在上一篇中我们讲到,视图的刷新需要很多步骤,
void SurfaceFlinger::handleMessageRefresh() { ATRACE_CALL(); preComposition(); //合成前的准备 rebuildLayerStacks();//重新建立layer堆栈 setUpHWComposer();//HWComposer的设定 #ifdef QCOM_BSP setUpTiledDr(); #endif doDebugFlashRegions(); doComposition(); //正式合成工作 postComposition(); //合成的后期工作 }
本文将继续分析这些过程。
invalidate 字面意思就是使无效,更进一步就是当前的buffer已经无限,请刷新界面。
啥也没干,buffer已经无效,我换下一个,就是handlePageFlip
void SurfaceFlinger::handleMessageInvalidate() { ATRACE_CALL(); handlePageFlip(); }
再来看这个函数:handlePageFlip
bool SurfaceFlinger::handlePageFlip() { Region dirtyRegion; bool visibleRegions = false; const LayerVector& layers(mDrawingState.layersSortedByZ); bool frameQueued = false; // Store the set of layers that need updates. This set must not change as // buffers are being latched, as this could result in a deadlock. // Example: Two producers share the same command stream and: // 1.) Layer 0 is latched // 2.) Layer 0 gets a new frame // 2.) Layer 1 gets a new frame // 3.) Layer 1 is latched. // Display is now waiting on Layer 1's frame, which is behind layer 0's // second frame. But layer 0's second frame could be waiting on display. Vector<Layer*> layersWithQueuedFrames; for (size_t i = 0, count = layers.size(); i<count ; i++) { const sp<Layer>& layer(layers[i]); if (layer->hasQueuedFrame()) { frameQueued = true; if (layer->shouldPresentNow(mPrimaryDispSync)) { layersWithQueuedFrames.push_back(layer.get()); } } } for (size_t i = 0, count = layersWithQueuedFrames.size() ; i<count ; i++) { Layer* layer = layersWithQueuedFrames[i]; const Region dirty(layer->latchBuffer(visibleRegions)); const Layer::State& s(layer->getDrawingState()); invalidateLayerStack(s.layerStack, dirty); } mVisibleRegionsDirty |= visibleRegions; // If we will need to wake up at some time in the future to deal with a // queued frame that shouldn't be displayed during this vsync period, wake // up during the next vsync period to check again. if (frameQueued && layersWithQueuedFrames.empty()) { signalLayerUpdate(); } // Only continue with the refresh if there is actually new work to do return !layersWithQueuedFrames.empty(); }handlePageFlip
@step1:layer->latchBuffer(visibleRegions) 通过该函数锁定各layer的缓冲区。可以理解这个函数一定与BufferQueue有关。
status_t updateResult = mSurfaceFlingerConsumer->updateTexImage(&r,
mFlinger->mPrimaryDispSync);
上面是latchBuffer的核心语句。SurfaceFlingerConsumer前文已经提过,是client端操作bufferqueue的一个端口。所以这个函数一定是操作bufferqueue的。
// Acquire the next buffer. // In asynchronous mode the list is guaranteed to be one buffer // deep, while in synchronous mode we use the oldest buffer. err = acquireBufferLocked(&item, computeExpectedPresent(dispSync)); if (err != NO_ERROR) { if (err == BufferQueue::NO_BUFFER_AVAILABLE) { err = NO_ERROR; } else if (err == BufferQueue::PRESENT_LATER) { // return the error, without logging } else { ALOGE("updateTexImage: acquire failed: %s (%d)", strerror(-err), err); } return err; } // We call the rejecter here, in case the caller has a reason to // not accept this buffer. This is used by SurfaceFlinger to // reject buffers which have the wrong size int buf = item.mBuf; if (rejecter && rejecter->reject(mSlots[buf].mGraphicBuffer, item)) { releaseBufferLocked(buf, mSlots[buf].mGraphicBuffer, EGL_NO_SYNC_KHR); return NO_ERROR; } // Release the previous buffer. err = updateAndReleaseLocked(item); if (err != NO_ERROR) { return err; }
