在写本文之前,一直在想文章的标题应怎么取。在写了《ORM查询语言(OQL)简介--概念篇》、《ORM查询语言(OQL)简介--实例篇》之后,觉得本篇文章应该是前2篇的延续,但又不是一般的延续,因为今天要写的这篇内容,是基于对框架OQL完全重构之后来写的,所以加上一个副标题:脱胎换骨!
OQL是我设计用来处理PDF.NET开发框架的ORM查询的,因此叫做ORM查询语言。自2006年第一版以来,经历了多次重构,到PDF.NET Ver 4.X 版本,已经比较稳定了,在我做的项目和框架用户朋友的项目中得到成功应用,基本符合一般的常规应用需求。
OQL有下面3个显著特点:
OQL的原理基于2大特性:
OQL支持4大类数据操作
尽管OQL已经可以解决80%的查询需求,剩下的20%查询需求我都建议框架用户使用SQL-MAP技术来完成,但对于用户而言,是不太愿意从ORM模式切换到SQL模式的,希望OQL能够解决尽可能多的查询需求。那么,PDF.NET Ver 4.X 版本的OQL有哪些不足呢?
也称为表自身连接查询。OQL支持多表(实体)查询的,但却无法支持自连接查询,原因是自连接查询必须指定表的别名:
SELECT R1.readerid,R1.readername,R1.unit,R1.bookcount FROM ReaderInfo AS R1,ReaderInfo AS R2 WHERE R2.readerid=9704 AND R1.bookcount>R2.bookcount --连接关系 ORDER BY R1.bookcount
上面这个查询是从ReaderInfo表查询可借图书数目比编号为9704读者多的所有读者信息,这里对表使用了别名来实现的,如果不使用别名,那么这个查询就无法实现。而OQL之前的版本,是不支持表的别名的,因此,对于连接查询,OQL生成的可能是这样子的SQL语句:
SELECT teacher.*,student.* FROM teacher INNER JOIN student ON teacher.id=student.tea_id
老版本OQL仅支持IN条件的子查询,不能像SQL那么灵活的进行各种子查询,其实不支持的原因其中一个也是因为OQL查询不支持表的别名,另外一个原因是子查询无法获取到父查询的表名和字段名。子查询是一个很常用的功能,如果不能够支持,那么就大大限制了OQL的使用范围。
下面是来自SQLSERVER 联机帮助的说明:
子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
许多包含子查询的 Transact-SQL 语句都可以改用联接表示。其他问题只能通过子查询提出。在 Transact-SQL 中,包含子查询的语句和语义上等效的不包含子查询的语句在性能上通常没有差别。但是,在一些必须检查存在性的情况中,使用联接会产生更好的性能。否则,为确保消除重复值,必须为外部查询的每个结果都处理嵌套查询。所以在这些情况下,联接方式会产生更好的效果。以下示例显示了返回相同结果集的 SELECT 子查询和 SELECT 联接:
/* SELECT statement built using a subquery. */ SELECT Name FROM AdventureWorks2008R2.Production.Product WHERE ListPrice = (SELECT ListPrice FROM AdventureWorks2008R2.Production.Product WHERE Name = 'Chainring Bolts' ); /* SELECT statement built using a join that returns the same result set. */ SELECT Prd1. Name FROM AdventureWorks2008R2.Production.Product AS Prd1 JOIN AdventureWorks2008R2.Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice) WHERE Prd2. Name = 'Chainring Bolts';
尽管OQL可以支持实体类的批量更新与删除,但没有支持实体类的插入,原因是对单个实体类而言,可以直接调用EntityQuery<T>的Insert()方法实现。但项目中可能还是有需要写SQL插入数据的情况,比如插入Int类型的值为0,如果用实体类的方式那么该列不会被插入,因为PDF.NET的实体类认为该属性值没有改变,PDF.NET的插入和更新操作,都只处理“属性值改变过的”数据。另外,也不支持Insert....Select....From 这种批量插入方式。
INSERT INTO MySalesReason SELECT SalesReasonID, Name, ModifiedDate FROM AdventureWorks2008R2.Sales.SalesReason WHERE ReasonType = N'Marketing';
OQL老版本不支持该功能,尽管不是很常用,但配合分组查询还是有用的,如下面的例子HAVING 子句从 SalesOrderDetail 表中检索超过 $100000.00 的每个 SalesOrderID 的总计。
