class="topic_img" alt=""/>
class="topic_img" alt=""/>
百度硅谷 AI 实验室最近推出强文,文中提出了一种被称为 GNR(Globally Normalized Reader)的方法。据雷锋网了解,该方法相比起之前的方法,其优势在于能够在保持问答抽取(Extractive question answering)任务性能不变的前提下,大大降低计算复杂度。当前许多的流行的模型,比如说双向注意流(Bi-Directional Attention Flow),都采用了代价昂贵的注意力机制和其它的诸如 Match-LSTM 来明确得到所有候选答案。
相比之下,GNR 将问答过程转化成检索问题,然后通过一个学习搜索框架(Learning to search framework)来解决该检索问题。通过在斯坦福的 SQAD 数据集上进行测试,最终结果表明,GNR 模型比双向注意流快出了 24.7 倍,并且取得了模型排名第二的好成绩。
当前所有最新的基于神经网络的问答系统总是避免不了过拟合问题。为了解决这一问题,研究员们同时还提出了类型交换(Type Swaps)技术,这是在神经问答(Neural question answering)研究领域中第一个取得成功的数据增强(Data augmentation)技术。使用通过类型交换技术产生的增强数据,能有效地减少 GNR 模型的泛化误差,并且在 SQuAD 数据集实现了1% 的 EM 增益。
转问答为检索
假设我们想要回答这么一个问题——“尼古拉·特斯拉在哪年死亡的?”。我们也许会浏览维基百科然后找到相关的文章:
尼古拉·特斯拉(塞尔维亚西里尔语:НиколаТесла; 1856 年 7 月 10 日至 1943 年 1 月 7 日)是一位塞尔维亚美国发明家,电气工程师,机械工程师,物理学家和未来学家,以为现代交流(AC)电力供应系统设计作出的贡献而闻名。
问答(QA)和信息抽取系统已经被证明了在各种各样的场景中都具有非常高的应用价值,例如药物和基因的医疗信息收集[4],大规模健康影响研究[5]或者教育资料汇编(Educational material development)[6]。最近,基于神经网络的问答抽取模型在诸如 SQuAD[3]、MSMARCO[7]或 NewsQA[8]等几个基准 QA 任务中的表现正在迅速地接近人类的水平。然而,当前的问答抽取方法也正面临着以下几个瓶颈:
无论正确答案位于何处,模型都需要均等地遍历计算整个文档,无法忽略或者专注于某些特定部分。这将限制模型在更长更大文档中的性能表现。
它们广泛依赖于代价昂贵的双向注意力机制[1],或者必须排列所有候选答案[17]。
尽管针对问答任务的数据增强方法已经被提出了[18],但是该方法依然无法为现有的系统提供能够提升性能表现的训练数据。
研究员们提出了将问答抽取转化为迭代搜索问题(Iterative search problem)进行处理:挑选出与答案有关的句子,开始单词和结束单词。在每个步骤中,都将修剪搜索空间,这样算法才能将计算力放在最重要的地方:更有希望的搜索路径。
实验表明,通过波束搜索(Beam search)在全局范围内归一化决策过程和反向传播将使得表征变得可行以及提高学习效率。文中所提理论通过实验进行了经验性的论证,该算法在斯坦福的问答数据集[3](68.4 EM, 76.21 F1 dev)上取得了单一模型排名第二的成绩,并且计算速度比双重注意力流[1]快出了 24.7 倍。
文中还提出了一种数据增强的方法,通过将命名实体与知识库进行对齐并将它们与相同类型的新实体进行交换从而生成语义有效的新样本(Semantically valid examples)。该方法提高了本篇论文中提及的所有模型的性能,并且对于各类 NLP 任务具有各不相同的提升效果。
GNR 是如何“阅读”的?