看了注释,基本解释了大体的过程。
1) 请求新的buffer
2)通过rejecter来判断申请的buffer是否满足surfaceflinger的要求。
3)释放之前的buffer
具体流程可以参考如下:
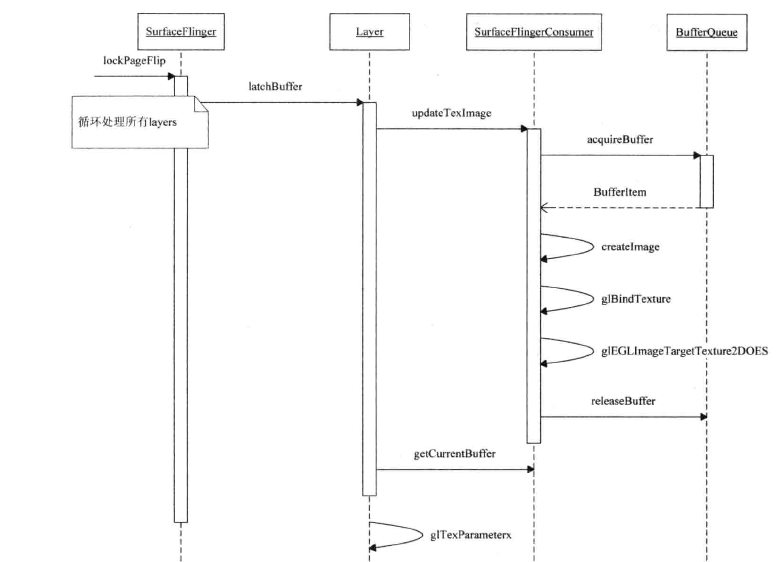
@step2:SurfaceFlinger:invalidateLayerStack来更新各个区域。
首先来看2个Vsync Rate相关的代码:
virtual void setVsyncRate(uint32_t count) virtual void requestNextVsync()
当count为1时,表示每个信号都要报告,当count =2 时,表示信号 一个间隔一个报告,当count =0时,表示不自动报告,除非主动触发requestNextVsync
void SurfaceFlinger::preComposition() { bool needExtraInvalidate = false; const LayerVector& layers(mDrawingState.layersSortedByZ); const size_t count = layers.size(); for (size_t i=0 ; i<count ; i++) { if (layers[i]->onPreComposition()) { needExtraInvalidate = true; } } if (needExtraInvalidate) { signalLayerUpdate(); } }
代码很简单,其实一共就3步,
1)获取全部的layer
2)每个layer onPrecomposition
3) layer update
bool Layer::onPreComposition() { mRefreshPending = false; return mQueuedFrames > 0 || mSidebandStreamChanged; }
也就是说,当layer里存放被queue的frame以后,就会出发layer update.
void SurfaceFlinger::signalLayerUpdate() { mEventQueue.invalidate(); }
最终会调用:
void EventThread::Connection::requestNextVsync() { mEventThread->requestNextVsync(this); }
void EventThread::requestNextVsync( const sp<EventThread::Connection>& connection) { Mutex::Autolock _l(mLock); if (connection->count < 0) { connection->count = 0; mCondition.broadcast();//通知对vsync感兴趣的类 } }
那么谁在等待这个broadcast呢?
还是EventThread
void EventThread::onVSyncEvent(nsecs_t timestamp) { Mutex::Autolock _l(mLock); mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC; mVSyncEvent[0].header.id = 0; mVSyncEvent[0].header.timestamp = timestamp; mVSyncEvent[0].vsync.count++; mCondition.broadcast(); }

void SurfaceFlinger::rebuildLayerStacks() { #ifdef QCOM_BSP char prop[PROPERTY_VALUE_MAX]; property_get("sys.extended_mode", prop, "0"); sExtendedMode = atoi(prop) ? true : false; #endif // rebuild the visible layer list per screen if (CC_UNLIKELY(mVisibleRegionsDirty)) { ATRACE_CALL(); mVisibleRegionsDirty = false; invalidateHwcGeometry(); const LayerVector& layers(mDrawingState.layersSortedByZ); for (size_t dpy=0 ; dpy<mDisplays.size() ; dpy++) { Region opaqueRegion; Region dirtyRegion; Vector< sp<Layer> > layersSortedByZ; const sp<DisplayDevice>& hw(mDisplays[dpy]); const Transform& tr(hw->getTransform()); const Rect bounds(hw->getBounds()); int dpyId = hw->getHwcDisplayId(); if (hw->isDisplayOn()) { SurfaceFlinger::computeVisibleRegions(dpyId, layers, hw->getLayerStack(), dirtyRegion, opaqueRegion); const size_t count = layers.size(); for (size_t i=0 ; i<count ; i++) { const sp<Layer>& layer(layers[i]); const Layer::State& s(layer->getDrawingState()); Region drawRegion(tr.transform( layer->visibleNonTransparentRegion)); drawRegion.andSelf(bounds); if (!drawRegion.isEmpty()) { layersSortedByZ.add(layer); } } } hw->setVisibleLayersSortedByZ(layersSortedByZ); hw->undefinedRegion.set(bounds); hw->undefinedRegion.subtractSelf(tr.transform(opaqueRegion)); hw->dirtyRegion.orSelf(dirtyRegion); } } }rebuildLayerStacks
前文提到mVisibleRegionsDirty这个变量是标记要刷新的可见区域的,我们按字面意思解释下:脏的可见区域,顾名思义,这就是要刷新的区域,因为buffer已经“脏”了。
@step1:系统的display可能不止一个,存在与mDisplays中。