SELECT SalesOrderID, SUM(LineTotal) AS SubTotal FROM Sales.SalesOrderDetail GROUP BY SalesOrderID HAVING SUM(LineTotal) > 100000.00 ORDER BY SalesOrderID ;
现在流行的ORM框架很多,刚刚在写本文的时候,还发现有个朋友写了一篇各ORM对比测试的文章:
测试 ClownFish、CYQ、Entity Framework、Moon、MySoft、NHibernate、PDF、XCode数据访问组件性能这么多ORM框架,我并不是很熟悉,PDF.NET的目标只想在某些方面赶超MS的EF框架,据说现在EF6都快出来了,EF4.5在性能上上了一个台阶。面对EF这个强敌,如果PDF.NET不能解决前面说的几大缺陷,注定距离会越来越远,PDF.NET的用户对我也是常常提出批评,纷纷转投EF去了,对此我深感压力山大!
尽管EF是PDF.NET ORM 的强劲对手,但 PDF.NET ORM的查询语言OQL,相对于EF的查询语言Linq,还是有自己独立的特色,OQL比Linq更接近SQL,Linq是VS的语法糖,本质上VS编译器会将它转化成Lambda表达式,进一步转换成表达式树,最后翻译成SQL语句交给数据库去执行。所以我们会看到针对集合操作的扩展方法,有很多都要使用 => 的调用方式,而OQL没有使用Lambda,它是怎么获取到查询对应的表名称和字段名称的呢?它是怎么实现SQL查询的层次结构的呢?
PDF.NET属性的定义采用下面的形式:
public System.String UserName { get { return getProperty<System.String>("UserName"); } set { setProperty("UserName", value, 50); } }
因此在获取实体类的属性值的时候,调用了getProperty<T>("字段名") 这个方法,它里面会触发属性读取事件:
/// <summary> /// 获取属性值 /// </summary> /// <typeparam name="T">值的类型</typeparam> /// <param name="propertyName">属性名称</param> /// <returns>属性值</returns> protected T getProperty<T>(string propertyName) { this.OnPropertyGeting(propertyName); return CommonUtil.ChangeType<T>(PropertyList(propertyName)); } /// <summary> /// 属性获取事件 /// </summary> public event EventHandler<PropertyGettingEventArgs> PropertyGetting; /// <summary> /// 获取属性的时候 /// </summary> /// <param name="name"></param> protected virtual void OnPropertyGeting(string name) { if (this.PropertyGetting != null) { this.PropertyGetting(this, new PropertyGettingEventArgs(name)); } }
/// <summary> /// 属性获取事件 /// </summary> public class PropertyGettingEventArgs : EventArgs { private string _name; /// <summary> /// 属性名称 /// </summary> public string PropertyName { get { return _name; } set { _name = value; } } /// <summary> /// 以属性名称初始化本类 /// </summary> /// <param name="name"></param> public PropertyGettingEventArgs(string name) { this.PropertyName = name; } }PropertyGettingEventArgs
而OQL实例对象,正是订阅了EventHandler<PropertyGettingEventArgs> 事件:
public OQL(EntityBase e) { currEntity = e; //其它代码略 e.PropertyGetting += new EventHandler<PropertyGettingEventArgs>(e_PropertyGetting); } void e_PropertyGetting(object sender, PropertyGettingEventArgs e) { //其它代码略 }
所以,在属性获取事件中,我们可以通过PropertyGettingEventArgs.PropertyName 得到实体类属性对应的字段名称,因此,我们就可以方便的做到选取我们本次查询需要的字段,例如下面的OQL查询:
Users user = new Users(); OQL q0 = OQL.From(user) .Select(user.ID, user.UserName, user.RoleID) .END;