为了更好地描述 GNR 算法,让我们先来考虑一个简单的样例“是谁首先意识到分析引擎(Analytical Engine)的应用超出了纯粹的计算?”。为了回答这个问题让我们先阅读下边的一段引文:
Ada Lovelace 因为她在 Charles Babbage 的分析引擎中所做的工作而闻名于世。她是第一个意识到机器不单单只是一个计算工具的人。因此,她经常被当做是第一个认识到“计算机”潜力的人和第一名计算机程序员。
文中并不是所有内容都与问题相关。为了反映出这一点,我们可以提前检测答案可能出现在哪里。GNR 通过逐步选择文档的子部分来表现出这种直觉。下面将采用垂直条块展示决策的概率,并将条块悬停在一个节点上以突出显示对应的文档部分。
这里的问答抽取问题是从所给的文章中抽取死亡日期“1943 年 1 月 7 日”。GNR 将问答转化为搜索问题。所以首先,算法会找到包含有正确答案的语句。然后,找到句子中与答案有关的起始单词。最终,找到答案的结束单词。该过程如下所示:
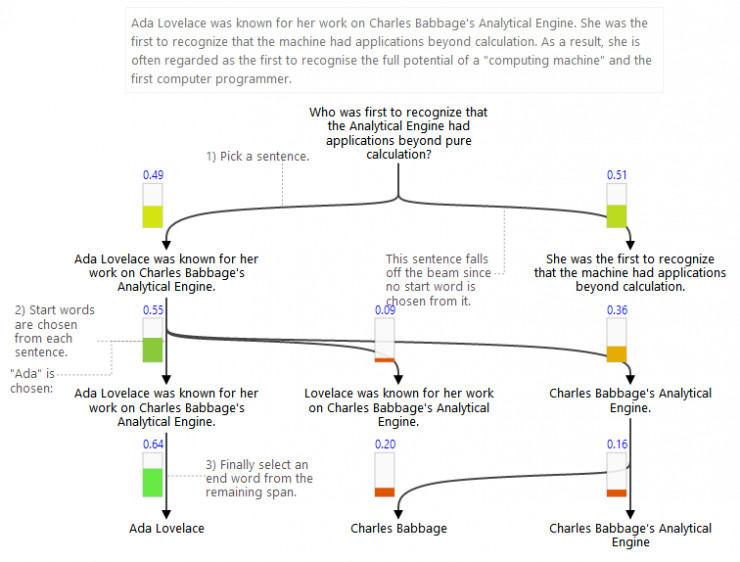
一旦读者在文档中选择了相关的句子,算法就可以在该文档的该子部分进一步深入分析。在下面的图表中,可以看到算法如何将注意力集中在其中一个句子上,然后选择出了句子中正确的单词子集:
有许多的方法可以用来参数化句子、起始单词和结束单词选择的概率分布。而 GNR 的一个关键因素是采用全局(而不是局部)归一化的方式参数化概率分布。
在全局归一化模型(Globally normalized model)中,分布对所有的(句子,起始单词,结束单词)元组进行归一化。而在局部归一化模型(Locally normalized model)中,每个句子、起始单词和结束单词的选择都被单独归一化然后通过链式法则进行相乘。
全局归一化使得模型更具表现力,并且使得其能够更容易地从搜索错误中恢复。在这项工作中,展示了通过使用全局归一化使得模型在 EM 上取得了1% 的提升,并且使得模型的性能更加接近于当前的最佳模型。
如果想获得更多与全局归一化有关的细节内容,请参阅[9]中的详细介绍。
学习搜索(Learning to search)
尽管全局归一化模型拥有很好的表征能力,但是同时也带来了计算上的挑战。特别的,评估任何特定(句子,起始单词,结束单词)元组的概率都需要对所有这样的元组进行代价昂贵的求和计算来获得归一化常数,亦即,对一组大小为#句子*#起始单词*#结束单词进行求和。但是对于一篇长文,这样的计算量是不被允许的。
为了克服这一挑战,本文作者采用了波束搜索。特别地,通过对最终波束候选进行求和来近似所有的元组的和。这个方法,也被称为学习搜索,要求我们在训练的时候通过波束搜索进行反向传播。
在测试时,排位最高的候选元组也是通过波束搜索获得的。这意味着该模型只需要对O(波束大小)个候选答案进行评分,而不是按照现有最常见的模型需要对所有可能候选进行评分。该过程缩小了模型训练与评估方式之间的差异,并且是使得 GNR 取得 20 多倍计算加速的关键改进。
学习搜索成功在哪?