@step2:computeVisibleRegions这个函数根据所有的layer状态,得到2个重要的变量。opaqueRegion & dirtyRegion
dirtyRegion是需要被刷新的。 opaqueRegion 不透明区域,应为layer是按Z-order排序的,左右排在前面的opaqueRegion 会挡住后面的layer。
@step3:Region drawRegion(tr.transform( layer->visibleNonTransparentRegion));程序需要进一步得出每个layer 绘制的区域。
系统的display(显示器)可能不止一个,但是所有的layer都记录在layersSortedByZ里面。记录每个layer属于那个display的变量是 hw->getLayerStack()
@step4:将结果保存到hw中。
这里的不透明区域 是很有意义的一个概念,就是我们在Z-order 上,越靠近用户的时候,值越大,所以是递减操作。
用于合成surface的功能模块可以有2个,OpenGL ES & HWC,它的管理实在HWC里面实现的。
setUpHWComposer 总的来说就干了3件事情。
1)构造Worklist,并且给DisplayData:list 申请空间
2)填充各layer数据
3)报告HWC(有其他地方决定使用那个)
关键地方来了,上面的setUpHWComposer 只是交给HWC来负责显示,真正显示的地方就在这里。
1)如何合成
2)如何显示到屏幕上
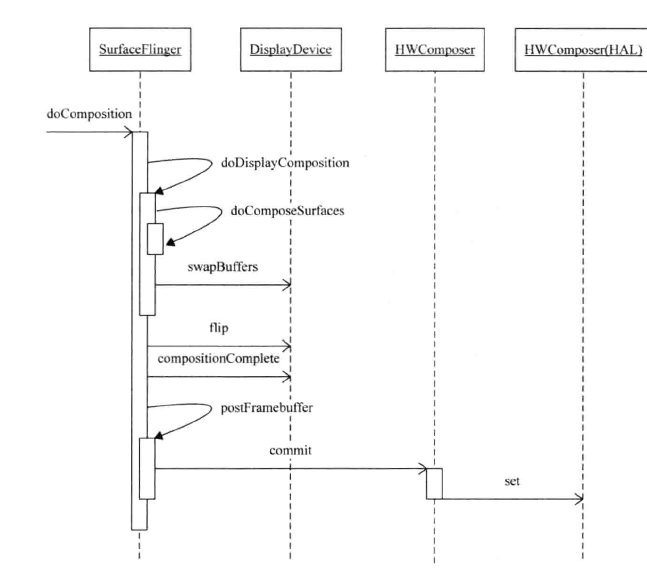
合成的流程大体如上图。
有了概念后,分析源码:
void SurfaceFlinger::doComposition() { ATRACE_CALL(); const bool repaintEverything = android_atomic_and(0, &mRepaintEverything); for (size_t dpy=0 ; dpy<mDisplays.size() ; dpy++) { const sp<DisplayDevice>& hw(mDisplays[dpy]); if (hw->isDisplayOn()) { // transform the dirty region into this screen's coordinate space const Region dirtyRegion(hw->getDirtyRegion(repaintEverything)); // repaint the framebuffer (if needed) doDisplayComposition(hw, dirtyRegion); ++mActiveFrameSequence; hw->dirtyRegion.clear(); hw->flip(hw->swapRegion); hw->swapRegion.clear(); } // inform the h/w that we're done compositing hw->compositionComplete(); } postFramebuffer(); }
变量mRepaintEverything用于说明,是否需要全部重绘所有内容。如果为true的化,那么dirtyRegion就是displaydevice的 width & height构成的RECT。
否则由dirtyRegion转换而来。
doDisplayComposition是每个Display来处理,有可能会用到OpenGL 的接口来交换buffer。
hw->compositionComplete(); 通知HWC合成结束了。
postFramebuffer HWC的Set接口调用。
void SurfaceFlinger::doDisplayComposition(const sp<const DisplayDevice>& hw, const Region& inDirtyRegion) { // We only need to actually compose the display if: // 1) It is being handled by hardware composer, which may need this to // keep its virtual display state machine in sync, or // 2) There is work to be done (the dirty region isn't empty) bool isHwcDisplay = hw->getHwcDisplayId() >= 0; if (!isHwcDisplay && inDirtyRegion.isEmpty()) { return; } Region dirtyRegion(inDirtyRegion); // compute the invalid region hw->swapRegion.orSelf(dirtyRegion); uint32_t flags = hw->getFlags(); if (flags & DisplayDevice::SWAP_RECTANGLE) { // we can redraw only what's dirty, but since SWAP_RECTANGLE only // takes a rectangle, we must make sure to update that whole // rectangle in that case dirtyRegion.set(hw->swapRegion.bounds()); } else { if (flags & DisplayDevice::PARTIAL_UPDATES) { // We need to redraw the rectangle that will be updated // (pushed to the framebuffer). // This is needed because PARTIAL_UPDATES only takes one // rectangle instead of a region (see DisplayDevice::flip()) dirtyRegion.set(hw->swapRegion.bounds()); } else { // we need to redraw everything (the whole screen) dirtyRegion.set(hw->bounds()); hw->swapRegion = dirtyRegion; } } if (CC_LIKELY(!mDaltonize && !mHasColorMatrix)) { if (!doComposeSurfaces(hw, dirtyRegion)) return; } else { RenderEngine& engine(getRenderEngine()); mat4 colorMatrix = mColorMatrix; if (mDaltonize) { colorMatrix = colorMatrix * mDaltonizer(); } mat4 oldMatrix = engine.setupColorTransform(colorMatrix); doComposeSurfaces(hw, dirtyRegion); engine.setupColorTransform(oldMatrix); } // update the swap region and clear the dirty region hw->swapRegion.orSelf(dirtyRegion); // swap buffers (presentation) hw->swapBuffers(getHwComposer()); }doDisplayComposition
