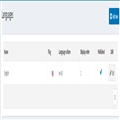
现在来看看我们的索引
GET /_cat/indices?v
返回内容如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open .kibana XYZPR5XGQGWj8YlyZ1et_w 1 1 1 0 3.1kb 3.1kb
可以看到在集群中有一个索引
现在让我们创建一个名叫 class="cnblogs_code">customer 的索引,然后再次列出所有的索引
PUT /customer?pretty
GET /_cat/indices?v
执行第一行返回以下内容,这里我们使用PUT谓词创建了一个名叫 customer 的索引,在后面跟上 pretty 表示如果有数据返回的话,用格式化后的JSON返回数据
{ "acknowledged": true, "shards_acknowledged": true }
执行第二行返回以下内容,结果告诉我们,已经创建了一个名叫 customer 的索引,它有5个主分片和1个复制分片(默认情况下是1个),在这个索引中还没有文档。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open .kibana XYZPR5XGQGWj8YlyZ1et_w 1 1 1 0 3.1kb 3.1kb yellow open customer M8i1ZxhsQJqk7HomOA7c_Q 5 1 0 0 650b 650b
可能你已经注意到 customer 索引的健康值被标记为 yellow ,回顾我们前面讨论的内容, yellow 表示该索引的复制分片(副本)还没有被分配。该索引出现这种情况的原因是, Elasticsearch 默认会为该索引创建1个副本,由于此时我们只有1个节点,那么这副本就没法被分配(为了高可用),直到以后为该集群加入了另一个节点。一旦该副本分配到了另一个节点,该索引的健康状态就会变成 green 。
接下来我们放一些东西到 customer 索引中。之前提过的,为了索引某个文档,我们必须告诉 Elasticsearch ,该文档应该属于该索引的哪个类型,下面我们索引一个简单的文档到 customer 索引,类型名称为 external , 并且ID为1
PUT /customer/external/1?pretty { "name": "John Doe" }
返回内容如下:
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }
从以上可以看出,一个新的客户文档成功被索引到 customer索引的 extenal 类型中,并且我们在索引的时候指定文档的内部id值为1。
值得注意的是, Elasticsearch 不需要在你索引文档到某个索引之前,明确的创建一个索引。比如上一个例子,如果 customer索引不存在, Elasticsearch将自动创建该索引。
再来看下我们刚刚索引的文档
GET /customer/external/1?pretty
返回内容如下:
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 1, "found": true, "_source": { "name": "John Doe" } }
这里比较特殊的是found字段,它说明我们查到了一个id为1的文档,另一特殊的字段_source,保存了在上一个步骤索引的的文档。
现在让我们删除刚刚已经创建的索引,并再次查看所有索引。
DELETE /customer?pretty
GET /_cat/indices?v
第一行返回内容以下:
{ "acknowledged": true }
第二行返回内容如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open .kibana XYZPR5XGQGWj8YlyZ1et_w 1 1 1 0 3.1kb 3.1kb
从以上内容可以看到我们的 customer索引已经被删除了。
在继续学习之前,让我们快速回顾一下,本节学的API命令
PUT /customer PUT /customer/external/1 { "name": "John Doe" } GET /customer/external/1 DELETE /customer
如果仔细学习了以上命令,应该会发现 elasticsearch 访问数据所使用的模式,概括如下:
<REST Verb> /<Index>/<Type>/<ID>
使用REST 访问模式,在所有的API命令中是十分普遍的,如果你可以简单记住它,对于掌握 Elasticsearch ,那么已经开了一个好头。
Elasticsearch 具有近实时的操作和查询数据的能力,默认情况下,从你索引,更新或者删除你的数据到用户可以搜索到新的结果这个过程大概需要1秒(基于refresh 频率)。它们和类似SQL这样的平台不一样,SQL的数据在事务完成后就马上就生效,不会有延迟。
之前已经演示了怎么索引单个文档,再来回顾一下:
PUT /customer/external/1?pretty { "name": "John Doe" }
上面的命令将会索引指定文档到 customer 索引的 external 类型,文档的id值是1。如果我们用不同的文档内容(或者相同)再次执行上面的命令,elasticsearch将会用一个新的文档取代旧的文档(即重建索引)。
PUT /customer/external/1?pretty { "name": "Jane Doe" }
上面的操作把id为1的文档的name字段由"john doe"改成"jane doe"。另一方面,如果我们使用不同的id执行上述命令,将会创建一个新的文档,旧的文档会保持原样。
PUT /customer/external/2?pretty { "name": "Jane Doe" }
