走进JVM,浅水也能捉鱼!
这不是一篇描述jvm是什么的文章,也不介绍jvm
跨平台的特性,也不是讲述jvm安全特性的文章,更不是讲解jvm指令操作,数据运算的文章, 本文重点讲述 类型的生命周期。
类型的生命周期涉及到: 类的装载、jvm体系结构、垃圾回收机制。
为什么要讲jvm体系结构? 因为类的装载和垃圾回收机制都和jvm体系结构息息相关。
那么什么是jvm体系结构呢?
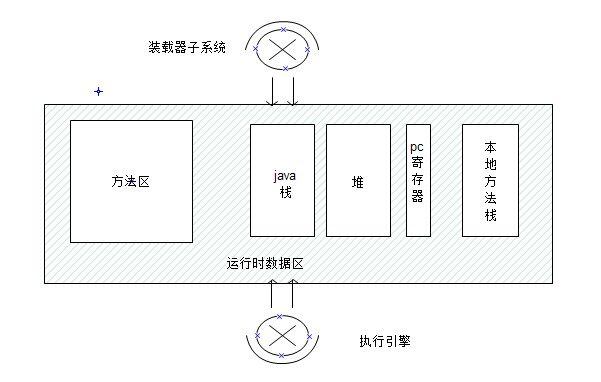
当jvm运行起来的时候,它会向系统申请一片
内存区(不同的jvm实现可能不同,有些可以使用虚拟内存),将这块内存分出一部分存储许多东西,例如:程序创建的对象,传递给方法的参数,返回值,局部变量等等,我们将这块内存称之为“运行时数据区”, 运行时数据区可以划分成方法区、堆、java栈、pc寄存器、本地方法栈。
看到上面这幅图,和这些解说你可能大概的明白jvm 体系是个啥样子,但是你或许还不了解运行时数据区里面方法区等用来干嘛的。
- 方法区:当虚拟机装载一个class文件的时候,它会从这个class文件包含的二进制数据中解析类型信息。然这些类型信息放到方法区中。因为方法区是被所有线程共享的,所以必须考虑数据的线程安全。假如两个线程都在试图找lava的类,在lava类还没有被加载的情况下,只应该有一个线程去加载,而另一个线程等待。
- Pc寄存器:每个新线程产生都将得到自己的pc寄存器以及一个java栈帧。
- 堆:存放程序运行时产生的所有对象。堆是一个线程共享的内存区,所以我们写多线程程序的时候需要考虑并发。
- Java栈:java栈由许多栈帧组成的,如图,当一个线程调用java方法时,虚拟机压入一个新的栈帧到java栈中,当方法返回的时候,这个栈帧被从java栈弹出并被抛弃。
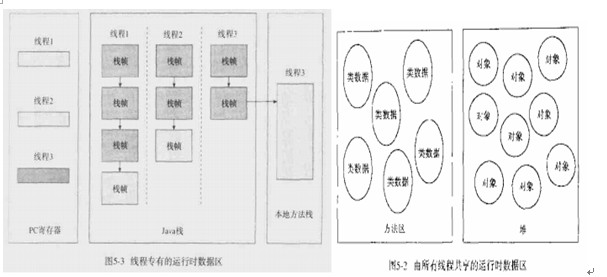
那么现在你应该可以想象到一些jvm是怎么工作的了,是不是应该接着讲具体工作原理了呢?。但是不急,先了解下类的装载机制。
了解类的装载机制之前先了解jvm里面的类装载器:Bootstrap Loader、ExtClassLoader 、AppClassLoader;
ExtClassLoader (负责装载jre下面的rt.jar, charsets.jar)和AppClassLoader(负责转载classpath下面的类包)是ClassLoader(抽象类)的子类;
Bootstrap Loader(负责装载jre核心类库)是根装载器是c/c++写的在java里面看不到它。
这三个类装载器存在父子关系, 根装载器是 ExtClassLoader父装载器,ExtClassLoader是AppClassLoader父装载器;
Jvm中类的装载也是安全机制沙箱模型的第一道门槛。 Java装载类使用“双亲委派模式”―即全盘负责委托机制。
好现在让我们了解装载大概流程;
当装载一个类的时候,若是由用户指定一个类装载器装载的话,那么那个类装载器会先委派给父类装载器,一直委派到根装载器,如果装载的是一个java.lang.String,由于它是核心类库的而且已经被装载过了,那么就会直接返回一个class对象,那么如果是一个根装载器找不到的类呢?接着就会交给子类(下一级父类)装载器,如果还是没有找到类文件,接着就会由之前用户指定的那个类装载器装载。(这里没有说明装载超类的过程,请勿
疏忽)。
如果是有人恶意的写了一个基础类java.lang.String,那么会影响虚拟机吗? 不会因为这个类最终会交由根装载器装载,而根装载器只会去jre核心类库加载,最终返回的class类型并不是 用户写的String,而且系统自带的String,也就是说用户写String永远不会被加载。
了解了类装载器是怎么工作了之后,我们也需要了解下class文件格式;
The ClassFile Structure
ClassFile{
u4 magic; //魔数
u2 minor_version; //class 次版本号
u2 major_version; //class 主版本号
u2 constant_pool_count; //常量池计数
cp_info constant_pool[constant_pool_count-1]; //常量池
u2 access_flags; //修饰符
u2 this_class; /常量池索引