许多关于学习搜索(Learning to search)的方法已经被提出,这些方法针对各种各样的 NLP 任务以及条件计算(Conditional computation)。最近,[9]和[10]证明了全局归一化网络和使用波束搜索进行部分语音标记(Part of speech tagging)和基于过渡的依赖解析(Transition-based dependency parsing)的训练的有效性,而 Wiseman 等人在 2016 年的工作[14]表明这些技术也可以应用于基于序列到序列模型(Sequence-to-sequence models)的几个应用领域,比如机器翻译。这些工作集中于解析和序列预测任务,并且具有固定的计算而不考虑搜索路径,而本文的工作则表明相同的技术可以直接应用于问答,并且可以扩展以允许基于搜索路径的条件计算。
在[12]的图像摘要(Image captioning)工作中,学习搜索也已经被用于具有条件计算的模块化神经网络的上下文中。在他们的工作中,强化学习被用来学习打开和关闭计算,而我们发现条件计算可以很容易地进行学习,如果有最大似然和早期一些方法[9, 10, 13]来指导训练过程。
下一步
本文的作者认为当前存在着大量的结构化预测问题(代码生成,图像、视频和音频的生成模型),其中由于原始搜索空间过大而使得当前的技术难以处理。但是如果用条件计算作为学习搜索问题,则有可能实现。
如何生成准无限(quasi-infinite)数据?
几乎所有的最新的基于神经网络方法的问答模型在 SQuAD 任务中均面临着过拟合的问题,并且需要采用非常严格的归一化才能获得较好的结果。在机器学习的其它领域,如图像或语音识别,研究员已经能通过数据增强的方式来提高模型的泛化能力。但是到目前为止,还没有人提出一种能提高问答任务性能的数据增强策略。为了解决这个问题,该项工作中提出了类型互换(Type Swaps)策略。这是一种全新的策略,可用于生成大量的合成问答样本,并且通过实验证明类型互换策略可以提高 GNR 的性能。
类型互换通过识别文档和问题汇总的实体,然后利用 WikiData 交换相同类型的新实体。由于 Wikidata 包含有大量的实体,因此我们可以生成的新样本数量接近于天文数字。有关于更多技术细节,请参见图中的示例和论文。
论文中还发现使用额外的类型敏感的合成样本(Additional type-sensitive synthetic examples)来增强数据集可以提高论文中所研究的所有模型的性能,并且这种提升在 GNR 模型上尤为显著,最高可以提高2% 的 EM。由于这种改进来源并不与我们的架构选择有关,所以这些增益预计能够转移到不同的模型[1,14,15],也可能更广泛地适用于其它包含命名实体以及数量有限的监督数据的自然语言任务中。
类型互换策略提供了一种方法,将问题的性质和命名实体的类型结合到 GNR 模型的学习过程中,从而降低了模型对表面变化(Surface variation)的敏感性。迄今为止,基于神经网络方法的问答抽取已经忽视了这一信息。使用额外的类型敏感合成样本来增强的数据集通过覆盖更全面的、不同的答案类型来提高性能。增加使用的增强样本数量可以提高所研究的所有模型性能。
不过当增强数据超过了一定的数量,还会导致性能的下降。这表明尽管在数据增强过程中增强策略努力去尝试模仿原始的训练集,但是在生成的实例中存在训练测试不匹配或者过多重复的问题。
示例
为了更好地了解模型的行为,这里还提供了各种其它示例问题、文档和搜索树:
想获取更多示例,请移步官方网站浏览。
Via Globally Normalized Reader
Reference
Bidirectional Attention Flow for Machine Comprehension [PDF]
Seo, Minjoon and Kembhavi, Aniruddha and Farhadi, Ali and Hajishirzi, Hannaneh, 2016, arXiv preprint arXiv:1611.01603
Machine comprehension using match-lstm and answer pointer [PDF]
Wang, Shuohang and Jiang, Jing, 2016, arXiv preprint arXiv:1608.07905
Squad: 100,000+ questions for machine comprehension of text [PDF]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy, 2016, arXiv preprint arXiv:1606.05250
Distant Supervision for Relation Extraction beyond the Sentence Boundary [PDF]
Quirk, Chris and Poon, Hoifung, 2016, arXiv preprint arXiv:1609.04873
Influence of Pokemon Go on physical activity: Study and implications [PDF]
Althoff, Tim and White, Ryen W and Horvitz, Eric, 2016, Journal of Medical Internet Research
Data mining and education [PDF]
