很多人都不太认可以第三方ORM,因为考虑的点不够全面,没有用户群体大的ORM有保证,这点是不可否认确是事实。
但是往往用户群体大的ORM又有不足之处,就拿用户群体最多的两个ORM来说一下吧
EF性能够用,但是总体还是和轻量级ORM有一定差距,如果没有差距就没有Dapper什么事儿了。
性能不错,兼容也好但是就是语法太少,基本都要手写SQL,或自已扩展,自己扩展考虑的点可能连第三方ORM都不如,只能够自已需求使用,发现问题自已来改,没发现问题也挺安逸。
第一 要感谢上海蓝灯数据科技股份有限公司给我构架师一职让.NET部门都使用我的技术框架
第二 百签软件的老总的大力支持除了自已员工使用外还帮我喧传
第三 群( 225982985)里的朋友向我提了很多保贵的问题和改进的建议。
第四 chloe.ORM的作者,两个人都为了ORM基情四射
而这些坑我发现博客园的一些其它ORM也普遍存在,所以我将这些问题一一的分享,也希望更多人能够指出SqlSugar的不足之处。
Sql执行计划是什么,简单的说就是让Sql服务器更明确的知道你要做什么,将你的操作步骤存起来,下一次遇到同样的SQL便使用同样的操作步骤 ,大大降低SQL操作的步骤,提高性能,引起的性能差距可能是成倍的 。
参数化比拼SQL性能高的原因,也就是因为调用了系统存储过程 sp_executesql 将Sql执行计划的优势发挥了出来
如下图 name的长度为11,因为sqlparameter没有指定Size 所以nvarchar的数字是动态的,所以会导致Sql执行计划无效,一般的性能测试很难测出来,这种情况将会打乱Sql执行计划,当参数越多,参数的长度越大性能差距越明显。
而固定长度的测试根本发现不了。

解决方案:
将SqlParameter size<4000
全部设为4000,EF和Dapper在这点上就做的非常的棒
例如出现 id<1&&id>0处理两个相同的名字参数时 id<@id and id>@id+随机数
只要加了随机数就无法进执行计划了
解决方案:
自增数 id<@id and id>@id1
这一点就Dapper做的最好,EF也不错给出了很明确的错误信息。
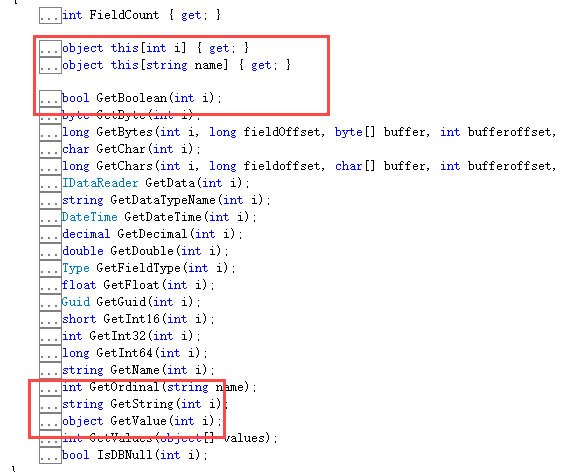
为什么说Dapper做的最好呢,因为Dapper能把数据的int转换成实体类中的string。数据库是string转换成int时就给出了非常明确的错误信息。
目前第三方ORM都没在这方面做很好的处理
解决方案:
需要做很细的类型判段,我的做法是在Emit生成Dynamicbuilder之前处理,用数据库类型和实体类体做对比,将异常提前抛出,没有异常EMIT对象将存进缓存,预热后不会在执行。
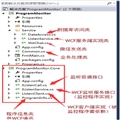
就单纯拿Emit将DataReader转成List<T>来说,第三方的ORM基本上都做到了比Dapper快或者说平分秋色。
预热后一次查询100万条数据这是最好的测试方式,但要注意一点 如果走的是 DataReader的索引器 那就会有性能损耗
GetValue和索引器都是Object类型执行转换后将会产生 拆箱(将OBJECT转成了值类型),SqlSugar能在这个方面得到改进,多亏Chloe.ORM作者帮我发现了这个问题
如何测试自已拉姆达解析成SQL过程花时间多长呢,
测试方法:每执行一次只查询一条数据,WHERE条件多设一点。执行次数10000以上。
解决方案:在解析过程中千万不能用 Expression.Lambda(exp).Compile().DynamicInvoke();
用了这种写法将会带来十倍的性能之差,按上面的测试方式很容易测出性能的瓶颈。
越短的时间内执行的次数越多越容易体现出来。
发布到Nuget2周时间不到
我已经提交了这么多次修改
最后我只想说一句,不是第三方ORM不能用,而是你们并没有把问题指出来,代码开源就是为了让大家一起进步,一起改进。
只要作者有激情,有上进心,还担心什么呢。