enode框架系列step by step文章系列索引:
开源地址:https://github.com/tangxuehua/enode
上一篇文章,简单介绍了enode框架内部的整体实现思路,用到了staged event-driven architecture的思想。通过前一篇文章,我们知道了enode内部有两种队列:command queue、event queue;用户发送的command会进入command queue排队,domain model产生的domain event会进入event queue,然后等待被dispatch到所有的event handlers。本文介绍一下enode框架中这两种消息队列到底是如何设计的。
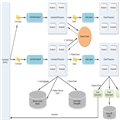
先贴一下enode框架的内部实现架构图,这样对大家理解后面的分析有帮助。

enode的设计初衷是在单个进程内提供基于DDD+CQRS+EDA的应用开发。如果我们的业务需要和其他系统交互,那也可以,就是通过在event handler中与其他外部系统交互,比如广播消息出去或者调用远程接口,都可以。也许将来,enode也会内置支持远程消息通信的功能。但是不支持远程通信并不表示enode只能开发单机应用了。enode框架需要存储的数据主要有三种:
好,通过上面的分析,我们知道enode框架运行时的所有数据,就存储在mongodb和redis这两个地方。而这两种存储都是部署在独立的服务器上,与web服务器无关。所以运行enode框架的每台web服务器上是无状态的。所以,我们就能方便的对web服务器进行集群,我们可以随时当用户访问量的增加时增加新的web服务器,以提高系统的响应能力;当然,当你发现随着web服务器的增加,导致单台mongodb服务器或单台redis服务器处理不过来成为瓶颈时,也可以对mongodb和redis做集群,或者对数据做sharding(当然这两种做法不是很好做,需要对mongodb,redis很熟悉才行),这样就可以提高mongodb,redis的吞吐量了。
好了,上面的分析主要是为了说明enode框架的使用范围,讨论清楚这一点对我们分析需要什么样的消息队列有很大帮助。
现在我们知道,我们完全不需要分布式的消息队列了,比如不需要MSMQ、RabbitMQ,等重量级成熟的支持远程消息传递的消息队列了。我们需要的消息队列的特征是:
内存队列,特点是快。但是我们不光是需要快,还要能支持并发的入队和出对。那么看起来ConcurrentQueue<T>似乎能满足我们的要求了,一方面性能还可以,另一方面内置支持了并发操作。但是有一点没满足,那就是我们希望当队列里没有消息的时候,队列的消费者不能让CPU空转,CPU空转会直接导致CPU占用100%,导致机器无法工作。幸运的是,.net中也有一个支持这种功能的集合,那就是:BlockingCollection<T>,这种集合能提供在队列内无元素的时候block当前线程的功能。我们可以用以下的方式来实例化一个队列:
private BlockingCollection<T> _queue = new BlockingCollection<T>(new ConcurrentQueue<T>());
并发入队的时候,我们只要写下面的代码即可:
_queue.Add(message);
并发出队的时候,只要:
_queue.Take();
我们不难看出,ConcurrentQueue<T>是提供了队列加并发访问的支持,而BlockingCollection<T>是在此基础上再增加blocking线程的功能。
是不是非常简单,经过我的测试,BlockingCollection<T>的性能已经非常好,每秒10万次入队出对肯定没问题,所以不必担心成为瓶颈。
关于Disruptor的调研:
了解过LMAX架构的朋友应该听说过Disruptor,LMAX架构能支持每秒处理600W订单,而且是单线程。这个速度是不是很惊人?大家有兴趣的可以去了解下。LMAX架构是完全in memory的架构,所有的业务逻辑基于纯内存实现,粗粒度的架构图如下:

LMAX架构之所以能这么快,除了完全基于in memory的架构外,还归功于延迟率在纳秒级别的disruptor队列组件。下面是disruptor与java中的Array Blocking Queue的延迟率对比图:
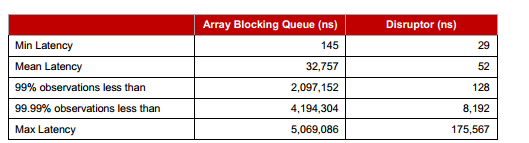
ns是纳秒,我们可以从数据上看到,Disruptor的延迟时间比Array Blocking Queue快的不是一个数量级。所以,当初LMAX架构出来时,一时非常轰动。我曾经也对这个架构很好奇,但因为有些细节问题没想清楚,就不敢贸然实践。
通过上面的分析,我们知道,Disruptor也是一种队列,并且也完全可以替代BlockingCollection,但是因为我们的BlockingCollection目前已经满足我们的需要,且暂时不会成为瓶颈,所以,我暂时没有采用Disruptor来实现我们的内存队列。关于LMAX架构,大家还可以看一下这篇我以前写的文章。
我们不光需要一个高性能且支持并发的内存队列,还要支持队列消息的持久化功能,这样我们才能保证消息不会丢失,从而才能谈消息至少被处理一次。
那消息什么时候持久化?