对应的SQL语句:
SELECT [ID], [UserName], [RoleID] FROM [LT_Users]
这样,我们无需使用委托,也不需要Lambda表达式,更不需要表达式树,就能够直接获取到要查询的表名称和字段名称,写法比Linq更简洁,处理速度更快速。当然,代价是要先实例化实体类。
在事件方法e_PropertyGetting 中,我们看看PDF.NET Ver 5.0前后的变化:
Ver 4.X 以前:
void e_PropertyGetting(object sender, PropertyGettingEventArgs e) { doPropertyGetting(((EntityBase)sender).TableName, e.PropertyName); } private void doPropertyGetting(string tableName, string propertyName) { if (isJoinOpt) { string propName = "[" + tableName + "].[" + propertyName + "]"; this.currJoinEntity.AddJoinFieldName(propName); } else { string field = this.joinedString.Length > 0 ? tableName + "].[" + propertyName : propertyName; if (!hasSelected && !selectedFields.Contains(field)) selectedFields.Add(field); } this.getingTableName = tableName; this.getingPropertyName = propertyName; }
在doPropertyGetting 方法中,区分是否有实体类连接查询,来处理不同的表名称和字段名称,这里看到连接查询的时候没有为表加上别名,而是直接使用了“表名称.字段名称”这种表示字段的形式。同时,将当前获取到的表字段名,马上赋值给getingPropertyName 变量。这带来了一个问题,属性字段名称必须马上被使用,否则就会出问题。
由于不同的情况使用属性字段的时机不一样,为了处理这些不同的情况加入了各种Case下的处理代码,比如将Select方法要使用的属性字段名称保存到列表 selectedFields 中。这种处理方法无疑大大增加了代码的复杂度。
Ver 5.0 版本的改进
前面说到属性获取到的属性字段名称必须马上被使用,否则就会出问题。如果我们不论何种情况,都将这个属性字段名先保存起来再使用呢?使用队列?链表?堆栈?这些集合都可以,但在编译原理中,对表达式的处理都是使用堆栈来做的,其中必有它的好处,以后会体会到。
下面是属性获取事件代码:
void e_PropertyGetting(object sender, PropertyGettingEventArgs e) { TableNameField tnf = new TableNameField() { Field = e.PropertyName, Entity = (EntityBase)sender, Index=this.GetFieldGettingIndex() }; fieldStack.Push(tnf); }
这里直接将属性字段名存在TablenameField 结构的Field字段中,然后将这个结构压入堆栈对象fieldStack 中,需要的时候在从堆栈中弹出最新的一个 TableNameField 结构。这样,不论是OQL的Select方法,Where方法还是OrderBy方法,都能够使用统一的堆栈结构来获取方法使用的属性字段了。
除了OQL本身需要“属性获取事件”,OQL关联的OQLCompare对象,OQLOrder对象,都需要处理属性获取事件,比如之前实例化OQLCompare对象:
/// <summary> /// 使用一个实体对象初始化本类 /// </summary> /// <param name="e"></param> public OQLCompare(EntityBase e) { this.CurrEntity = e; //this.CurrEntity.ToCompareFields = true; this.CurrEntity.PropertyGetting += new EventHandler<PropertyGettingEventArgs>(CurrEntity_PropertyGetting); } /// <summary> /// 使用多个实体类进行连接查询的条件 /// </summary> /// <param name="e"></param> /// <param name="joinedEntitys"></param> public OQLCompare(EntityBase e, params EntityBase[] joinedEntitys) { this.CurrEntity = e; this.CurrEntity.PropertyGetting += new EventHandler<PropertyGettingEventArgs>(CurrEntity_PropertyGetting); //处理多个实体类 if (joinedEntitys != null && joinedEntitys.Length > 0) { this.joinedEntityList = new List<EntityBase>(); foreach (EntityBase item in joinedEntitys) { this.joinedEntityList.Add(item); item.PropertyGetting += new EventHandler<PropertyGettingEventArgs>(CurrEntity_PropertyGetting); } } }