传入的参数inDirtyRegion,这就是要刷新的“脏”区域,but,我们的刷新机制,决定了必须是矩形的区域。
So,需要一个最小的矩形,能够包裹inDirtyRegion的区域。
SWAP_RECTANGLE:系统支持软件层面的部分刷新,就需要计算这个最小矩形。
PARTIAL_UPDATES:硬件层面的部分刷新,同理需要这个最小矩形。
最后就是重绘这个区域。
bool SurfaceFlinger::doComposeSurfaces(const sp<const DisplayDevice>& hw, const Region& dirty) { RenderEngine& engine(getRenderEngine()); const int32_t id = hw->getHwcDisplayId(); HWComposer& hwc(getHwComposer()); HWComposer::LayerListIterator cur = hwc.begin(id); const HWComposer::LayerListIterator end = hwc.end(id); Region clearRegion; bool hasGlesComposition = hwc.hasGlesComposition(id); const bool hasHwcComposition = hwc.hasHwcComposition(id); if (hasGlesComposition) { if (!hw->makeCurrent(mEGLDisplay, mEGLContext)) { ALOGW("DisplayDevice::makeCurrent failed. Aborting surface composition for display %s", hw->getDisplayName().string()); eglMakeCurrent(mEGLDisplay, EGL_NO_SURFACE, EGL_NO_SURFACE, EGL_NO_CONTEXT); if(!getDefaultDisplayDevice()->makeCurrent(mEGLDisplay, mEGLContext)) { ALOGE("DisplayDevice::makeCurrent on default display failed. Aborting."); } return false; } // Never touch the framebuffer if we don't have any framebuffer layers if (hasHwcComposition) { // when using overlays, we assume a fully transparent framebuffer // NOTE: we could reduce how much we need to clear, for instance // remove where there are opaque FB layers. however, on some // GPUs doing a "clean slate" clear might be more efficient. // We'll revisit later if needed. if(!(mGpuTileRenderEnable && (mDisplays.size()==1))) engine.clearWithColor(0, 0, 0, 0); } else { // we start with the whole screen area const Region bounds(hw->getBounds()); // we remove the scissor part // we're left with the letterbox region // (common case is that letterbox ends-up being empty) const Region letterbox(bounds.subtract(hw->getScissor())); // compute the area to clear Region region(hw->undefinedRegion.merge(letterbox)); // but limit it to the dirty region region.andSelf(dirty); // screen is already cleared here #ifdef QCOM_BSP clearRegion.clear(); if(mGpuTileRenderEnable && (mDisplays.size()==1)) { clearRegion = region; if (cur == end) { drawWormhole(hw, region); } else if(mCanUseGpuTileRender) { /* If GPUTileRect DR optimization on clear only the UnionDR * (computed by computeTiledDr) which is the actual region * that will be drawn on FB in this cycle.. */ clearRegion = clearRegion.andSelf(Region(mUnionDirtyRect)); } } else #endif { if (!region.isEmpty()) { if (cur != end) { if (cur->getCompositionType() != HWC_BLIT) // can happen with SurfaceView drawWormhole(hw, region); } else drawWormhole(hw, region); } } } if (hw->getDisplayType() != DisplayDevice::DISPLAY_PRIMARY) { // just to be on the safe side, we don't set the // scissor on the main display. It should never be needed // anyways (though in theory it could since the API allows it). const Rect& bounds(hw->getBounds()); const Rect& scissor(hw->getScissor()); if (scissor != bounds) { // scissor doesn't match the screen's dimensions, so we // need to clear everything