��Ҳ�����ҵĸ��˲����ϣ�https://hltj.me/lang/2016/11/07/10m-letters.html?��
��������ʽ����������Լ����ƣ��ٴη������������ʱ��ϸ磨@2gua�������ϳ���һ����Ŀ��
�������⡿����ʵ�ֵ��Ǻܼ�~ ������Ϥ�����ԣ�ͳ��һ���ַ���abcdefghijklmnopqrstuvwxyz��abcdefghijklmnopqrstuvwxyz��1ǧ���a-z������ֱ��a=1ǧ���� ��ÿ����ĸ�ĸ���������������ͼʾ��Ҫ����˸��õķ�ʽ�������Pythonic�ķ�ʽ������Ҫ����Խ��Խ�ã�����ӡ������ִ��ʱ�䣨��ӡЧ������ͼʾ��?
��ʱ�ֱ�д�� Rust��Kotlin �� Julia �汾�����Ͻ���д�� Java 8 �棬���ٶȷֱ�����Ϊ���� Ruby �������Աȣ���һ̨�����Ե͵�����������ж��ȡ��λ�����£�
Ruby 2.3.1 Rust 1.11.0 Kotlin 1.0.3 Java 1.8.0_112 Julia 0.4.6class="highlighter-rouge">8.4s+
6.4s+
18.8s+
5.8s+
170s+
֮������ Ruby �������Ϊ��������Ϊ�����ٶȷdz��죬���������Ҳ�����ţ������� @mulder �Ļ����ϸ���һ�㣬ʹ����Ϻ�����ʽ��̷��
require "benchmark"
time = Benchmark.realtime do
s = (('a'..'z').to_a.join * 1000_0000)
h = Hash[('a'..'z').collect {|c| [c, s.count(c)]}]
puts h
end
puts time
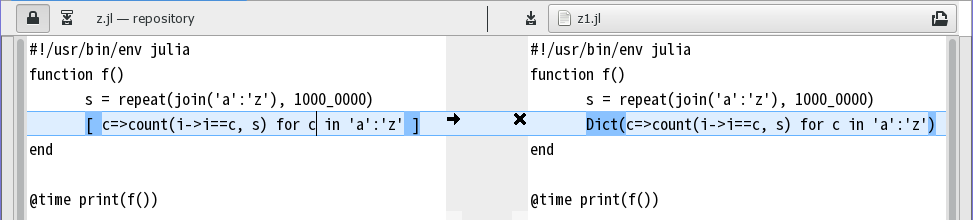
�������ٶ����ݿ���Julia ���������������������ࣺ
function f()
s = repeat(join('a':'z'), 1000_0000)
[ c=>count(i->i==c, s) for c in 'a':'z' ]
end
@time println(f())
���� Ruby ���ʵ�ֺ����ƣ����������Ͽ������Ż��IJ����Ǻܺá�
Rust ����ٶȺܿ죬������ʵ��д�˲��ٴ��룺
use std::time::SystemTime;
fn logarithmic_repeat(mergeable: &Vec<u8>, num: usize) -> Vec<u8> {
let mut result: Vec<u8> = Vec::with_capacity(mergeable.len() * num);
let mut mergeable: Vec<u8> = mergeable.clone();
let mut num = num;
while num != 0 {
if num & 1 != 0 {
result.extend(mergeable.as_slice().iter());
}
num >>= 1;
if num == 0 {
break;
}
let mergeable_clone: Vec<u8> = mergeable.clone();
mergeable.extend(mergeable_clone.as_slice().iter());
}
result
}
fn main() {
let now = SystemTime::now();
let letters: Vec<u8> = (b'a'..b'z'+1).collect();
let repeated: Vec<u8> = logarithmic_repeat(&letters, 1000_0000);
for b in letters {
print!("{}: {}, ", b as char, repeated.iter().filter(|&x| *x==b).count());
}
let elapsed = now.elapsed().unwrap();
println!("\ntime: {}.{:09}s", elapsed.as_secs(), elapsed.subsec_nanos());
}
���������Ѿ��DZȽϼ����ˣ�Rust ������Ϊ���е��������ڻ��ƣ�д�������Ը��ӡ����Ǹ���Ĵ�����Ϊ�����ٶ������������϶�ʵ�ֶ��������ظ����൱�� Ruby ��?*?�� Julia ��?repeat()?������������ Rust ������Ƿȱ�ĵط���
����ľ��ǽ���д�� Java 8 ����룺
import java.util.Collections;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Z {
public static void main(String[] args) {
long startTime=System.currentTimeMillis();
String letters = IntStream.rangeClosed('a', 'z')
.mapToObj(c -> "" + (char)c)
.collect(Collectors.joining());
String repeated = Collections.nCopies(1000_0000, letters)
.parallelStream()
.collect(Collectors.joining());
Map<String, Long> result = repeated.chars()
.parallel()
.mapToObj(c -> "" + (char)c)
.collect(
Collectors.groupingBy(
Function.identity(),
Collectors.counting()
)
);
long endTime=System.currentTimeMillis();
System.out.println(result);
System.out.println("" + (endTime - startTime) / 1000.0 + "s");
}
}
Java 8 ���������µģ���������Ҫ�Լ�ʵ�ֶ������ظ����������Ĵ������Ѿ��� Rust ���൱�ˣ���һ Java 8 �IJ����ǣ���δ֧�ּ����������ƶϣ���Ȼ��Ҳ���䆪�µij���֮һ�� ˵����ȱ�㣬���ڿ����ŵ㣺
groupingBy()?��?counting()?���������ʵ���˴˹��ܣ��Ӷ��������� Rust �桢Ruby �������ظ�ɨ����ַ��� 26 �Ρ�.parallelStream()?��?.parallel()?������ò�����������ܹ����м������������ܹ����ٶ���ʤ������һ�����ء�Kotlin ���ʵ���� Ruby �dz����ƣ�ֻ��û�� Ruby ��ô�����ǣ�
import kotlin.system.measureTimeMillis
fun main(args : Array<String>) {
print(measureTimeMillis {
val letters = ('a'..'z').joinToString(separator="")
val repeated = letters.repeat(1000*10000)
println(letters.map { x -> Pair(x, repeated.count {it == x}) })
} / 1000.0)
println('s')
}
Kotlin ����ԡ�1 ǧ�ı������������Բ�ͬ��������������ֵ��δ֧�ַָ����������д��Ľ���һС������ Java ���ȱ��?groupingBy()?��?counting()?������ Collector��������ܲ��� Java 8�����DZ� Java 8 Ҫ���ܶ��δ����ȡ�� Java ��DZ�ʡ�
������Ϊ���ջ��� Ruby�������Ķ����������ԣ����� Java 8��������� Java 7 Ҳ�Ǹ���ʽ�ĸ��£���
ת�������ģ���ע�����ߣ�������� ������Э��������-����ҵ��ʹ��-��ֹ���