属性获取事件处理方法:
void CurrEntity_PropertyGetting(object sender, PropertyGettingEventArgs e) { if (this.joinedEntityList != null) { this.currPropName = "[" + ((EntityBase)sender).TableName + "].[" + e.PropertyName + "]"; } else { this.currPropName = "[" + e.PropertyName + "]"; //propertyList.Add(e.PropertyName); } }
之所以要在OQLCompare等对象中也要处理属性获取事件,是为了OQLCompare能够独立使用,但这带来一些问题:
Ver 5.0的解决办法:
在OQL对象上,定义一些方法供OQL的关联子对象来访问需要的属性字段名信息:
/// <summary> /// 从堆栈上只取一个字段名 /// </summary> /// <returns></returns> protected internal string TakeOneStackFields() { //其它代码略 TableNameField tnf = fieldStack.Pop(); return GetOqlFieldName(tnf); }
SQL是结构化查询语言,它自身也是非常结构化的,每一个查询都有固定的语法结构,以Select为例,它可以有多种形式的写法:
SELECT Field1,Field2... FROM [Table] ----------------- SELECT Field1,Field2... FROM [Table] WHERE Condition ----------------- SELECT Field1,Field2... FROM [Table] WHERE Condition ORDER BY FieldOrder ----------------- SELECT FieldGroup FROM [Table] WHERE Condition GROUP BY FieldGroup ORDER BY FieldOrder ---------------- SELECT FieldGroup FROM [Table] WHERE Condition GROUP BY FieldGroup HAVING havingExp ORDER BY FieldOrder ----------------- SELECT Field1,Field2... FROM [Table1] JOIN [Table2] ON [Table1].PK=[Table2].FK WHERE Condition ORDER BY FieldOrder ----------------- SELECT Field1,Field2... FROM [Table1],[Table2] WHERE [Table1].PK=[Table2].FK And OtherCondition ORDER BY FieldOrder -----------------
仔细观察,万变不离其宗,上面的写法其实都是以下关键字所在层次结构在不同情况下的组合而已,除了Select是必须的:
SELECT FROM JOIN ON WHERE GROUP BY HAVEING ORDER BY
如果要以面向对象的方式来实现SQL这个关键字层次结构,我们必须将相关的关键字作为方法,定义在合适的对象中,然后靠对象的层次结构,来限定正确的“SQL”结构,为此,我们先重新来定义一下OQL使用的接口IOQL和关联的接口的层次定义:
public interface IOQL { OQL1 Select(params object[] fields); } public interface IOQL1 : IOQL2 { //OQL End { get; } //OQL3 GroupBy(object field); //OQL4 Having(object field); //OQL4 OrderBy(object field); OQL2 Where(params object[] fields); } public interface IOQL2 : IOQL3 { //OQL End { get; } OQL3 GroupBy(object field); //OQL4 Having(object field); //OQL4 OrderBy(object field); } public interface IOQL3 : IOQL4 { OQL4 Having(object field); //OQL End { get; } //OQL4 OrderBy(object field); } public interface IOQL4 { OQL END { get; } OQLOrderType OrderBy(object field); }
