此时此刻,正在等到6.18的到来,趁着没事写个博客,,,
?
storm集群在worker down掉以后会自动启动新的woker,但是有很多情况下是感觉不应该重启的时候,woker重启了,因此就走上了排查woker重启的道路上~
?
经过排查,主要总结有以下几种问题,会导致woker重启:
1. 代码有未捕获的异常
如下例子,因为处理的数据有异常,并且在代码中没有捕获异常,这样Exception被抛给了JVM,导致woker down掉。
对于这样的异常,可以在storm UI界面看到相应的异常信息,因此,排查问题时,可以首先看UI中是否有异常抛出。
?
class="java" name="code">java.lang.RuntimeException: java.lang.NumberFormatException: For input string: "赠品"
at backtype.storm.utils.DisruptorQueue.consumeBatchToCursor(DisruptorQueue.java:90)
at backtype.storm.utils.DisruptorQueue.consumeBatchWhenAvailable(DisruptorQueue.java:61)
at backtype.storm.disruptor$consume_batch_when_available.invoke(disruptor.clj:62)
at backtype.storm.daemon.executor$fn__3498$fn__3510$fn__3557.invoke(executor.clj:730)
at backtype.storm.util$async_loop$fn__444.invoke(util.clj:403)
at clojure.lang.AFn.run(AFn.java:24)
at java.lang.Thread.run(Thread.java:662)
Caused by: java.lang.NumberFormatException: For input string: "赠品"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:48)
at java.lang.Long.parseLong(Long.java:410)
at java.lang.Long.parseLong(Long.java:468)
at com.jd.ad.user.service.impl.UserOrderEntireUpdateServiceImpl.processUserOrderEntireData(UserOrderEntireUpdateServiceImpl.java:96)
at com.jd.a
?
2、JVM 内存溢出
关于这个问题,没有保留下来当初的现场,主要是由于各种原因导致JVM的垃圾回收机制有问题,最终导致内存溢出,这个问题,也会导致woker退出。
对于此类异常,跟1中的一样,也可以在UI界面中看到的,这个需要具体排查JVM内存溢出的原因。
?
3、woker 无问题,supervisor重启woker
对于1和2中的问题,抛出来的异常信息都可以在UI界面中以及woker的日志文件中查找到,但是,我们还遇到了另一种情况,就是在woker中找不到任何的异常信息,但是总是随机的会有woker重启。
?
因为woker中找不到异常信息,这时候就需要查看supervisor中的log信息了,因为supervisor会对本机上的woker中的状态信息进行监控,并且woker的重启也是由supervisor操作的。
?
此时,查看supervisor中的日志信息可以看到以下内容:
2017-06-17 23:36:08 b.s.d.supervisor [INFO] Shutting down and clearing state for id 867ed61b-a9d5-423e-bb0b-b2e428369140.
Current supervisor time: 1497713767. State: :timed-out,
Heartbeat: #backtype.storm.daemon.common.WorkerHeartbeat{:time-secs 1497713735, :storm-id "data_process_1-170-1497518898",
:executors #{[578 578] [868 868] [1158 1158] [1448 1448] [1738 1738] [-1 -1] [288 288]}, :port 6716}
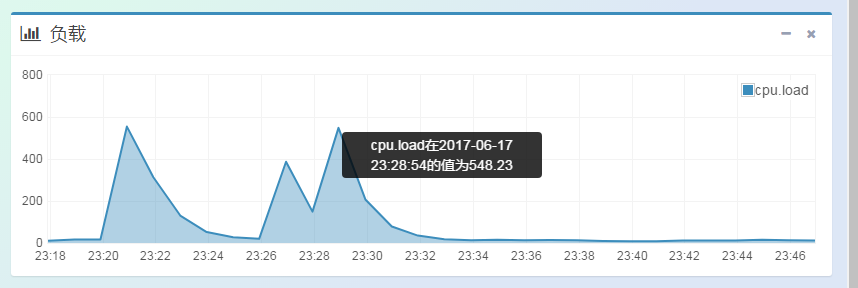
?因此,可以判断为是由于supervisor获取状态信息timeout超时(其实supervisor是获取谁的状态信息,这点还不明确,因为woker的状态信息是在本地文件系统中的,难道是获取executor的状态?这点希望大家拍砖吐槽),导致把woker shut down 了,然后重启了woker。并且此时查看机器的状态,发现zookeeper的机器的CPU负载,会偶尔出现不稳定的状态。如下图:
?
?
因此,可以断定是由于supervisor获取状态信息超时导致的。
?
跟运维沟通,zookeeper的3台机器是跟supervisor部署在同一台机器上面的,因此会造成机器不稳定的情况出现。
?
平稳度过618,准备回家了。
?
?
?
?
?
?
?
?