以上操作索引了一个新的id为2文档。
索引新文档的时候,id值是可选的。如果没有指定, elasticsearch 将会为文档生成一个随机的id。实际生成的id将会保存在调用api接口的返回结果中。
下面的例子展示不指定文档id的时候是如何索引文档的:
POST /customer/external?pretty { "name": "Jane Doe" }
返回内容如下:
{ "_index": "customer", "_type": "external", "_id": "AVyc9L6dtgHksqXKpTlM", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }
注意,在上面的例子中,因为没有指定id,我们需要使用POST谓词取代之前的PUT谓词。
除了可以索引和替换文档之外,我们还可以更新文档。注意, elasticsearch 并没有在原来的文档基础上进行更新,每当进行更新时, Elasticsearch 将删除旧的文档,然后索引新的文档。以下例子演示了如何更新文档,把之前ID为1的name字段改为"Jane Doe":
POST /customer/external/1/_update?pretty { "doc": { "name": "Jane Doe" } }
以下例子演示了如何更新先前ID为1的文档,改变name字段为"Jane Doe" 的同时添加age字段
POST /customer/external/1/_update?pretty { "doc": { "name": "Jane Doe", "age": 20 } }
也可以使用简单的脚本来执行更新。以下示例使用脚本将年龄增加5:
POST /customer/external/1/_update?pretty { "script" : "ctx._source.age += 5" }
在以上例子中, ctx._source 指当前即将被更新的源文档。请注意,在撰写本文时,只能一次更新单个文档。将来, Elasticsearch 可能会提供通过查询条件(如SQL UPDATE-WHERE语句)更新多个文档的功能。
删除文档非常简单,以下例子演示了怎么删除 customer 索引下ID为2的文档,查阅Delete By Query API 删除与特定查询匹配的所有文档。值得注意的是,直接删除整个索引比通过query api 删除所有文档更高效。
DELETE /customer/external/2?pretty
除了能够索引,更新和删除单个文档之外, Elasticsearch 也提供了使用 _bulk API 批量执行上述任何操作的功能。这个功能是非常重要的,因为它提供了一个非常有效的机制来尽可能快地进行多个操作,并且尽可能减少网络的往返行程。简单举个例子,下面会在一个 bulk操作中索引两个文档:
POST /customer/external/_bulk?pretty {"index":{"_id":"1"}} {"name": "John Doe" } {"index":{"_id":"2"}} {"name": "Jane Doe" }
返回内容如下:
{ "took": 27, "errors": false, "items": [ { "index": { "_index": "customer", "_type": "external", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true, "status": 201 } }, { "index": { "_index": "customer", "_type": "external", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true, "status": 201 } } ] }
下面的例子会在一个操作内更新第一个文档同时删除第二个文档:
POST /customer/external/_bulk?pretty {"update":{"_id":"1"}} {"doc": { "name": "John Doe becomes Jane Doe" } } {"delete":{"_id":"2"}}
返回内容如下:
{ "took": 25, "errors": false, "items": [ { "update": { "_index": "customer", "_type": "external", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 200 } }, { "delete": { "found": true, "_index": "customer", "_type": "external", "_id": "2", "_version": 2, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "status": 200 } } ] }
注意以上的caozuo.html" target="_blank">删除操作,在它之后并没有相应的源文档,因为只需要文档的ID就能删除。
如果某个操作因某些原因执行失败,不会影响后面的操作,它会继续执行剩下的操作。api返回结果时,每一个操作都会提供状态(和接收到的顺序一致),你可以通过这个状态检查操作是否执行成功。
https://www.elastic.co/guide/en/elasticsearch/reference/current/_exploring_your_cluster.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/_modifying_your_data.html
参考文档
https://github.com/13428282016/elasticsearch-CN/wiki/es-gettting-started