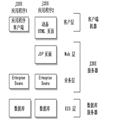
然后,让OQL实现IOQL,在定义其他OQL子对象来实现其它子接口。由于对象比较多,还是通过一个对象结构图来看更方便:
图1:OQL接口层次图
图2:OQL体系结构图
SQL的查询条件可以很简单,也可以很复杂,比如下面的复合查询条件:
SELECT M.*,T0.* FROM [LT_Users] M INNER JOIN [LT_UserRoles] T0 ON M.[RoleID] = T0.[ID] WHERE ( M.[UserName] = @P0 AND M.[Password] = @P1 AND T0.[RoleName] = @P2 ) OR ( ( M.[UserName] = @P3 AND M.[Password] = @P4 AND T0.[ID] IN (1,2,3) ) OR M.[LastLoginTime] > @P5 )
这个查询条件分为2组条件,然后第二组查询内部又包含2组查询,从括号层数来说,仅仅有3层,但看起来已经够复杂了。实际项目中,我曾遇到过用5000行业务代码来构造SQL查询条件的情况,不要吃惊,的确是5000行业务代码,当然不是说SQL条件有5000行,但也可以想象到,最终生成的SQL查询条件的长度不会小于50行。这样复杂的查询条件,如果用拼接SQL字符串的方式来完成,工作量是不可想象的,维护起来也是非常困难。但是,我们可以利用OQL的查询条件对象OQLCompare来完成,因为它实质上是一个组合对象,即N多个OQLCompare组合成一个OQLCompare对象,不过为了实现方便,我们规定每个OQLCompare对象下面存放2个子对象,也就是建立一个二叉树来存储所有的比较对象:
public class OQLCompare { //其它代码略 protected OQLCompare LeftNode { get; set; } protected OQLCompare RightNode { get; set; } protected CompareLogic Logic { get; set; } protected bool IsLeaf { get { return object.Equals(LeftNode, null) && object.Equals(RightNode, null); } } protected string ComparedFieldName; protected string ComparedParameterName; protected CompareType ComparedType; }
还是用一张图来看看查询条件的构成比较直观:
图3:OQLCompare 对象树
该图的内容,说明了构造上面的SQL条件的OQLCompare比较对象的树型结构,我们规定,每个节点下面只有左节点和右节点,左节点优先,左右子节点都可以是空,如果符合该条件,则当前节点为叶子结点,否则为枝节点。
从上图可以很容易发现,其实这就是一个“组合模式”,而组合模式的每个节点都具有相同的行为和特性,所以,我们可以构建非常复杂的组合体系,最终构造超级复杂的查询条件,而在最终使用上,一组查询条件跟一个查询条件的处理过程是一样的。
括号是控制表达式计算顺序的重要手段,对于逻辑表达式,使用AND,OR 来连接两个子表达式,如果AND,OR同时出现,则需要用括号来改变表达式元素计算的顺序。C,C++,C# 对表达式都是“左求值计算”的,这是一个很重要的概念,某些程序语言可能是“右求值计算”的。如果表达式中有括号,那么前面的计算将挂起,计算完括号内的结果后,再继续处理表达式的剩余部分。因此,我们可以把括号看作一个“树枝节点”,而括号内最内层的节点,为叶子结点,按照我们对节点类型的定义和上面示例的OQLCompare条件组合树,在输出SQL条件字符串的时候,可能是这个样子的:
SELECT M.*,T0.* FROM [LT_Users] M INNER JOIN [LT_UserRoles] T0 ON M.[RoleID] = T0.[ID] WHERE (( ( M.[UserName] = @P0 AND M.[Password] = @P1) AND T0.[RoleName] = @P2 ) OR ( ( (M.[UserName] = @P3 AND M.[Password] = @P4) AND T0.[ID] IN (1,2,3) ) OR M.[LastLoginTime] > @P5 ) )
假设条件表达式需要对10个字段的比较内容进行AND 判断,那么将会嵌套10-1=9 层括号。
不要小看这个问题,前面我说到的那个5000行业务代码构建SQL查询条件的事情,就曾经发生过构造了128层括号的事情,最终导致SQLSERVER报错:
查询条件括号嵌套太多,查询分析器无法处理!
那么括号怎么化简呢?
这个得从表达式的逻辑语义上去分析:
所以,我们可以检查“子树枝节点”的逻辑比较类型,如果它的类型与当前节点的逻辑比较类型相同,那么对子树枝节点的处理就不需要使用括号了。
可以通过哦递归过程,处理完所有的子节点的括号问题,从而最终得到我们看起来非常简单的条件表达式。
(本文篇幅太长,未完待续)