转自:?http://blog.csdn.net/luanlouis/article/details/41576373?utm_source=tuicool&utm_medium=referral
?
HashMap在Java开发中有着非常重要的角色地位,每一个Java程序员都应该了解HashMap。
??? 本文主要从源码角度来解析HashMap的设计思路,并且详细地阐述HashMap中的几个概念,并深入探讨HashMap的内部结构和实现细节,讨论HashMap的性能问题,并且在文中贯穿着一些关于HashMap常见问题的讨论。?????
?
读完本文,你会了解到: ????1. HashMap的设计思路和内部结构组成???????? 2. HashMap中的一些概念:?什么是阀值?为什么会有阀值?什么是加载因子?它们有什么作用?
???????? 3. HashMap的性能问题以及使用事项
???????? 4. HashMap的源码实现解析
???????? 5. 为什么JDK建议我们重写Object.equals(Object obj)方法时,需要保证对象可以返回相同的hashcode值?
?
?
HashMap设计思路?????Map<K,V>是一种以键值对存储数据的容器,而HashMap则是借助了键值Key的hashcode值来组织存储,使得可以非常快速和高效地地根据键值key进行数据的存取。
?????对于键值对<Key,Value>,HashMap内部会将其封装成一个对应的Entry<Key,Value>对象,即Entry<Key,Value>对象是键值对<Key,Value>的组织形式;
???? 对于每个对象而言,JVM都会为其生成一个hashcode值。HashMap在存储键值对Entry<Key,Value>的时候,会根据Key的hashcode值,以某种映射关系,决定应当将这对键值对Entry<Key,Value>存储在HashMap中的什么位置上;
???? 当通过Key值取数据的时候,然后根据Key值的hashcode,以及内部映射条件,直接定位到Key对应的Value值存放在什么位置,可以非常高效地将Value值取出。?????
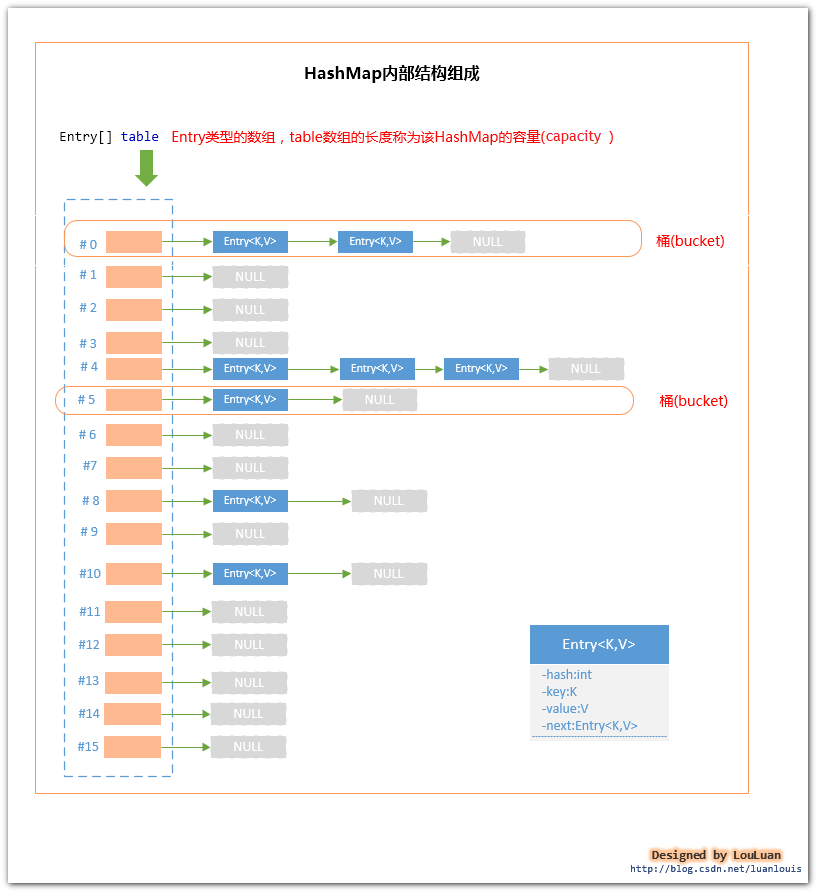
为了实现上述的设计思路,在HashMap内部,采用了数组+链表的形式来组织键值对Entry<Key,Value>。
HashMap内部维护了一个Entry[] table?数组,当我们使用?new HashMap()创建一个HashMap时,Entry[] table?的默认长度为16。Entry[] table的长度又被称为这个HashMap的容量(capacity);
对于Entry[] table的每一个元素而言,或为null,或为由若干个Entry<Key,Value>组成的链表。HashMap中Entry<Key,Value>的数目被称为HashMap的大小(size);
Entry[] table中的某一个元素及其对应的Entry<Key,Value>又被称为桶(bucket);?? ??