outside of it and enable // the GL scissor so we don't draw anything where we shouldn't // enable scissor for this frame const uint32_t height = hw->getHeight(); engine.setScissor(scissor.left, height - scissor.bottom, scissor.getWidth(), scissor.getHeight()); } } } /* * and then, render the layers targeted at the framebuffer */ const Vector< sp<Layer> >& layers(hw->getVisibleLayersSortedByZ()); const size_t count = layers.size(); const Transform& tr = hw->getTransform(); if (cur != end) { // we're using h/w composer #ifdef QCOM_BSP int fbWidth= hw->getWidth(); int fbHeight= hw->getHeight(); /* if GPUTileRender optimization property is on & can be used * i) Enable EGL_SWAP_PRESERVED flag * ii) do startTile with union DirtyRect * else , Disable EGL_SWAP_PRESERVED */ if(mGpuTileRenderEnable && (mDisplays.size()==1)) { if(mCanUseGpuTileRender && !mUnionDirtyRect.isEmpty()) { hw->eglSwapPreserved(true); Rect dr = mUnionDirtyRect; engine.startTileComposition(dr.left, (fbHeight-dr.bottom), (dr.right-dr.left), (dr.bottom-dr.top), 0); } else { // Un Set EGL_SWAP_PRESERVED flag, if no tiling required. hw->eglSwapPreserved(false); } // DrawWormHole/Any Draw has to be within startTile & EndTile if (hasGlesComposition) { if (hasHwcComposition) { if(mCanUseGpuTileRender && !mUnionDirtyRect.isEmpty()) { const Rect& scissor(mUnionDirtyRect); engine.setScissor(scissor.left, hw->getHeight()- scissor.bottom, scissor.getWidth(), scissor.getHeight()); engine.clearWithColor(0, 0, 0, 0); engine.disableScissor(); } else { engine.clearWithColor(0, 0, 0, 0); } } else { if (cur->getCompositionType() != HWC_BLIT && !clearRegion.isEmpty()) { drawWormhole(hw, clearRegion); } } } } #endif for (size_t i=0 ; i<count && cur!=end ; ++i, ++cur) { const sp<Layer>& layer(layers[i]); const Region clip(dirty.intersect(tr.transform(layer->visibleRegion))); if (!clip.isEmpty()) { switch (cur->getCompositionType()) { case HWC_CURSOR_OVERLAY: case HWC_OVERLAY: { const Layer::State& state(layer->getDrawingState()); if ((cur->getHints() & HWC_HINT_CLEAR_FB) && i && layer->isOpaque(state) && (state.alpha == 0xFF) && hasGlesComposition) { // never clear the very first layer since we're // guaranteed the FB is already cleared layer->clearWithOpenGL(hw, clip); } break; } case HWC_FRAMEBUFFER: { layer->draw(hw, clip); break; } case HWC_BLIT: //Do nothing break; case HWC_FRAMEBUFFER_TARGET: { // this should not happen as the iterator shouldn't // let us get there. ALOGW("HWC_FRAMEBUFFER_TARGET found in hwc list (index=%zu)", i); break; } } } layer->setAcquireFence(hw, *cur); } #ifdef QCOM_BSP // call EndTile, if starTile has been called in this cycle. if(mGpuTileRenderEnable && (mDisplays.size()==1)) { if(mCanUseGpuTileRender && !mUnionDirtyRect.isEmpty()) { engine.endTileComposition(GL_PRESERVE); } } #endif } else { // we're not using h/w composer for (size_t i=0 ; i<count ; ++i) { const sp<Layer>& layer(layers[i]); const Region clip(dirty.intersect( tr.transform(layer->visibleRegion))); if (!clip.isEmpty()) { layer->draw(hw, clip); } } } // disable scissor at the end of the frame engine.disableScissor(); return true; }doComposeSurfaces
依次分析:hasGlesComposition需要Open GL来合成的layer,hasHwcComposition需要HWC来合成的layer。
