贝叶斯过滤技术是非常有效的反垃圾技术。在Ruby中,有几个Library实现了贝叶斯过滤,可惜的是它们都不
支持中文分词。而mmseg则是比较流行的中文分词技术,在Ruby框架下,有rmmseg这个Library实现了mmseg分词法并自带了词库,非常方便。本文将这两种技术
结合在一起,使得在Ruby下可以获得支持中文的贝叶斯过滤器。
安装及试用classifier
首先来通过简单的使用来熟悉一下贝叶斯反垃圾引擎,这里我们使用的gem叫做classfier,项目地址位于 "https://github.com/kitop/classifier":https://github.com/kitop/classifier
使用gem命令安装这个library:
sudo gem install classifier -v=1.3.3
Password:
Successfully installed classifier-1.3.3
1 gem installed
Installing ri documentation for classifier-1.3.3...
Installing RDoc documentation for classifier-1.3.3...
为了方便说明,所以明确指定了使用1.3.3这个
版本。但是这个版本有一个BUG,因此我们需要打个补丁。找到gem的安装目录:
gem list -d classifier
[b]*[/b]LOCAL GEMS[b]*[/b]
classifier (1.3.3)
Author: Lucas Carlson
Homepage: http://classifier.rufy.com/
Installed at: /Library/Ruby/Gems/1.8
A general classifier module to allow Bayesian and other types of
classifications.
我的gem位于/Library/Ruby/Gems/1.8, 因此我进入这个目录,找到gems子目录,里面应该有classifier-1.3.3/
找到lib/classifier/bayes.rb这个文件,在45行下面添加一行代码:
orig ||= 0
修改后代码如下所示:

这样,我们便装好了这个gem,打开irb玩玩看:
irb
>> require 'classifier'
=> true
>> checker = Classifier::Bayes.new('spam', 'not spam')
=> #<Classifier::Bayes:0x1010e9cd0 @total_words=0, @categories={:Spam=>{}, :"Not spam"=>{}}>
>> checker.train :not_spam, "It's a good day!"
=> {:"!"=>1, :it=>1, :"'"=>1, :good=>1, :dai=>1}
>> checker.train :spam, "buy buy buy!"
=> {:"!"=>1, :bui=>3}
>> checker.classify "What a lovely day~"
=> "Not spam"
>> checker.classify "Buy some apple?"
=> "Spam"
>>
可以看到贝叶斯引擎的原理是将句子拆分成词,并根据词频来进行归类判断,因此样本数量越大判断越准确。通过上面的
例子,我们可以看到classifier这个库是通过自然空格对英文句子进行断句分词,很遗憾这种方式并不适用于中文。
classfier与中文的不兼容性
我们通过一个例子来说明classifier与中文的不兼容性。首先创建一个txt文档,写入一些中文,可将文件保存为sample.txt:
sample.txt
人类在社会发展中,对于自然世界的认识和精神世界里的追求,源远流长,形成了巨大的精神财富,如文学、艺术、教育、科学等,这些以文字或符号加以记载和传播,就形成了我们所说的文化。历史上,尽管各民族的文化差异很大,但一项重大的科学成就,常常能够影响整个世界文化发展的进程。