其结构如下图所示:
??? HashMap内部组织结构由上图所示,现在来看一下HashMap的基本工作流程:
?
????????HashMap设计的初衷,是为了尽可能地迅速根据Key的hashCode值, 直接就可以定位到对应的Entry<Key,Value>对象,然后得到Value。
????? 请读者考虑这样一个问题:
????? 当我们使用?HashMap map = new HashMap()语句时,我们会创建一个HashMap对象,它内部的?Entry[] table的大小为?16,我们假定Entry[] table的大小会改变。现在,我们现在向它添加160对Key值完全不同的键值对<Key,Value>,那么,该HashMap内部有可能下面这种情况:即对于每一个桶中的由Entry<Key,Value>组成的链表的长度会非常地长!我们知道,对于查找链表操作的时间复杂度是很高的,为O(n)。这样的一个HashMap的性能会很低很低,如下图所示:
现在再来分析一下这个问题,当前的HashMap能够实现:
???? 1. 根据Key的hashCode,可以直接定位到存储这个Entry<Key,Value>的桶所在的位置,这个时间的复杂度为O(1);
???? 2. 在桶中查找对应的Entry<Key,Value>对象节点,需要遍历这个桶的Entry<Key,Value>链表,时间复杂度为O(n);
?? 那么,现在,我们应该尽可能地将第2个问题的时间复杂度o(n)降到最低,读者现在是不是有想法了:我们应该要求桶中的链表的长度越短越好!桶中链表的长度越短,所消耗的查找时间就越低,最好就是一个桶中就一个Entry<Key,Value>对象节点就好了!
???? 这样一来,桶中的Entry<Key,Value>对象节点要求尽可能第少,这就要求,HashMap中的桶的数量要多了。
???? 我们知道,HashMap的桶数目,即Entry[] table数组的长度,由于数组是内存中连续的存储单元,它的空间代价是很大的,但是它的随机存取的速度是Java集合中最快的。我们增大桶的数量,而减少Entry<Key,Value>链表的长度,来提高从HashMap中读取数据的速度。这是典型的拿空间换时间的策略。
????? 但是我们不能刚开始就给HashMap分配过多的桶(即Entry[] table 数组起始不能太大),这是因为数组是连续的内存空间,它的创建代价很大,况且我们不能确定给HashMap分配这么大的空间,它实际到底能够用多少,为了解决这一个问题,HashMap采用了根据实际的情况,动态地分配桶的数量。
?????
HashMap的权衡策略???要动态分配桶的数量,这就要求要有一个权衡的策略了,HashMap的权衡策略是这样的:
?????????????如果
?????????????????????????HashMap的大小>?HashMap的容量(即Entry[] table的大小)*加载因子(经验值0.75)
???????????????则
?????????????????????????HashMap中的Entry[] table 的容量扩充为当前的一倍;
??????????????????????? 然后重新将以前桶中的Entry<Key,Value>链表重新分配到各个桶中
?
上述的??HashMap的容量(即Entry[] table的大小) * 加载因子(经验值0.75)就是所谓的阀值(threshold):
?????????????????
?
??????????? 最后,请读者看一个实例:
???????????? 默认创建的HashMap map =new HashMap();map的容量是?16,那么,当我们往?map中添加第几个完全不同的键值对<Key,Value>时,HashMap的容量会扩充呢??
