原文:https://blog.markvincze.com/troubleshooting-high-memory-usage-with-asp-net-core-on-kubernetes/
ps:我不是死板翻译原文的,尽量的通俗一点,如有不对欢迎指出,谢谢哈。
在生产环境中,我们把asp.net core api应用通过Kubernetes 部署在了Google Cloud (GCE—Google Container Engine)。我们发现大多数的组件(core应用)的内存使用率都不合理。我们把应用的内存限制设置成了500MB, 并且还发现了很多api应用实例因为超过了内存限制而被Kubernetes 不断的重启(应该docker设置了--restart)。
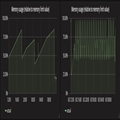
下面2张图是我们其中的2个api,当Kubernetes重启他们时,你会发现他们先是一直增长,然后到达了内存限制的点。
针对于这个现象我们花了很多时间来调查这个issue,期间尝试过通过抓dumps来分析,但是并没有发现问题所在。
我们也尝试使用多种方式,在我们的开发环境来复现这个问题:
但是上述环境下,他们都没有超过500mb的内存使用情况,都是增长到100-150mb左右就停止了。
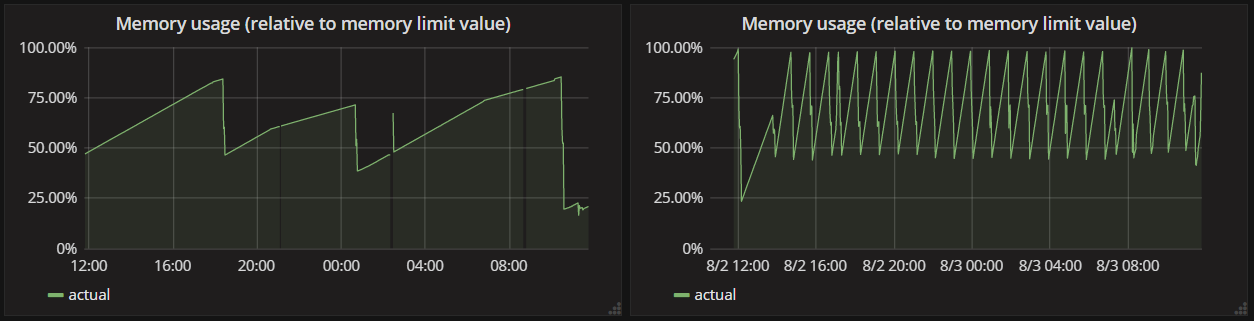
期间,为了减轻容器因为超过限制的最大内存而频繁重启我们将内存限制从500mb增加到1000mb,在此之后,有趣的是内存的使用情况变得如下图所示:
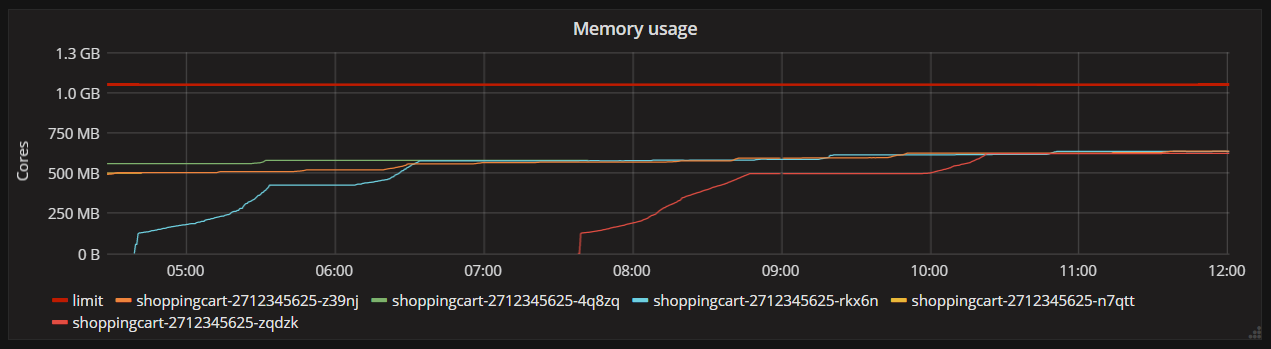
测试下来发现内存的使用并不是无限制的增大的,但是也是封顶600mb左右,并且这个数字在不同的容器实例以及实例重启之后近乎保持一致。
这个现象清楚的表明我们的容器中的应用并没有内存泄漏,只是有一块内存被分配了而没有得到释放。所以我开始把关注点转移到“运行在Kubernetes的.net程序是如何限制内存的“。
事实上Kubernetes最终也是将程序运行在docker容器中的,并且docker容器可以通过docker run --memory参数来限制内存的使用。所以我怀疑也许是Kubernetes并没有传递任何有关内存限制的参数到docker容器实例中,所以.net程序理所当然的认为当前机器有好多好多的可用内存可以使用。
但是并不是这种情况,我们发现相反的内容(因为作者怀疑是Kubernetes没有传递和内存相关的参数)在the documentation.
