没机会执行。具体可以翻看API里面有具体函数的设定。
说到这里我们有一点不可以不谈,有些人总是晒自己的机器是多少核,多少线程的?哈哈,告诉我的小伙伴们一个秘密不要妥妥的呆哦,其实如果你玩游戏那确实好,或者你做科研运行大型多线程的软件,像分布式运行计算机几个人玩的那确实杠杠的。但是作为我们开发的机器一般都是个人pc性能根本凸显不出来,而且反而可能没有单核处理好,为什么?我们个人的pc一般高数量级别的多线程软件少,而且我们基本都是单用户模式,一个人操作,你觉得你的pc会运行最佳嘛?那从哪里看性能好?cpu 的主频,这个才是王道,主频高处理效率高,单用户模式下单位时间内,软件处理事件的能力提高。举个笔者的例子,笔者新买的hp i5 1.8主频 4G内存(hp入门薄金刚超级本),和现在笔者的hp i3 2.5主频 4G内存,两个没办法比(新机器远不如老机器),两个都是同厂商主板都一样,操作系统都是正版。新机器动不动就超频,CPU100%满血,笔者那个心疼啊!可是还在服役的老机器我累个神myeclipse,vs2010常用开发工具等等同时开,都运行不带卡的,CPU70%. 神马6核8核10核,都是瞎扯淡(个人正常使用而言),你要是主频上去,单核照样杠杠的。这个尤其在手机上凸显的明显,这里不吐槽。
回到线程,线程不是我们想用就能用的,有的情况下多线程是好事,但并非所有的情况下适合多线程。所以我们要在需求上考虑我们的需求是否适合多线程运行,适合多线程,是不是就可以了?也不完全是,还要考虑多少线程数是我们运行处于最佳状态,这个要根据我们处理的任务量,机器的CPU性能等等。我这里选择3个从个人笔记本性能和服务器性能来考虑。没必要设置太多。

上图就是刚刚实例化给线程池的线程,该线程绑定了一个ThreadPostCnblogsTest 类就是 执行请求及解析数据,save数据库用的。
为了保持线程安全download木有返回值,采用synchronized 修饰。
最后有一点要讲的,多线程最危险的无非就是线程共享数据问题,有时候我们声明的全局变量在多线程下会出现内存篡改,正是线程所为,个人认为最好的方法就是变量局部化,哪里用哪里声明,有时候需要共享,那就采用方法return 该class采用synchronized 修饰确保安全,前几天和一个社区coder讨论他说一般还可以采用进程方式,即提高扩展也解决数据共享,确实不错,还有一种就是数据库方式共享数据。
over到这里完毕!累的稀里哗啦。感谢您抽宝贵的时间阅读,有问题欢迎讨论。
![纯手工打造[博客园-博文数据分析]及技术分享(java)](/Upload/SmallIMG/2013082910/AFD7066E471B2503.png)