????????? 呵呵,很简单的计算:由于默认的加载因子是0.75?,那么,此时map的阀值是?16*0.75 = 12,即添加第13?个键值对<Key,Value>的时候,map的容量会扩充一倍。
??????????? 这时候读者可能会有疑问:本来Entry[] table的容量是16,当放入12个键值对<Key,Value>后,不是至少还剩下4个Entry[] table?元素没有被使用到吗?这不是浪费了宝贵的空间了吗?!?? 确实如此,但是为了尽可能第减少桶中的Entry<Key,Value>链表的长度,以提高HashMap的存取性能,确定的这个经验值。如果读者你对存取效率要求的不是太高,想省点空间的话,你可以new HashMap(int initialCapacity, float loadFactor)构造方法将这个因子设置得大一些也无妨。
????
???????HashMap的算法实现最重要的两个是put() 和get() 两个方法,下面我将分析这两个方法:
[java]?view plain?copy ? ?print?class="dp-j">
- public?V?put(K?key,?V?value);??
- public?V?get(Object?key);???
?????另外,HashMap支持Key值为null 的情况,我也将详细地讨论这个问题。
put()方法-向HashMap存储键值对<Key,Value>?
a.? 获取这个Key的hashcode值,根据此值确定应该将这一对键值对存放在哪一个桶中,即确定要存放桶的索引;
b.? 遍历所在桶中的Entry<Key,Value>链表,查找其中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,
c1. 若已存在,定位到对应的Entry<Key,Value>,其中的Value值更新为新的Value值;返回旧值;
c2. 若不存在,则根据键值对<Key,Value> 创建一个新的Entry<Key,Value>对象,然后添加到这个桶的Entry<Key,Value>链表的头部。
d.? 当前的HashMap的大小(即Entry<key,Value>节点的数目)是否超过了阀值,若超过了阀值(threshold),则增大HashMap的容量(即Entry[] table 的大小),并且重新组织内部各个Entry<Key,Value>排列。
详细流程如下列的代码所示:
[java]?view plain?copy ? ?print?
- /**?
- ?*?将<Key,Value>键值对存到HashMap中,如果Key在HashMap中已经存在,那么最终返回被替换掉的Value值。?
- ?*?Key?和Value允许为空?
- ?*/??
- public?V?put(K?key,?V?value)?{??
- ??????
- ????//1.如果key为null,那么将此value放置到table[0],即第一个桶中??
- ????if?(key?==?null)??
- ????????return?putForNullKey(value);??
- ????//2.重新计算hashcode值,??
- ????int?hash?=?hash(key.hashCode());??
- ????//3.计算当前hashcode值应当被分配到哪一个桶中,获取桶的索引??
- ????int?i?=?indexFor(hash,?table.length);??
- ????//4.循环遍历该桶中的Entry列表??
- ????for?(Entry<K,V>?e?=?table[i];?e?!=?null;?e?=?e.next)?{??
- ????????Object?k;??
- ????????//5.?查找Entry<Key,Value>链表中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,??
- ????????//已经存在,则将Value值覆盖到对应的Entry<Key,Value>对象节点上??
- ????????if?(e.hash?==?hash?&&?((k?=?e.key)?==?key?||?key.equals(k)))?{//请读者注意这个判定条件,非常重要!!!??
- ????????????V?oldValue?=?e.value;??
- ????????????e.value?=?value;??
- ????????????e.recordAccess(this);??
- ????????????return?oldValue;??
- ????????}??
- ????}??
- ????modCount++;??
- ????//6不存在,则根据键值对<Key,Value>?创建一个新的Entry<Key,Value>对象,然后添加到这个桶的Entry<Key,Value>链表的头部。??
- ????addEntry(hash,?key,?value,?i);??
- ????return?null;??
- }??
- ??
- /**?
- ?*?Key?为null,则将Entry<null,Value>放置到第一桶table[0]中?
- ?*/??
- private?V?putForNullKey(V?value)?{??
- ????for?(Entry<K,V>?e?=?table[0];?e?!=?null;?e?=?e.next)?{??
- ????????if?(e.key?==?null)?{??
- ????????????V?oldValue?=?e.value;??
- ????????????e.value?=?value;??
- ????????????e.recordAccess(this);??
- ????????????return?oldValue;??
- ????????}??
- ????}??
- ????modCount++;??
- ????addEntry(0,?null,?value,?0);??
- ????return?null;??
- }??
[java]?view plain?copy ? ?print?
- /**?
- ?*?根据特定的hashcode?重新计算hash值,?
