Htmlparser 简介
htmlparser是一个纯的java写的html
解析的库,它不依赖于其它的java库文件,主要用于改造或
提取html。它能超高速解析html,而且不会出错。现在htmlparser最新
版本为2.0。
基础运用
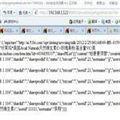
目标页面代码
<ul class="list_ul">
<li class="title_li">1
<a href="http://f.wanfangdata.com.cn/download/Periodical_zhfsbx98200105004.aspx" style="" title="全文" target="_blank" class="pdf_img"></a>
<a href="http://d.wanfangdata.com.cn/Periodical_zhfsbx98200105004.aspx" style="display:none" title="文摘" target="_blank" class="abs_img"></a>
[url=http://d.wanfangdata.com.cn/Periodical_zhfsbx98200105004.aspx]抗环瓜氨酸肽抗体检测在<font color="red">类风湿</font>关节炎中的意义[/url]
<span>(<t>被引用</t> 182 <t>次</t>)</span></li>
<li class="greencolor">[<t>期刊论文</t>] [url=http://c.wanfangdata.com.cn/Periodical-zhfsbx98.aspx]《中华风湿病学杂志》[/url]
<span>
<span title="被中信所《中国科技期刊引证报告》收录">ISTIC</span>
<span title="被北京大学《中文核心期刊要目总览》收录">PKU</span>
</span>-[url=http://c.wanfangdata.com.cn/periodical/zhfsbx98/2001-5.aspx]2001年5期[/url]<a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e6%9b%be%e5%b0%8f%e5%b3%b0">曾小峰</a><a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e8%89%be%e8%84%89%e5%85%b4">艾脉兴</a><a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e7%94%98%e6%99%93%e4%b8%b9">甘晓丹</a><a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e5%8f%b2%e8%89%b3%e8%90%8d">史艳萍</a><a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e5%ae%8b%e7%90%b4%e8%8a%b3">宋琴芳</a><a target="_blank" href="http://social.wanfangdata.com.cn/Locate.ashx?ArticleId=zhfsbx98200105004&Name=%e5%94%90%e7%a6%8f%e6%9e%97">唐福林</a></li>
</ul>
目标解析上述页面代码,获取标签
[url=http://d.wanfangdata.com.cn/Periodical_zhfsbx98200105004.aspx]抗环瓜氨酸肽抗体检测在<font color="red">类风湿</font>关节炎中的意义[/url]
中的内容,通过htmlparser实现如下:
package com.nit.htmlparser.test;
import java.io.File;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.AndFilter;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.util.NodeList;
public class Htmlparser {
public static void main(String[] args) {
File file = new File("E:\\JavaEE Work\\HtmlparserTest\\source.txt");//获取上述html代码
try {
Parser parser = new Parser(file.getAbsolutePath());
parser.setEncoding("GBK");
//设置编码格式
NodeFilter filter1 = new TagNameFilter("li");
NodeFilter filter2 = new HasAttributeFilter("class","title_li");
NodeFilter filter = new AndFilter(filter1,filter2);
//设置页面过滤条件
NodeList nodeList = parser.extractAllNodesThatMatch(filter);
//根据过滤条件解析页面
Node node = nodeList.elementAt(0);
String html = node.getChildren().toHtml();
//将抽取出来的信息转化为html再次解析
filter1 = new HasAttributeFilter("target", "_blank");
parser = Parser.createParser(html, "GBK");
nodeList = parser.extractAllNodesThatMatch(filter1);
System.out.println(nodeList.elementAt(2).getChildren().asString());
filter2 = new TagNameFilter("span");
parser = Parser.createParser(html, "GBK");
nodeList = parser.extractAllNodesThatMatch(filter2);
System.out.println(nodeList.elementAt(0).getChildren().asString());
} catch (Throwable e) {
e.printStackTrace();
}
}
}
代码解析:htmlparser的使用,首先在项目中导入htmlparser.jar包,然后创建Parser类,可用通过文件导入,String类型数据创建(Parser parser = new Parser(file.getAbsolutePath());或parser = Parser.createParser(html, "GBK");)。
然后制定过滤规则。
标签过滤的方式有三种:
NodeFilter filter1 = new TagNameFilter("li");通过标签匹配需要需求的内容,本代码的意思就是匹配html标签为<li>的内容;
NodeFilter filter2 = new HasAttributeFilter("class","title_li");通过标签属性来匹配需求内容,本代码的意思是匹配html标签属性为class=title_li的内容;
NodeFilter filter = new AndFilter(filter1,filter2);匹配符合filter1和filter2两个过滤要求的内容,可以通过这
三种方式随意组合来精确定位目标文本内容,这三句代码组合过滤条件为匹配<li class="title_li" >的文本内容。
当
发现获取的文本还不是十分符合需要获取内容的要求时,可以将文本还原为html代码后,再次进行匹配。
当通过过滤器获取到nodeList后,通过htmlparser
接口能够获取匹配出来的html的父标签,子标签,兄弟标签及其自身文本等内容。附上内容获取的接口:
HTMLParser将解析过的信息留存为一个树的结构。Node是信息留存的数据类型基础。
请看Node的界说:
public interface Node extends Cloneable;
Node中包括的
要领有几类:
对付
树型结构进行遍历的函数,这些函数最轻易
理解:
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(欠好意思,英文是兄弟姐妹,直译太麻烦并且不相符
习惯,抱歉女同胞了)
Node getNextSibling ():取得下一个兄弟节点
取得Node内容的函数:
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page东西
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
用于Filter过滤的函数:
void collectInto (NodeList list, NodeFilter filter):基于filter的条件对付这个节点进行过滤,相符条件的节点放到list中。
用于Visitor遍历的函数:
void accept (NodeVisitor visitor):对这个Node应用visitor
用于修改内容的函数,这类用得比较少:
void setPage (Page page):设置这个Node对应的Page东西
void setText (String text):设置文本
void setChildren (NodeList children):设置子节点列表
其他函数:
void doSemanticAction ():执行这个Node对应的操纵(只有少数Tag有对应的操纵)
Object clone ():接口Clone的抽象函数。