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attrributes_count];
}
我们需要了解的有很多,但是我们难以
理解的就是 cp_info constant_pool 常量池;
一个常量池里面有很多表
CONSTANT_Utf8 UTF-8
编码的Unicode字符串
CONSTANT_Integer int类型的字面值
CONSTANT_Float float类型的字面值
CONSTANT_Long long类型的字面值
CONSTANT_Double double类型的字面值
CONSTANT_Class 对一个类或
接口的符号引用
CONSTANT_String String类型字面值的引用
CONSTANT_Fieldref 对一个字段的符号引用
CONSTANT_Methodref 对一个类中方法的符号引用
CONSTANT_InterfaceMethodref 对一个接口中方法的符号引用
CONSTANT_NameAndType 对一个字段或方法的部分符号引用
这些表结构我也不解释了
如果对class文件不够了解也没什么关系,知道个大概也行。那么我们了解了 jvm体系,类装载器工作流程,那么我们细看下 类装载器工作中 ,jvm运行时数据区的变化,方法区里面的结构等等。
在类装载的过程中, 每一个类装载器都会在方法区里面形成一张表,这张表记载着该装载器和对应的类的权限定名。没这么一张表就形成了jvm内部的命名空间。同时在方法区里面还该类的常量池等信息。
那么说到这些,其实这个过程还是很模糊,而且很多知识也落下了,那么我们现在看一个详细一点的装载过程。
当装载一个普通的类的时候,即调用类装载器的loadClass方法, 如果希望装载的类还没有被装载到命名空间,那么jvm会传递一个该类型的全限定名给类装载器,也就是常量池CONSTANT_Class_info(该表存储着父类、类装载器等信息)入口的装载器,来试图装载被引用的类型,如果发起引用的类型是被jvm装载器定义的,那么由jvm类装载器装载,否则由用户
自定义装载器装载,那么一旦被引用的类型被装载了,jvm仔细检查它的二进制数据,如果类是是一个类,并且不是java.lang.Object。 jvm根据数据得到它的全限定名进行装载(
递归的应用了)这个过程还需要递归超接口。
装载差不多讲完了,一个完整的过程 是: 装载―连接---初始化
那么连接和初始化就一带而过了, 重点放在垃圾回收。
连接的过程主要是验证(确认类型符合java语言的语义,并且它不会危及虚拟机的完整性)、准备(java 虚拟机为类变量分配内存,设计默认初始值)、解析(在类型的常量池中寻找类、接口、字段和方法的符合引用,把这些符号引用替换成直接引用的过程)。
初始化的时候,如果类存在直接超类,且超类还没有被初始化,就先初始化直接超类。初始化接口并不需要初始化它的父接口。
补充:
Jvm当运行某个方法的时候,先把这个方法压入java栈中,里面包含局部变量等信息,那么对象放入哪里呢? 压入栈的是对象的引用, 即变量, 所有的对象都存储在堆中。
为什么要把对象放入堆,把变量之类的数据放入栈呢? 说白了,对象太大了,存入栈中运算麻烦。(当然标准的回答不是这样的,我这里仅仅是说明实质)
了解了这么一个过程之后,我们必然要了解垃圾回收机制了。
基本回收
算法
1. 引用计数:比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
2. 标记-清除:此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
3. 复制:此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不过出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
4. 标记-整理:此算法
结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
5. 增量收集:实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。
6. 分代:基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。