- ?*?由于JVM生成的的hashcode的低字节(lower?bits)冲突概率大,(JDK只是这么一说,至于为什么我也不清楚)?
- ?*?为了提高性能,HashMap对Key的hashcode再加工,取Key的hashcode的高字节参与运算?
- ?*/??
- static?int?hash(int?h)?{??
- ????//?This?function?ensures?that?hashCodes?that?differ?only?by??
- ????//?constant?multiples?at?each?bit?position?have?a?bounded??
- ????//?number?of?collisions?(approximately?8?at?default?load?factor).??
- ????h?^=?(h?>>>?20)?^?(h?>>>?12);??
- ????return?h?^?(h?>>>?7)?^?(h?>>>?4);??
- }??
- ??
- /**?
- ?*?返回此hashcode应当分配到的桶的索引?
- ?*/??
- static?int?indexFor(int?h,?int?length)?{??
- ????return?h?&?(length-1);??
- }??
?
?
?
当HashMap的大小大于阀值时,HashMap容量的扩充算法 当当前的HashMap的大小大于阀值时,HashMap会对此HashMap的容量进行扩充,即对内部的Entry[] table 数组进行扩充。
HashMap对容量(Entry[] table数组长度) 有两点要求:
1. 容量的大小应当是 2的N次幂;
2. 当容量大小超过阀值时,容量扩充为当前的一倍;这里第2点很重要,如果当前的HashMap的容量为16,需要扩充时,容量就要变成16*2 = 32,接着就是32*2=64、64*2=128、128*2=256.........可以看出,容量扩充的大小是呈指数级的级别递增的。
??? 这里容量扩充的操作可以分为以下几个步骤:
???????1. 申请一个新的、大小为当前容量两倍的数组;
???? 2.? 将旧数组的Entry[] table中的链表重新计算hash值,然后重新均匀地放置到新的扩充数组中;
???? 3.? 释放旧的数组;
由上述的容量扩充的步骤来看,一次容量扩充的代价非常大,所以在容量扩充时,扩充的比例为当前的一倍,这样做是尽量减少容量扩充的次数。
为了提高HashMap的性能:
???????????????1.在使用HashMap的过程中,你比较明确它要容纳多少Entry<Key,Value>,你应该在创建HashMap的时候直接指定它的容量;
?????????????? 2. 如果你确定HashMap的使用的过程中,大小会非常大,那么你应该控制好 加载因子的大小,尽量将它设置得大些。避免Entry[] table过大,而利用率觉很低。
?
[java]?view plain?copy ? ?print?
- /**?
- ?*?Rehashes?the?contents?of?this?map?into?a?new?array?with?a?
- ?*?larger?capacity.??This?method?is?called?automatically?when?the?
- ?*?number?of?keys?in?this?map?reaches?its?threshold.?
- ?*?
- ?*?If?current?capacity?is?MAXIMUM_CAPACITY,?this?method?does?not?
- ?*?resize?the?map,?but?sets?threshold?to?Integer.MAX_VALUE.?
- ?*?This?has?the?effect?of?preventing?future?calls.?
- ?*?
- ?*?@param?newCapacity?the?new?capacity,?MUST?be?a?power?of?two;?
- ?*????????must?be?greater?than?current?capacity?unless?current?
- ?*????????capacity?is?MAXIMUM_CAPACITY?(in?which?case?value?
- ?*????????is?irrelevant).?
- ?*/??
- void?resize(int?newCapacity)?{??
- ????Entry[]?oldTable?=?table;??
- ????int?oldCapacity?=?oldTable.length;??
- ????if?(oldCapacity?==?MAXIMUM_CAPACITY)?{??
- ????????threshold?=?Integer.MAX_VALUE;??
- ????????return;??
- ????}??
- ??
- ????Entry[]?newTable?=?new?Entry[newCapacity];??
- ????transfer(newTable);??
- ????table?=?newTable;??
- ????threshold?=?(int)(newCapacity?*?loadFactor);??
- }??
- ??
- /**?
- ?*?Transfers?all?entries?from?current?table?to?newTable.?
- ?*/??
- void?transfer(Entry[]?newTable)?{??
- ????Entry[]?src?=?table;??
- ????int?newCapacity?=?newTable.length;??
- ????for?(int?j?=?0;?j?<?src.length;?j++)?{??
