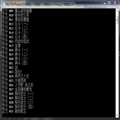
在贴吧看了个小说追了几天被删帖了,于是自己找书名,打算下载下来看,结果要么是需要充值,要么不提供下载。作为一个猿类,怎么能忍。
好在小说网站多入牛毛,有的采用js加载文字来防采集,有的用css图片替换个别文字来防采集,但这都不是我们今天要攻克的对象,我们只想找一个软柿子来捏捏不想花太多时间和精力,于是就找到了下面的网站,网址我就不放了(我不会告诉你们源码里有的)。
本意是不想花太多时间和精力的,没想到写个博客分享下比写个代码花的时间还多。。。。写代码才花了15分钟,写博客花了我1个小时。


Jumony是一个开源项目,主要作用是提供程序员完整的HTML掌控能力,可以用CSS3选择器进行元素的拾取。除了可以做HTML解释器以外,还可以直接进行数据抓取。
此处只举一个例子,通过加载网页,然后像JQuery的操作方式一样找到元素,并输出
foreach( var title = new JumonyParser().LoadDocument( "http://www.cnblogs.com/" ).Find( ".post_item a.titlelnk" ) )
Console.WriteLine( title.InnerText() );
vs菜单的工具-》Nuget程序包管理器-》管理解决方案的Nuget包
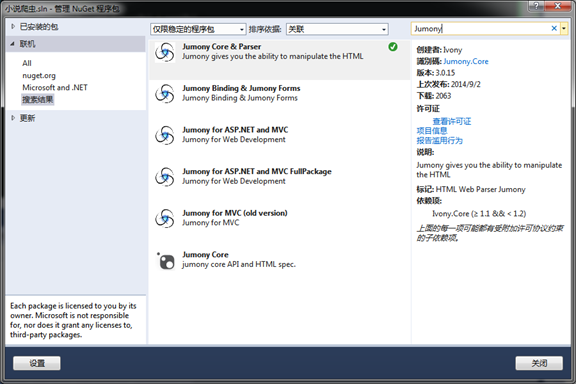
为何叫简短的实战,因为整个过程真的非常简短就完成了。
首先打开小说的正文部分,用F12查看元素,发现小说的正文是完整的文本,并且是放在id="content"的一个div里的

所以只要用 #content就能找到我们要的元素,并且输出正文,并没有什么难点

找到标题,然后呢,这里用一个黑科技直接拿到css选择器

通过F12提供的Copy CSS path,可以无脑的直接获取到css选择器

于是title部分的代码

和前面一样,找到下一页的css选择器,这次获取的不是innerText了,这次获取的是href的value,然后Copy css Path。

结果就是如下

思路就是继续循环,一直跟着nextUrl往下抓取就是咯
static void Main(string[] args) { FileStream fs = null; if (File.Exists("D\\c.txt")) { fs = new FileStream("D:\\c.txt", FileMode.Append); } else { fs = new FileStream("D:\\c.txt", FileMode.Create); } StreamWriter sw = new StreamWriter(fs, Encoding.UTF8); string baseUrl = "http://www.42xs.com/read/0/404/"; var nextUrl = "171271.html"; string url = ""; string txt = ""; string title = ""; while (nextUrl != "") { try { url = baseUrl + nextUrl; var doc = new Ivony.Html.Parser.JumonyParser().LoadDocument(url); var titleDom = doc.FindFirst("#center > div.title > h1"); title = titleDom.InnerText(); var dom = doc.FindFirst("#content"); txt = dom.InnerText(); var domNext = doc.FindFirst("#container > div:nth-child(3) > div > div.jump > a:nth-child(6)"); nextUrl = domNext.Attribute("href").Value(); } catch { Console.WriteLine(string.Format("{0}没有成功", url)); nextUrl = ""; } Console.WriteLine(title); sw.WriteLine(""); sw.WriteLine(title); sw.WriteLine(""); sw.WriteLine(txt); } Console.Write("The End. Press any key to exit..."); Console.ReadKey(); sw.Close(); fs.Close(); }