进入irb终端,试着将classfier应用于这段文字:
irb
>> require 'classifier'
=> true
>> checker = Classifier::Bayes.new('spam', 'not spam')
=> #<Classifier::Bayes:0x1010e9c30 @total_words=0, @categories={:Spam=>{}, :"Not spam"=>{}}>
>> File.open('sample.txt').each_line{ |s| p checker.train :not_spam, s
>> }
{:"\344\272\272\347\261\273..."=>1}
=> #<File:sample.txt>
>>
可以看到,classifier只生成了一个词频为1的大字串,把全段文字当成是一个
单词保存了起来,这段文字并没有被正确地拆成中文词语并进行正确的词频统计。原因在于classfier仅内置了英文的拆词法,即通过空格来拆分单词,这样的方式显然是无法用于中文的,因此为了能让中文内容也用上classifier库,我们首先要做的是使其能将中文段落正确的拆成词,RMMSeg的用处就在这里。
RMMSeg的安装及使用
而mmseg是很流行的中文分词
算法,在ruby下有中文分词器的实现RMMSeg,使用它的好处是它完全用ruby实现,并且自带词库,十分方便。我们先来了解一下如何使用这个分词器,首先是用gem来安装它:
sudo gem install rmmseg
成功安装后,我们仍然可以通过IRB试用下这个library。进入irb终端,测试一下RMMSeg是否可以正常工作,仍然使用前面创建的中文文件sample.txt来做测试:
irb
>> require 'rmmseg'
=> true
>> include RMMSeg
=> Object
>> File.open('sample.txt').each_line{ |s| p segment(s) }
["人类", "在", "社会", "发展中", ",", "对于", "自然", "世界", "的", "认识", "和", "精神世界", "里", "的", "追求", ",", "源远流长", ",", "形成", "了", "巨大", "的", "精神", "财富", ",", "如", "文学", "、", "艺术", "、", "教育", "、", "科学", "等", ",", "这些", "以", "文字", "或", "符号", "加以", "记载", "和", "传播", ",", "就", "形成", "了", "我们", "所说", "的", "文化", "。", "历史上", ",", "尽管", "各民族", "的", "文化", "差异", "很大", ",", "但", "一项", "重大", "的", "科学", "成就", ",", "常常", "能够", "影响", "整个", "世界文化", "发展", "的", "进程", "。"]
=> #<File:sample.txt>
可以看到,通过RMMSeg的segment命令,一段中文文字被切成了词。接下来的工作,是改造classifier库的断字部分,让它使用RMMSeg提供的中文断字能力。
改造classifier,集成RMMSeg,使之支持中文分词
classifier的分词代码位于其函数库根目录的lib/classifier/extensions/word_
hash.rb中。我们打开这个文件,在代码一开始添加:
require 'rmmseg'
include RMMSeg
然后找到word_hash这个函数,将基于空格的分词方法改成RMMSeg给出的segment方法进行分词:
def word_hash
#word_hash_for_words(gsub(/[^\w\s]/,"").split + gsub(/[\w]/," ").split)
word_hash_for_words(segment(gsub(/[^\w\s]/,"")) + gsub(/[\w]/," ").split)
end
修改后的代码如下所示:

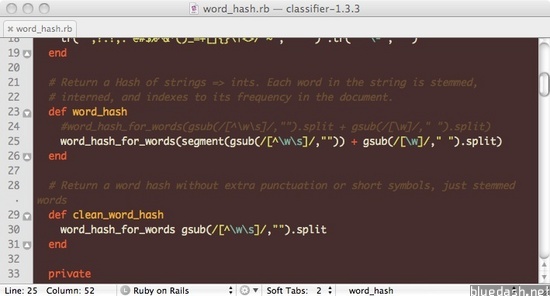
改造完成后,我们便可以用刚才的sample.txt重新做下测试,看看classifier是否可以针对中文正常工作了:
irb
>> require 'classifier'
=> true
>> checker = Classifier::Bayes.new('spam', 'not spam')
=> #<Classifier::Bayes:0x10109c318 @categories={:Spam=>{}, :"Not spam"=>{}}, @total_words=0>
>> File.open('sample.txt').each_line{ |s| p checker.train :not_spam, s
>> }
{:重大=>1, :我们=>1, :科学=>2, :源远流长=>1, :发展中=>1, :世界文化=>1, :各民族=>1, :符号=>1, :如=>1, :认识=>1, :成就=>1, :所说=>1, :等=>1, :形成=>2, :,=>9, :发展=>1, :差异=>1, :加以=>1, :文学=>1, :和=>2, :常常=>1, :文化=>2, :这些=>1, :了=>2, :对于=>1, :进程=>1, :很大=>1, :记载=>1, :、=>3, :精神世界=>1, :人类=>1, :能够=>1, :。=>2, :以=>1, :巨大=>1, :自然=>1, :但=>1, :传播=>1, :艺术=>1, :里=>1, :在=>1, :影响=>1, :历史上=>1, :文字=>1, :精神=>1, :世界=>1, :一项=>1, :就=>1, :教育=>1, :追求=>1, :社会=>1, :整个=>1, :尽管=>1, :或=>1, :财富=>1, :的=>7}
=> #<File:sample.txt>
>>
可以看到,中文被正确地拆分并加以词频统计了。我们得到了一个支持中文的贝叶斯反垃圾引擎。
试用支持中文的classifier
接下来可以玩玩看classifier是否能正确区分开垃圾内容非垃圾内容了,我们分别创建一个垃圾内容样本spam.txt及非垃圾内容样本not_spam.txt:
spam.txt
咆哮体!伤不起!这就是咆哮体!!啊啊!!啊啊!!!有木有!!!有木有啊!!!!!
not_spam.txt
人类在社会发展中,对于自然世界的认识和精神世界里的追求,源远流长,形成了巨大的精神财富,如文学、艺术、教育、科学等,这些以文字或符号加以记载和传播,就形成了我们所说的文化。历史上,尽管各民族的文化差异很大,但一项重大的科学成就,常常能够影响整个世界文化发展的进程。
接下来创建一个待分检垃圾样本test.txt:
test.txt
老子两年前选了法语课!!!!!!!!于是踏上了尼玛不归路啊!!!!!!!!!!谁跟老子讲法语是世界上最油煤的语言啊!!!!!!!!尼玛听的哪个外太空的法语啊!!!!!!!!!!!跟吐痰一样一样一样的啊 有木有!!!!!!!!!谁再跟老子讲法语是世界上最油煤的语言 老子一口浓痰咸死你啊!!!!!!!!!!!!!!!
我们会将spam.txt里面的内容标记为垃圾内容,将not_spam.txt里面的内容标记为非垃圾内容。而test.txt里面的内容是待测试内容,我们期待的结果是classifier将其识别为垃圾内容,即Spam。下面是测试过程及结果:
irb
>> require 'classifier'
=> true
>> checker = Classifier::Bayes.new('spam', 'not spam')
=> #<Classifier::Bayes:0x10109c1d8 @categories={:Spam=>{}, :"Not spam"=>{}}, @total_words=0>
>> File.open('spam.txt').each_line{ |s| p checker.train :spam, s }
{:伤=>1, :木=>2, :不起=>1, :这就=>1, :咆哮=>2, :是=>1, :体=>2, :啊=>5, :!=>17, :有=>4}
=> #<File:spam.txt>
>> File.open('not_spam.txt').each_line{ |s| p checker.train :not_spam, s }
{:重大=>1, :我们=>1, :科学=>2, :源远流长=>1, :发展中=>1, :世界文化=>1, :各民族=>1, :符号=>1, :如=>1, :认识=>1, :成就=>1, :所说=>1, :等=>1, :形成=>2, :,=>9, :发展=>1, :差异=>1, :加以=>1, :文学=>1, :和=>2, :常常=>1, :文化=>2, :这些=>1, :了=>2, :对于=>1, :进程=>1, :很大=>1, :记载=>1, :、=>3, :精神世界=>1, :人类=>1, :能够=>1, :。=>2, :以=>1, :巨大=>1, :自然=>1, :但=>1, :传播=>1, :艺术=>1, :里=>1, :在=>1, :影响=>1, :历史上=>1, :文字=>1, :精神=>1, :世界=>1, :一项=>1, :就=>1, :教育=>1, :追求=>1, :社会=>1, :整个=>1, :尽管=>1, :或=>1, :财富=>1, :的=>7}
=> #<File:not_spam.txt>
>> File.open('test.txt').each_line{ |s| p checker.classify s }
"Spam"
=> #<File:test.txt>
>>
可以看到,test.txt中的内容按照预期被识别为垃圾内容。
参考资料
http://www.iteye.com/news/1380 - robbin写的rmmseg介绍
https://github.com/logankoester/classifier - classifier项目网址
http://rmmseg.rubyforge.org/ - rmmseg文档
http://baike.baidu.com/view/4169613.htm - 咆哮体

- 大小: 45.2 KB

- 大小: 53.2 KB

- 大小: 50.7 KB