这2各变量不是互斥的,有同时存在需要Open GL layer & HWC layer。
hasHwcComposition在2种情况下是true。
1)layer的类型是HWC_Framebuffer的时候,通常情况下是true。
2)cur ==end 核心实现layer->draw 来完成。
3)cur!=end, 将有hwc来实现。
{ ATRACE_CALL(); if (CC_UNLIKELY(mActiveBuffer == 0)) { // the texture has not been created yet, this Layer has // in fact never been drawn into. This happens frequently with // SurfaceView because the WindowManager can't know when the client // has drawn the first time. // If there is nothing under us, we paint the screen in black, otherwise // we just skip this update. // figure out if there is something below us Region under; const SurfaceFlinger::LayerVector& drawingLayers( mFlinger->mDrawingState.layersSortedByZ); const size_t count = drawingLayers.size(); for (size_t i=0 ; i<count ; ++i) { const sp<Layer>& layer(drawingLayers[i]); if (layer.get() == static_cast<Layer const*>(this)) break; under.orSelf( hw->getTransform().transform(layer->visibleRegion) ); } // if not everything below us is covered, we plug the holes! Region holes(clip.subtract(under)); if (!holes.isEmpty()) { clearWithOpenGL(hw, holes, 0, 0, 0, 1); } return; } // Bind the current buffer to the GL texture, and wait for it to be // ready for us to draw into. status_t err = mSurfaceFlingerConsumer->bindTextureImage(); if (err != NO_ERROR) { ALOGW("onDraw: bindTextureImage failed (err=%d)", err); // Go ahead and draw the buffer anyway; no matter what we do the screen // is probably going to have something visibly wrong. } bool blackOutLayer = isProtected() || (isSecure() && !hw->isSecure()); RenderEngine& engine(mFlinger->getRenderEngine()); if (!blackOutLayer) { // TODO: we could be more subtle with isFixedSize() const bool useFiltering = getFiltering() || needsFiltering(hw) || isFixedSize(); // Query the texture matrix given our current filtering mode. float textureMatrix[16]; mSurfaceFlingerConsumer->setFilteringEnabled(useFiltering); mSurfaceFlingerConsumer->getTransformMatrix(textureMatrix); if (mSurfaceFlingerConsumer->getTransformToDisplayInverse()) { /* * the code below applies the display's inverse transform to the texture transform */ // create a 4x4 transform matrix from the display transform flags const mat4 flipH(-1,0,0,0, 0,1,0,0, 0,0,1,0, 1,0,0,1); const mat4 flipV( 1,0,0,0, 0,-1,0,0, 0,0,1,0, 0,1,0,1); const mat4 rot90( 0,1,0,0, -1,0,0,0, 0,0,1,0, 1,0,0,1); mat4 tr; uint32_t transform = hw->getOrientationTransform(); if (transform & NATIVE_WINDOW_TRANSFORM_ROT_90) tr = tr * rot90; if (transform & NATIVE_WINDOW_TRANSFORM_FLIP_H) tr = tr * flipH; if (transform & NATIVE_WINDOW_TRANSFORM_FLIP_V) tr = tr * flipV; // calculate the inverse tr = inverse(tr); // and finally apply it to the original texture matrix const mat4 texTransform(mat4(static_cast<const float*>(textureMatrix)) * tr); memcpy(textureMatrix, texTransform.asArray(), sizeof(textureMatrix)); } // Set things up for texturing. mTexture.setDimensions(mActiveBuffer->getWidth(), mActiveBuffer->getHeight()); mTexture.setFiltering(useFiltering); mTexture.setMatrix(textureMatrix); engine.setupLayerTexturing(mTexture); } else { engine.setupLayerBlackedOut(); } drawWithOpenGL(hw, clip, useIdentityTransform); engine.disableTexturing(); }
里面关键就是drawwithOpenGL,可见是由Open GL来合成layer。