The spec.containers[].resources.limits.memory is converted to an integer, and used as the value of the --memory flag in the docker run command.
(这句话的意思是Kubernetes的spec.containers[].resources.limits.memory会自动沿用docker run中的--memory参数所设置的整数值)
这似乎又到了另一个死胡同了。我也尝试在自己电脑里的docker中运行api程序,并且通过--memory参数传递多种内存限定值,但是1.我不能复现上述600mb内存使用的场景,内存只保持在150mb左右,2.也没有观察到容器实例运行的超过它的内存限制,即使我通过--memory参数来指定一个小于150mb的值,这个容器实例依然能够在这个更小的内存限定值下运行的完好。
很早的时候我也在github上提过一个关于内存泄漏的issue关联到Kestrel(core的一个基于libuv的新的服务器),并且在这一点上,Tim Seaward发了一个有趣的suggestion关于检查我的应用在不同环境下所打印出的cpu的个数,因为cpu的是影响内存使用的一个巨大因素。
我尝试在代码里通过Environment.ProcessorCount在不同的环境下打印出的数量如下:
4.1.8.这就能最终给我一个解释了,因为cpu的数量真的会影响内存的使用数量。cpu核数越多,内存使用量也就越多(对于作者来说,他还不是确切的了解gc的类型,cpu的核数,与.net程序所使用内存的大小之间的关系,虽然this post这个链接包含了有关GC的资料)。
最终的建议呢,就是把GC模式从Server GC(服务器模式)切换到Workstation GC(模式),这样就能达到低内存使用率的优化效果。只需要在csproj项目文件中做如下动作:
class="language-xml hljs"><PropertyGroup>
<ServerGarbageCollection>false</ServerGarbageCollection>
</PropertyGroup>
做了这个改动后,重新发布我的api,结果就如乡下所示(蓝色的线):
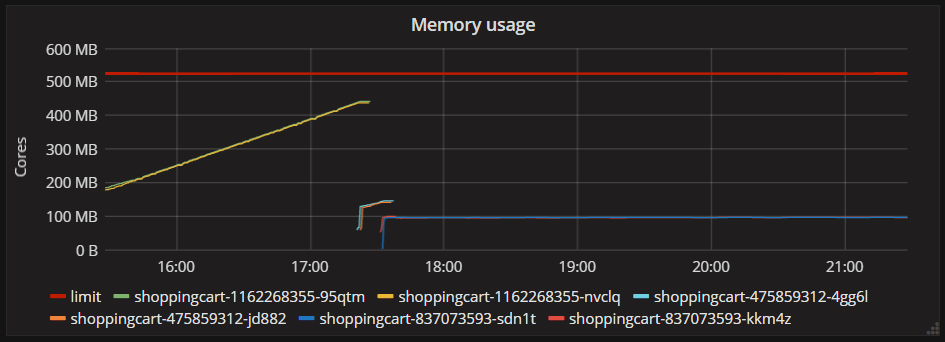
