���������ж�����Ӱ��Ƚϴ�Ļ����У����л�[4, 7, 10, 13]����������[2, 3, 8, 9, 14]�����紫��[5, 6, 11, 12]�����ĺ������ݽ����ؽ�����3�����֡�
Java ������õļ�����������л�������class="Apple-converted-space">?Kryo?Protostuff?FST?Jackson?Fastjson��ֻ��Ҫ����һ�� Benchmark��Ȼ�����5�����л�������ѡ��������ߵ��Ǹ������ˡ�DSL-JSON?ʹ���������ڷ��������ڿ���֮�С�Colfer?Protocol?Thrift?��Ϊ����Ԥ�ȶ��������ļ���ʹ������̫�鷳�����Բ��ڿ���֮�С����� Java �Դ������л������������Ϊ�������ⱻ���������������Ҳ�����ǡ�����ı����г����ڿ���֮�е�5�����л����������ܡ�
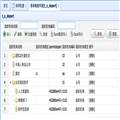
User?���л�+�����л� ����
framework thrpt (ops/ms) size protostuff 1654 240 kryo 1288 296 fst 1101 263 jackson 959 385 fastjson 603 378����15��?User?��?Page?���л�+�����л� ����
framework thrpt (ops/ms) size kryo 143 2080 fst 118 3495 protostuff 98 3920 jackson 71 5711 fastjson 40 5606����� benchmark �п��Եó���ȷ�Ľ��ۣ�������Э���� protostuff kryo fst Ҫ���ı�Э��� jackson fastjson ���������ƣ��ı�Э���У�jackson(������afterburner) Ҫ�� fastjson �����Ե����ơ�
��ȷ�����ǣ�3��������Э�鵽���ĸ�����һЩ���Ͼ� �ٶ� �� size ���� RPC ������Ҫ��ֱ���� kryo ���������ѡ���� kryo Ҳ���ܸ�����ϵͳ���������������ջ��Ǿ�������3����ⶼ������ѡ��ͨ�����ɴ���ģ���� Benchmark ������ѡ���ĸ���
framework existUser (ops/ms) createUser (ops/ms) getUser (ops/ms) listUser (ops/ms) protostuff 103.92 89.50 83.33 21.17 kryo 99.23 76.71 73.89 25.68 fst 102.33 76.24 78.81 23.30���յĽ��Ҳ���Ǹ���ǧ�����Ծ�������?Turbo?������ protostuff �� kryo ��ʵ�֣��������û������滻Ϊ�Լ���ʵ�֡�

���õ� ��̬�������� �����У�Reflection ClassGeneration MethodHandle��Reflection ������ϵļ�������˵���ܲ��ѡ�ClassGeneration ��̬�����ɣ���ԭ����˵Ӧ���Ǹ�ֱ�ӵ���һ�������ܡ�MethodHandle �Ǵ� Java 7 ��ʼ���ֵļ�������˵�ܴﵽ��ֱ�ӵ���һ�������ܡ�ʵ�ʽ�����£�
type thrpt (ops/us) direct 1062 javassist 920 methodHandle 430 reflection 337���۷dz����ԣ�ʹ�������ɼ�����?javassist?��ֱ�ӵ��ü���һ�������ܣ�����?javassist?�ˡ�
MethodHandle ���ֲ�û����������ô�ã���ô���£�ԭ�� MethodHandle ֻ������ȷ֪������ �������� �������� ������²��ܵ��ø����ܵ� invokeExact(Object... args)�������������ʺ���Ϊ��̬���õķ�����
As is usual with virtual methods, source-level calls to invokeExact and invoke compile to an invokevirtual instruction. More unusually, the compiler must record the actual argument types, and may not perform method invocation conversions on the arguments. Instead, it must push them on the stack according to their own unconverted types. The method handle object itself is pushed on the stack before the arguments. The compiler then calls the method handle with a symbolic type descriptor which describes the argument and return types.
refer:?https://docs.oracle.com/javase/7/docs/api/java/lang/invoke/MethodHandle.html
Netty?�Ѿ���Ϊ��ʵ�ϵı���������������Ŀ����ʹ�õĶ���?Netty��Mina?Grizzly?�Ѿ�ʧȥ�г�������Ҳ�Ͳ��ÿ����ˡ�����Ҳ��������ô������Aeron?�������dz���?Netty?����һ�������ľ������֡�Aeron?��һ���ɿ���Ч�� UDP ���� UDP �ಥ�� IPC ��Ϣ���ݹ��ߡ���������Ϣ�����еĹؼ���Aeron?�����ּ�ڴﵽ �������� �Ϳ��� �� ���ӳ���ʵ��Ч����������أ����ź�����?RPC Benchmark Round 1?�еı���һ�㡣�����������Ŷ���ͨ������ȷ�������Գ��� 64k ����Ϣ���� zero-copy �������Ҿ����������?Aeron?���ֲ��ѵ�һ��ԭ��Aeron?�������ʺ� С��Ϣ ���˵��ӳ� �ij��������������ڸ���ͨ�õ� RPC ������������ʱ��û�г����ܹ��� Netty һ�����µ�ͨ�����紫���ܣ��ֽ� Netty ��Ȼ�� RPC ϵͳ�����ѡ��
existUser �ж�ij�� email �Ƿ����
framework thrpt (ops/ms) avgt (ms) p90 (ms) p99 (ms) p999 (ms) turbo-rpc 107.05 0.28 0.40 0.87 4.06 netty 99.81 0.32 0.40 0.52 1.16 jupiter 73.07 0.44 0.66 1.49 2.92 undertow 70.38 0.45 1.16 2.17 32.48 turbo-rest 68.49 0.44 1.17 2.15 25.66 undertow-async 62.65 0.49 1.14 2.41 24.84 dubbo-kryo 57.35 0.53 0.67 1.02 11.65 rapidoid 52.96 0.61 1.32 2.51 25.07 dubbo 52.12 0.54 0.67 0.92 3.93 motan 44.96 0.71 1.15 2.47 33.39 aeron 43.46 0.90 1.32 5.10 14.29 grpc 38.97 0.84 1.07 1.31 6.06 thrift 27.25 1.59 0.16 64.87 122.83 hprose 26.24 1.26 1.53 2.01 8.34 springwebflux 22.39 1.42 2.27 3.19 17.20 springboot 12.54 1.68 2.38 13.63 33.20����������һ�� Dubbo ����Ϣ��ʽ
public class RpcInvocation implements Invocation, Serializable {
private String methodName;
private Class<?>[] parameterTypes;
private Object[] arguments;
...