当我们发送一个消息给队列,一旦发生成功,我们肯定认为消息已经不会丢了。所以,很明显,消息队列内部肯定是要在接收到入队的消息时先持久化该消息,然后才能返回。
那么如何高效的持久化呢?
第一个想法:
基于txt文本文件的顺序写。原理是:当消息入队时,将消息序列化为文本,然后append到一个txt1文件;当消息被处理完之后,再把该消息append到另一个txt2文件;然后,如果当前机器没重启,那内存队列里当前存在的消息就是还未被处理的消息;如果机器重启了,那如何知道哪些消息还没被处理?很简单,就是对比txt1,txt2这两个文本文件,然后只要是txt1中存在,但是txt2中不存在的消息,就认为是没被处理过,那需要在enode框架启动时读取txt1中这些没被处理的消息文本,反序列化为消息对象,然后重新放入内存队列,然后开始处理。这个思路其实挺好,关键的一点,这种做法性能非常高。因为我们知道顺序写文本文件是非常快的,经过我的测试,每秒200W行普通消息的文本不在话下。这意味着我们每秒可以持久化200W个消息,当然实际上我们肯定达不到这个高的速度,因为消息的序列化性能达不到这个速度,所以瓶颈是在序列化上面。但是,通过这种持久化消息的思路,也会有很多细节问题比较难解决,比如txt文件越来越大,怎么办?txt文件不好管理和维护,万一不小心被人删除了呢?还有,如何比较这两个txt文件?按行比较吗?不行,因为消息入队的顺序和处理的顺序不一定相同,比如command就是如此,当用户发送一个command到队列,但是处理的时候发现第一次由于并发冲突,导致command执行没成功,所以会重试command,如果重试成功了,然后持久化该command,但是我们知道,此时持久化的时候,它的顺序也许已经在后面的command的后面了。所以,我们不能按行比较;那么就要按消息的ID比较了?就算能做到,那这个比较过程也是很耗时的,假设txt1有100W个消息;txt2中有80W个消息,那如果按照ID来比较txt1中哪20W个消息还没被处理,有什么算法能高效比较出来吗?所以,我们发现,这个思路还是有很多细节问题需要考虑。
第二个想法:
采用NoSQL来存储消息,通过一些思考和比较后,觉得还是MongoDB比较合适。一方面MongoDB实际上所有的存取操作优先使用内存,也就是说不会马上持久化到磁盘。所以性能很快。另一方面,mongodb支持可靠的持久化功能,可以放心的用来持久化消息。性能方面,虽然没有写txt那么快,但也基本能接受了。因为我们毕竟不是整个网站的所有用户请求的command都是放在一个队列,如果我们的网站用户量很大,那肯定会用web服务器集群,且每个集群机器上都会有不止一个command queue,所以,单个command queue里的消息我们可以控制为不会太多,而且,单个command queue里的消息都是放在不同的mongodb collection中存储;当然持久化瓶颈永远是IO,所以真的要快,那只能一个独立的mongodb server上设计一个collection,该collection存放一个command queue里的消息;其他的command queue的消息就也采用这样的做法放在另外的mongodb server上;这样就能做到IO的并行,从而根本上提高持久化速度。但是这样做代价很大的,可能需要好多机器呢,整个系统有多少个queue,那就需要多少台机器,呵呵。总而言之,持久化方面,我们还是有一些办法可以去尝试,还有优化的余地。
再回过头来简单说一下,采用mongodb来持久化消息的实现思路:入队的时候持久化消息,出队的时候删除该消息;这样当机器重启时,要查看某个队列有多少消息,只要通过一个简单的查询返回mongodb collection中当前存在的消息即可。这种做法设计简单,稳定,性能方面目前应该还可以接受。所以,目前enode就是采用这种方法来持久化所有enode用到的内存队列的消息。
代码示意,有兴趣的可以看看:
public abstract class QueueBase<T> : IQueue<T> where T : class, IMessage { #region Private Variables private IMessageStore _messageStore; private BlockingCollection<T> _queue = new BlockingCollection<T>(new ConcurrentQueue<T>()); private ReaderWriterLockSlim _enqueueLocker = new ReaderWriterLockSlim(); private ReaderWriterLockSlim _dequeueLocker = new ReaderWriterLockSlim(); #endregion public string Name { get; private set; } protected ILogger Logger { get; private