workstation gc模式使得应用对于内存的使用变得更加”保守“,并且内存的使用从大约600mb降低到了100到150mb之间。假设工作站模式是通过牺牲一些性能和吞吐量来实现这个”600mb到150mb的效果“话(据官当服务器模式在某些场景下是相对优于工作站模式的),但是迄今为止我并没有发现任何api速度和吞吐量的衰减,虽然我的这个api并不是一个对性能有着及其苛刻的要求。
通过这个故事总结到:OS,可用内存,cpu核数都是定位内存问题的关键因素,因为他们会大量影响想着.net的GC。如果你被问题卡住了,请不要犹豫的把问题抛出来,并且在很多.net 社区里面有很多极好的人会很乐于助人。
=============================================分割线========================================
小弟我们公司下的项目也是这个问题,当时困扰了好久,为什么呢,因为之前在windows下面,内存占用不会”太明显“,因为GC起到了决定性的作用,但是在core的环境下,在加之docker+linux,遇到这样的时当时一度怀疑是docker的问题,当时也没有像这位国外友人这样去分析这个问题。通过这个问题我学到了如下:
1.学到了这位老哥定位思考问题的步骤,从是否是k8s的问题-》多环境问题-》github issue-》自己动手去类比推测-》最终解决问题。
2.GC的知识点补充:this post
3.除此之外还有很多知识点都隐藏到了:suggestion(希望大家仔细再看看)
4.我没记错的之前英文的官档里,讲项目配置文件的一节中提到了GC的配置
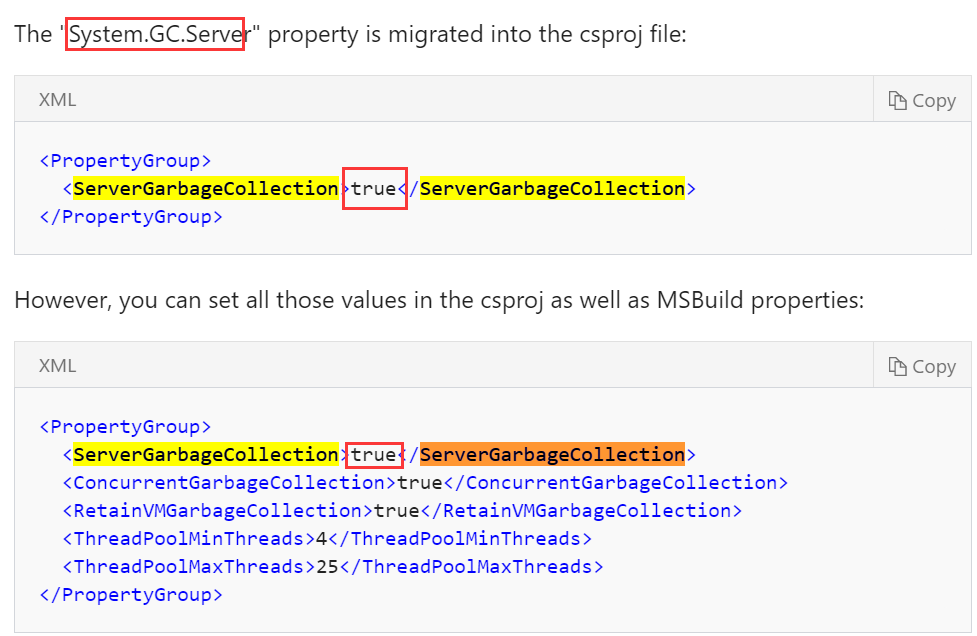
一开始(对GC的2种类型还不了解的情况),正常人看到这个true指的是激活该应用程序的GC垃圾回收,而并没有注意到老外所调查的结果(true其实是指的激活服务器GC模式,false不是指不GC,而是指的使用工作站GC模式),我能说微软是否能够稍微“贴心点”指出true和false的真正区别(其实是我们自己.net研究的还不够透彻,哈哈哈),这样就不会有像我,像这个老外一样,对于跑在docker容器里的core应用内存占用率过高而表示“质疑”。
ps:我们生产已改成false,当然true也没问题,只不过服务器内存被“只吃不拉”而已。
最后希望大家多多支持core,为张大大打个广告:微信公众号搜索”opendotnet“进行关注,知识共分享。