 class="topic_img" alt=""/>
class="topic_img" alt=""/>
文/观察者网专栏作者·陈经
2017 年 12 月 6 号,Deepmind 扔出了一篇论文《Mastering Chess and Shogi by Self-Play with a General Reinenforcement Learning Algorithm》,声称从 AlphaGo Zero 发展来的新程序 AlphaZero 又零基础自学,只用 4 个小时和 2 个小时就胜过了国际象棋和日本将棋的最强程序。加上之前在围棋上的进展,这其实等于是说,世界上所有知名棋类都可以用一个架构轻松碾压过去的高手,不管是人还是程序。
这篇文章正在被审核,按 Deepmind 过去的风格有可能还是投到《自然》去。但这回 Deepmind 不保密了,直接在 arxiv.org 公布了全文。前两篇围棋 AI 的文章由于投出来之后有人机大战,是需要保密。
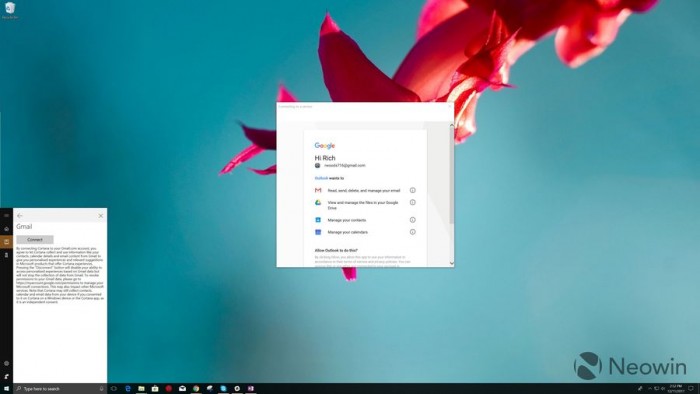
这篇文章在围棋上,用训练 34 小时的 AlphaZero 和训练 72 小时的 AlphaGo Zero 相比,100 盘 60:40。这个结果并不令人吃惊,就是训练速度快了,说明新的方法有提升,其实网络架构训练方法和 AlphaGo Zero 的差不太多,是一些小改进。围棋界对这篇文章应该反应不大,新东西不多,早就被震惊好几次了。
AlphaZero 在日本将棋上训练 2 小时就超过最强程序 Elmo。日本将棋和中国象棋、国际象棋差不多,也是各兵种吃对方的王。但是最大的不同是吃掉对方的棋子可以变成本方的棋子,放回棋盘任意位置,这使得对局攻杀极为激烈,和局很少,变化比国际象棋要多不少。中国象棋的理论局面数量超过国际象棋,但由于大量局面类似,高手们一般认为实际变化复杂程度比国象要少。
由于日本将棋更为复杂(以及研究人员关注的少),直到 2017 年冠军程序 Elmo 才战胜了人类高手。这个 Elmo 应该实力还比较弱,所以最终被 AlphaZero 以 90 胜 2 和 8 负战胜了。AlphaZero 还会输几局,但这是因为训练时间不长,已经能够说明问题就行了。
真正影响重大的是国际象棋。这次倒不是说 AlphaZero 怎么碾压了人,人类高手早就被国际象棋 AI 整得服气了。但是 AlphaZero 训练 4 小时就反超了,最终以 28 胜 72 和战胜了 Stockfish(鳕鱼),其中先行战绩是 25 胜 25 和。这个 Stockfish 在国际象棋界可不是随便搞搞研发的程序,也不仅是 2016 年国象 AI 冠军这么简单,它对职业棋手和爱好者们就像是亲人朋友一样,天天在为棋界服务。在 chessbomb 等网站上,职业棋赛每一步 Stockfish 都在实时地给出各种变化,爱好者们看棋的方式和以前完全不一样了。高手们训练也非常依赖顶级 AI 给出的各种提示,有时就像终极答案一样。高手们通过亲身感受,对于 Stockfish 的实力非常认可。
由于国际象棋最优解极有可能是和棋,所以高手和爱好者一般认为,Stockfish 和国际象棋上帝也差不了太多,反正就是和棋。以前两个顶级 AI 对打(通常是大战 100 盘),总有 90% 的是和棋。排名世界前五的美国特级大师中村光就说:就算是上帝先手和 Stockfish 下,也得 75% 是和棋。
现在 AlphaZero 忽然跑出来,先行能以 50% 的概率战胜 Stockfish,这让一些国际象棋高手和爱好者们有些难以接受。我对围棋很熟,AlphaGo 对围棋界的冲击可以说是天翻地覆无以伦比。现在轮到国际象棋界来感受新型 AI 的冲击了,看着一些国外爱好者对 AlphaZero 的讨论,各种置疑或者不接受,不由得一阵暗爽。
Stockfish 和 AlphaZero 都是机器,不管谁强谁弱,和人都没啥关系,为什么国际象棋界的人要着急?这里有一些算法背景。
Stockfish 是机器,但是里面的算法是人们一步步看着发展过来的,程序员写了很多代码,每年都在不断升级,还有国际象棋大师出主意。棋界和计算机学界一起努力,才达到了非常高的水平,那一行行代码都开源在那,还有规模极大的开局库、残局库放在那帮着简化搜索。这都是业界的心血,那些精巧的 alpha-beta 搜索、剪枝算法、高效实现,各种知识库,有多少人的聪明才智在里面。业界其实对以 Stockfish 为代表的国际象棋 AI 比较满意,开发出来的程序又帮助棋手们涨棋,促进了国际象棋界的繁荣,职业棋手数量和水平都大大增加。
各种 AI 们自己在那对战,Stockfish 前几天就正在和 Komodo 大战。但棋迷和高手们主要还是对人类对局有兴趣。这个局面是不错的,AI 们自己玩,玩出东西来帮助人涨棋以及评化棋局,人不和 AI 较劲。
但是现在 AlphaZero 等于是说,人类之前开发 AI 的所谓“心血”都是没意义的白忙活。弄好一个 resnet 神经网络结构,把国际象棋基本规则做好了,来 5000 个一代 TPU 对局生成样本,再来 64 个二代 TPU 训练,过 4 小时就行了。
人类大师 1000 多年发掘的象棋精妙知识不需要,算法大师构造的精妙剪枝搜索不需要,也不要任何开局库残局库。就这么一个结构,还同时可以搞定围棋、日本将棋、国际象棋,区别只是训练出来的神经网络系数不同。