- ????????Entry<K,V>?e?=?src[j];??
- ????????if?(e?!=?null)?{??
- ????????????src[j]?=?null;??
- ????????????do?{??
- ????????????????Entry<K,V>?next?=?e.next;??
- ????????????????int?i?=?indexFor(e.hash,?newCapacity);??
- ????????????????e.next?=?newTable[i];??
- ????????????????newTable[i]?=?e;??
- ????????????????e?=?next;??
- ????????????}?while?(e?!=?null);??
- ????????}??
- ????}??
- }??
?
?
?
为什么JDK建议我们重写Object.equals(Object obj)方法时,需要保证对象可以返回相同的hashcode值?Java程序员都看过JDK的API文档,该文档关于Object.equals(Object obj)方法,有这样的描述:
?? “注意:当此方法被重写时,通常有必要重写hashCode?方法,以维护hashCode?方法的常规协定,该协定声明相等对象必须具有相等的哈希码。”
读者虽然知道这个协定,但是不一定真正知道为什么会有这一个要求,现在,就来看看原因吧。
请读者再注意看一下上述的额put()方法实现,当遍历某个桶中的Entry<Key,Value>链表来查找Entry实例的过程中所使用的判断条件:
?
[java]?view plain?copy ? ?print?对于给定的Key,Value,判断该Key是否与Entry链表中有某一个Entry对象的Key值相等使用的是(k==e.key)==key) || key.equals(k),另外还有一个判断条件:即Key经过hash函数转换后的hash值和当前Entry对象的hash属性值相等(该hash属性值和Entry内的Key经过hash方法转换后的hash值相等)。
- for?(Entry<K,V>?e?=?table[i];?e?!=?null;?e?=?e.next)?{??
- ????????????Object?k;??
- ????????????//5.?查找Entry<Key,Value>链表中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,??
- ????????????//已经存在,则将Value值覆盖到对应的Entry<Key,Value>对象节点上??
- ????????????if?(e.hash?==?hash?&&?((k?=?e.key)?==?key?||?key.equals(k)))?{??
- ????????????????V?oldValue?=?e.value;??
- ????????????????e.value?=?value;??
- ????????????????e.recordAccess(this);??
- ????????????????return?oldValue;??
- ????????????}??
- ????????}??
?
????上述的情况我们可以总结为;HashMap在确定Key是否在HashMap中存在的要求有两个:
???????????1. Key值是否相等;
????? 2. hashcode是否相等;
????? 所以我们在定义类时,如果重写了equals()方法,但是hashcode却没有保证相等,就会导致当使用该类实例作为Key值放入HashMap中,会出现HashMap“工作异常”的问题,会出现你不希望的情况。下面让我们通过一个例子来看看这个“工作异常”情况:
例子: 定义一个简单Employee类,重写equals方法,而没有重写hashCode()方法。然后使用该类创建两个实例,放置到一个HashMap中:
?
[java]?view plain?copy ? ?print?[java]?view plain?copy ? ?print?
- package?com.louis.hashlearning;??
- ??
- /**?
- ?*?简单Employee?Bean,重写equals方法,未重写hashCode()方法?
- ?*?@author?louluan?
- ?*/??
- public?class?Employee?{??
- ??????
- ????private?String?employeeCode;??
- ????private?String?name;??
- ??????
- ????public?Employee(String?employeeCode,?String?name)?{??
- ????????this.employeeCode?=?employeeCode;??
- ????????this.name?=?name;??
- ????}??
- ??????
- ????public?String?getEmployeeCode()?{??
- ????????return?employeeCode;??
- ????}??
- ????public?String?getName()?{??
- ????????return?name;??
- ????}??
- ??????
- ????@Override??
- ????public?boolean?equals(Object?o)??
- ????{??
- ????????if(o?instanceof?Employee)??
- ????????{??
- ????????????Employee?e?=?(Employee)o;??
- ????????????if(this.employeeCode.equals(e.getEmployeeCode())?&&?name.equals(e.getName()))??
- ????????????{??
- ????????????????return?true;??
- ????????????}??
- ????????}??
- ????????return?false;??
- ????}??
- }??
?输出结果:
- package?com.louis.hashlearning;??
- import?java.util.HashMap;??
- ??
- public?class?Test?{??
- ??????