set; } public QueueBase(string name) { if (string.IsNullOrEmpty(name)) { throw new ArgumentNullException("name"); } Name = name; _messageStore = ObjectContainer.Resolve<IMessageStore>(); Logger = ObjectContainer.Resolve<ILoggerFactory>().Create(GetType().Name); } public void Initialize() { _messageStore.Initialize(Name); var messages = _messageStore.GetMessages<T>(Name); foreach (var message in messages) { _queue.Add(message); } OnInitialized(messages); } protected virtual void OnInitialized(IEnumerable<T> initialQueueMessages) { } public void Enqueue(T message) { _enqueueLocker.AtomWrite(() => { _messageStore.AddMessage(Name, message); _queue.Add(message); }); } public T Dequeue() { return _queue.Take(); } public void Complete(T message) { _dequeueLocker.AtomWrite(() => { _messageStore.RemoveMessage(Name, message); }); } }View Code
思路应该很容易想到,就是先把消息从内存队列dequeue出来,然后交给消费者处理,然后由消费者告诉我们当前消息是否被处理了,如果没被处理好,那需要尝试重试处理,如果重试几次后还是不行,那也不能把消息丢弃了,但也不能无休止的一直只处理这个消息,所以需要把该消息丢到另一个专门用于处理需要重试的本地纯内存队列。如果消息被处理成功了,那就把该消息从持久化设备中删除即可。看一下代码比较清晰吧:
private void ProcessMessage(TMessageExecutor messageExecutor) { var message = _bindingQueue.Dequeue(); if (message != null) { ProcessMessageRecursively(messageExecutor, message, 0, 3); } } private void ProcessMessageRecursively(TMessageExecutor messageExecutor, TMessage message, int retriedCount, int maxRetryCount) { var result = ExecuteMessage(messageExecutor, message); //这里表示在消费(即处理)消息 //如果处理成功了,就通知队列从持久化设备删除该消息,通过调用Complete方法实现 if (result == MessageExecuteResult.Executed) { _bindingQueue.Complete(message); } //如果处理失败了,就重试几次,目前是3次,如果还是失败,那就丢到一个重试队列,进行永久的定时重试 else if (result == MessageExecuteResult.Failed) { if (retriedCount < maxRetryCount) { _logger.InfoFormat("Retring to handle message:{0} for {1} times.", message.ToString(), retriedCount + 1); ProcessMessageRecursively(messageExecutor, message, retriedCount + 1, maxRetryCount); } else { //这里是丢到一个重试队列,进行永久的定时重试,目前是每隔5秒重试一下,_retryQueue是一个简单的内存队列,也是一个BlockingCollection<T> _retryQueue.Add(message); } } }
代码应该很清楚了,我就不多做解释了。
本文主要介绍了enode框架中消息队列的设计思路,因为enode中有command queue和event queue,两种queue,所以逻辑是类似的;所以本来还想讨论一下如何抽象和设计这些queue,已去掉重复代码。但时间不早了,下次再详细讲吧。