Koedinger, Kenneth R and D'Mello, Sidney and McLaughlin, Elizabeth A and Pardos, Zachary A and Ros{\'e}, Carolyn P, 2015, Wiley Interdisciplinary Reviews: Cognitive Science
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset [PDF]
Nguyen, Tri and Rosenberg, Mir and Song, Xia and Gao, Jianfeng and Tiwary, Saurabh and Majumder, Rangan and Deng, Li, 2016, arXiv preprint arXiv:1611.09268
NewsQA: A Machine Comprehension Dataset [PDF]
Trischler, Adam and Wang, Tong and Yuan, Xingdi and Harris, Justin and Sordoni, Alessandro and Bachman, Philip and Suleman, Kaheer, 2016, arXiv preprint arXiv:1611.09830
Globally normalized transition-based neural networks [PDF]
Andor, Daniel and Alberti, Chris and Weiss, David and Severyn, Aliaksei and Presta, Alessandro and Ganchev, Kuzman and Petrov, Slav and Collins, Michael, 2016, arXiv preprint arXiv:1603.06042
A Neural Probabilistic Structured-Prediction Model for Transition-Based Dependency Parsing. [PDF]
Zhou, Hao and Zhang, Yue and Huang, Shujian and Chen, Jiajun, 2015, ACL (1)
Sequence-to-sequence learning as beam-search optimization [PDF]
Wiseman, Sam and Rush, Alexander M, 2016, arXiv preprint arXiv:1606.02960
Learning to compose neural networks for question answering [PDF]
Andreas, Jacob and Rohrbach, Marcus and Darrell, Trevor and Klein, Dan, 2016, arXiv preprint arXiv:1601.01705
Incremental parsing with the perceptron algorithm [PDF]
Collins, Michael and Roark, Brian, 2004, Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics
FastQA: A Simple and Efficient Neural Architecture for Question Answering [PDF]
Weissenborn, Dirk and Wiese, Georg and Seiffe, Laura, 2017, arXiv preprint arXiv:1703.04816
Dynamic Coattention Networks For Question Answering [PDF]
Xiong, Caiming and Zhong, Victor and Socher, Richard, 2016, arXiv preprint arXiv:1611.01604
Gated Self-Matching Networks for Reading Comprehension and Question Answering [PDF]
Wang, Wenhui and Yang, Nan and Wei, Furu and Chang, Baobao and Zhou, Ming, 2017, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics
Learning Recurrent Span Representations for Extractive Question Answering [PDF]
Lee, Kenton and Kwiatkowski, Tom and Parikh, Ankur and Das, Dipanjan, 2016, arXiv preprint arXiv:1611.01436
Neural Question Generation from Text: A Preliminary Study [PDF]
Zhou, Qingyu and Yang, Nan and Wei, Furu and Tan, Chuanqi and Bao, Hangbo and Zhou, Ming, 2017, arXiv preprint arXiv:1704.01792