- ????public?static?void?main(String[]?args)?{??
- ????????Employee?em1=?new?Employee("123","louis");??
- ????????Employee?em2=?new?Employee("123","louis");??
- ????????boolean?equals=?em1.equals(em2);??
- ????????System.out.println("em1?equals?em2???"?+equals);??
- ??????????
- ????????HashMap?map?=?new?HashMap();??
- ????????map.put(em1,?"test1");??
- ????????map.put(em2,?"test2");??
- ????????System.out.println("map?size:"+map.size());??
- ????}??
- ??
- }??
?
???结果分析:
??????? 上述的例子中,我们使用了new Employee("123","louis"); 语句创建了两个完全一样的对象em1,em2,对我们来说,它们就是相同的对象,然后,我们将这两个我们认为相等的对象作为Key值放入HashMap中,我们想要的结果是:HashMap中的Entry<Key,Value>键值对数目应该就一个,并且Entry对象的Value值应该是由"test1" 替换成"test2",但是实际的结果是:HashMap的大小为2,即HashMap中有两个Entry<Key,Value>键值对!!!
??????? 原因现在读者清晰了:因为em1和em2对象的hashCode()继承自Object,它们返回两个不同的值,即em1 和em2的hashcode值不相同。
从上面的这个例子可以看出:
?????????我们重写Object.equals(Object obj)方法时,需要保证对象可以返回相同的hashcode。否则,HashMap工作的时候会有不可控的异常情况出现。
?
????????????
??????????? 根据特定的Key值从HashMap中取Value的结果就比较简单了:??????????
get()方法-根据Key从HashMap中取Valuea.? 获取这个Key的hashcode值,根据此hashcode值决定应该从哪一个桶中查找;
b.? 遍历所在桶中的Entry<Key,Value>链表,查找其中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,
c1. 若已存在,定位到对应的Entry<Key,Value>,返回value
c2. 若不存在,返回null;
?
具体算法如下:
?
[java]?view plain?copy ? ?print?
- /**?
- ?*?Returns?the?value?to?which?the?specified?key?is?mapped,?
- ?*?or?{@code?null}?if?this?map?contains?no?mapping?for?the?key.?
- ?*??返回key对应的Value值,如果HashMap中没有,则返回null;?
- ?*??支持Key为null情况?
- ?*?<p>More?formally,?if?this?map?contains?a?mapping?from?a?key?
- ?*?{@code?k}?to?a?value?{@code?v}?such?that?{@code?(key==null???k==null?:?
- ?*?key.equals(k))},?then?this?method?returns?{@code?v};?otherwise?
- ?*?it?returns?{@code?null}.??(There?can?be?at?most?one?such?mapping.)?
- ?*?
- ?*?<p>A?return?value?of?{@code?null}?does?not?<i>necessarily</i>?
- ?*?indicate?that?the?map?contains?no?mapping?for?the?key;?it's?also?
- ?*?possible?that?the?map?explicitly?maps?the?key?to?{@code?null}.?
- ?*?The?{@link?#containsKey?containsKey}?operation?may?be?used?to?
- ?*?distinguish?these?two?cases.?
- ?*?
- ?*?@see?#put(Object,?Object)?
- ?*/??
- public?V?get(Object?key)?{??
- ????if?(key?==?null)??
- ????????return?getForNullKey();??
- ????int?hash?=?hash(key.hashCode());??
- ????//遍历列表??
- ????for?(Entry<K,V>?e?=?table[indexFor(hash,?table.length)];??
- ?????????e?!=?null;??
- ?????????e?=?e.next)?{??
- ????????Object?k;??
- ????????if?(e.hash?==?hash?&&?((k?=?e.key)?==?key?||?key.equals(k)))??
- ????????????return?e.value;??
- ????}??
- ????return?null;??
- }??
?
?????????????HashMap允许Key以null的形式存取,Hashmap会将Key为null组成的Entry<null,Value>放置到table[0],即第一个桶中,在put()和get()操作时,会先对Key 为null的值特殊处理:
[java]?view plain?copy ? ?print?
- /**?
- ?*?Offloaded?version?of?get()?to?look?up?null?keys.??Null?keys?map?
- ?*?to?index?0.??This?null?case?is?split?out?into?separate?methods?
- ?*?for?the?sake?of?performance?in?the?two?most?commonly?used?