}
����˵�Ƿdz��������ƣ�Client �����֪ Server Ҫ���õ� �������� �������� ������Server ��ȡ����3��������ͨ��?�������� com.alibaba.service.auth.UserService.verifyUser?��?�������� (String, String)?��ȡ�� Invoker��Ȼ��ͨ�� Invoker ʵ�ʵ��� userServiceImpl �� verifyUser(String, String) �������������ڶ� RPC ���Ҳ����ȡ����һ������ơ�
���ǣ�������ȷ�������𣿵�Ȼ���ǣ����������dz��˷ѿռ䣬ÿ��������Ϣ��Ĵ���ڴ�����Ӧ������������ӡ� public boolean verifyUser(String email, String pwd) ���µ��ڴ沼�֣�
|com.alibaba.service.auth.UserService.verifyUser|java.lang.String,java.lang.String|ʵ�ʵIJ���|
����µģ��˷��� 80 byte ������ ���� �� ��������û�б� http+json �ķ�ʽ��Ч���١�ʵ�ʵ�?���ܲ���?Ҳ֤������һ�㣬undertow+jackson Ҫ�� dubbo motan �ijɼ���Ҫ�á�
��ʲô������ȷ��������Turbo?����Ϣ��ʽ�������˷dz���ĸı䡣
public classRequestimplementsSerializable{
private int requestId;
private int serviceId;
private MethodParam methodParam;
...
}
public boolean verifyUser(String email, String pwd) ���µ��ڴ沼�֣�
|int|int|ʵ�ʵIJ���|
��Ч���ˣ�ֻ���� 4 byte �������� ���� �� ���� �Ķ��塣����С�� �������� �� size��ͬʱ int ���͵� serviceId Ҳ������ Invoker �IJ��ҿ�����
���������ͬѧ���ܻ��ʣ�������ҪΪÿ����������һ��Ψһ id �� ���Dz���Ҫ�ģ�Turbo?�������һ���⣬����ο�?TurboConnectService?��
MethodParam?����?Turbo?����ը�ѵ�����ԭ�������ԭ�������� ClassGeneration ��ÿ�� Method ������һ��MethodParam?�࣬���ڶԷ��������ķ�װ���������ĺô��У�
//���� test(long id, int value) ������������� MethodParam ��:
public class TestService_test_2_MethodParam implements MethodParam {
private long id;
private int value;
public long $param0() { return this.id; }
public int $param1() { return this.value; }
//... getters and setters
function">publicTestService_test_2_MethodParam(long id, int value){
this.id = id;
this.value= value;
}
}
�� RPC ��ܵ� ���л� �����л� ���̶���Ҫһ���м�� bytes
��?Turbo?�������м�� bytes��ֱ�Ӳ��� ByteBuf��ʵ���� ���л� �����л� �� zero-copy���������� �ڴ���� �ڴ渴�� �Ŀ���������ʵ����ο�?ProtostuffSerializer?��?Codec��
������֪���ͺ���֪�ֶΣ�Turbo?���������� �ֹ����л� �ֹ������л� �ķ�ʽ���������Խ�һ���������ܿ�����
�����ļ��� ObjectPool ʵ�����ܶ��ܲ���������׳�Ϊ����ƿ����Stormpot?����ǿ������������ż�����������⣬��������Ҳֹͣά���ˡ�HikariCP?���ܲ����������䱾����һ�����ݿ����ӳ������� ObjectPool �������֡��ҵĽ����Ǿ�������ʹ�� ObjectPool��ת��ʹ���������������Ҫ���� Netty �� Channel ���߳���ȫ�ģ�������Ҫʹ�� ObjectPool ��������ֻ��Ҫһ�����������洢 Channel���õ�ʱ��ʹ�� ���ؾ������ ѡ��һ�� Channel ���������ˡ�
framework thrpt (ops/us) ThreadLocal 685.418 Stormpot 272.934 HikariCP 139.126 SegmentLock 19.415 Vibur 4.668 CommonsPool2 1.107 CommonsPool 0.276���������Ĺؼ������Ż���Turbo?�����˴������������Ż�
��������ݽ�������������Ϊ��Ҫ�Ķ���������������ֱ�Ӳ鿴 Turbo Դ��