- ?*?operations?(get?and?put),?but?incorporated?with?conditionals?in?
- ?*?others.?
- ?*?get?操作?
- ?*/??
- private?V?getForNullKey()?{??
- ????for?(Entry<K,V>?e?=?table[0];?e?!=?null;?e?=?e.next)?{??
- ????????if?(e.key?==?null)??
- ????????????return?e.value;??
- ????}??
- ????return?null;??
- }??
[java]?view plain?copy ? ?print?
- /**?
- ?*?Key?为null,则将Entry<null,Value>放置到第一桶table[0]中?
- ?*/??
- private?V?putForNullKey(V?value)?{??
- ????for?(Entry<K,V>?e?=?table[0];?e?!=?null;?e?=?e.next)?{??
- ????????if?(e.key?==?null)?{??
- ????????????V?oldValue?=?e.value;??
- ????????????e.value?=?value;??
- ????????????e.recordAccess(this);??
- ????????????return?oldValue;??
- ????????}??
- ????}??
- ????modCount++;??
- ????addEntry(0,?null,?value,?0);??
- ????return?null;??
- }??
?
根据key值移除键值对的操作也比较简单,内部关键的流程分为两个:
1. 根据Key的hashcode 值和Key定位到Entry<key,Value> 对象在HashMap中的位置;
2. 由于Entry<Key,Value>是一个链表元素,之后便是链表删除节点的操作了;
?
[java]?view plain?copy ? ?print?
- /**?
- ?*?Removes?the?mapping?for?the?specified?key?from?this?map?if?present.?
- ?*?
- ?*?@param??key?key?whose?mapping?is?to?be?removed?from?the?map?
- ?*?@return?the?previous?value?associated?with?<tt>key</tt>,?or?
- ?*?????????<tt>null</tt>?if?there?was?no?mapping?for?<tt>key</tt>.?
- ?*?????????(A?<tt>null</tt>?return?can?also?indicate?that?the?map?
- ?*?????????previously?associated?<tt>null</tt>?with?<tt>key</tt>.)?
- ?*/??
- public?V?remove(Object?key)?{??
- ????Entry<K,V>?e?=?removeEntryForKey(key);??
- ????return?(e?==?null???null?:?e.value);??
- }??
- ??
- /**?
- ?*?Removes?and?returns?the?entry?associated?with?the?specified?key?
- ?*?in?the?HashMap.??Returns?null?if?the?HashMap?contains?no?mapping?
- ?*?for?this?key.?
- ?*/??
- final?Entry<K,V>?removeEntryForKey(Object?key)?{??
- ????int?hash?=?(key?==?null)???0?:?hash(key.hashCode());??
- ????int?i?=?indexFor(hash,?table.length);??
- ????Entry<K,V>?prev?=?table[i];??
- ????Entry<K,V>?e?=?prev;??
- ??
- ????while?(e?!=?null)?{??
- ????????Entry<K,V>?next?=?e.next;??
- ????????Object?k;??
- ????????if?(e.hash?==?hash?&&??
- ????????????((k?=?e.key)?==?key?||?(key?!=?null?&&?key.equals(k))))?{??
- ????????????modCount++;??
- ????????????size--;??
- ????????????if?(prev?==?e)??
- ????????????????table[i]?=?next;??
- ????????????else??
- ????????????????prev.next?=?next;??
- ????????????e.recordRemoval(this);??
- ????????????return?e;??
- ????????}??
- ????????prev?=?e;??
- ????????e?=?next;??
- ????}??
- ??
- ????return?e;??
- }??
?
????????1. HashMap是线程不安全的,如果想使用线程安全的,可以使用Hashtable;它提供的功能和Hashmap基本一致。HashMap实际上是一个Hashtable的轻量级实现;
????? 2. 允许以Key为null的形式存储<null,Value>键值对;
????? 3. HashMap的查找效率非常高,因为它使用Hash表对进行查找,可直接定位到Key值所在的桶中;
????? 4. 使用HashMap时,要注意HashMap容量和加载因子的关系,这将直接影响到HashMap的性能问题。加载因子过小,会提高HashMap的查找效率,但同时也消耗了大量的内存空间,加载因子过大,节省了空间,但是会导致HashMap的查找效率降低。
?