
今天,全世界最不可能被盗号的人被盗号了,他就是世界最大社交网站的 CEO 扎克伯格。不仅如此,扎克伯格的密码还简单得让人大跌眼镜——“dadada”。这个没有任何大小写区分、没有数字和其他符号的密码,黑客只要不到 25 秒就能破解。
笑谈之余,这个新闻让人们再次思考,未来更加安全的网络身份验证技术是什么?也许,正如未来人工智能语音交互将代替现在的 APP 交互,身份验证也会采用人工智能语音验证。谷歌的研究让我们看到,未来登录社交网站,也许只要说一句:“OK Google!”
谷歌 Brain 的研究人员们在一篇名为《端到端基于文本的语音验证》的论文中,介绍了一种神经网络架构,能为高精度、容易维护的小型大数据应用(例如谷歌的应用),提供用户语音验证。这篇论文发表于 IEEE 2016 声学、语音和信号处理国际大会(ICASSP)上。
今年 8 月,谷歌 DeepMind CEO Demis Hassabis 也将参加雷锋网(搜索“雷锋网”公众号关注)举办的人工智能与机器人创新大会。在此,雷锋网分享论文全文内容。
论文作者简介
George Heigold 在加入谷歌前,在德国亚琛工业大学计算机学院任教,2010 年成为谷歌研究科学家,研究领域包括自动语音识别、语音识别中的区分性训练和对数线性模型等。
Samy Bengio 2007 年加入谷歌担任研究科学家,之前在瑞士 IDIAP 研究院担任高级研究员并培养 PhD 博士生及博士后研究员。同时,他还是《机器学习研究期刊》编辑、IEEE 信号处理神经网络工作室项目主席以及 IJCAI 等知名学术期刊的项目委员。他的研究领域覆盖机器学习的许多方面。
Noam Shazeer 毕业于杜克大学,一直在谷歌担任研究科学家。研究领域包括语音学、自然语言处理和计算机科学。
Ignacio Lopez-Moreno 是谷歌软件工程师,正在攻读博士学位,曾获 IBM 研究最佳论文等奖项。他的研究领域包括语音识别、模式识别等。
论文摘要
这篇论文中我们将呈现一种数据驱动的整合方法,来解决用户语音验证问题。我们将一个测试发音与几个参考发音进行比较,直接生成一个配对分数进行验证,并在测试时使用相同的评估协议和维度来优化系统部件。这样的方法可以创造简单、高效的系统,不需要了解领域特定的语言,也不需要进行模型假设。我们将概念落地,将问题表达为一个单个神经网络架构,包括只用几个发音来评估一个语音模型,并且用我们内部的“OK Google”基准来评估基于文本的语音验证。对于类似谷歌这样要求高精度、系统容易维护的小型大数据应用来说,我们提出的方法非常有效。
1、简介
语音验证指的是基于已知的用户发音,来验证一个发音是否属于该用户的验证过程。当在所有用户中,发音中的词汇仅限于一个单词或词组,这个过程称为基于文本的通用密码语音验证。通过限制词汇,基于文本的语音验证可以弥补发音的不同变化,发音是语音验证中的一个重大挑战。在谷歌,我们想用这个通用密码“OK Google”来研究基于文本的语音验证。之所以选择这个特别短、大约费时 0.6 秒的通用密码,是与谷歌关键字辨认系统和谷歌语音搜索有关,能够帮助我们把这几个系统结合起来。
这篇论文中,我们提出直接将一个测试发音和几个发音匹配,建立用户的模型,用一个分数来进行验证。所有部件是遵循标准语音验证协议,进行联合优化。与现有的办法相比,这样一种端到端的办法有几个优势,包括发音的直接建模,这样可以理解更大的语境、减少复杂度(每次发音是一个或多个帧的评估),以及直接且联合的预估,能够创建更好、更简洁的模型。而且,这种方法创建的系统经常要间接得多,所需的概念和方法都更少。
更具体地来说,这篇论文的贡献主要包括:
建立了一个端到端语音认证架构,包括基于若干个发音预估用户模型(第 4 部分);
端到端语音验证的实证评估,包括帧(i-矢量与d-矢量)和发音层面表征的比较(第 5.2 部分),以及端到端损失的分析(第 5.3 部分)。
前馈控制和循环神经网络之间的实证比较(第 5.4 部分)。
这篇论文集中讨论基于文本语音验证在小型系统上的应用。但是这种方法可以普遍应用,也可以用在无关文本的语音验证上。
在之前的研究中,验证问题被分解为更容易处理的子问题,但是子问题之间关联较为松散。举个例子,在无关文本的语音验证和基于文本的语音验证中,i-矢量和概率线性判别分析(PLDA)的结合一直都是主流方法。另外,也有研究证明混合方法(包括基于深度学习的部件)有助于无关文本的语音识别。然而,对于小型系统来说,一个更直接的深度学习模型可能更好。据我们所知,循环神经网络在其他相关问题上已经有了应用,例如语音识别和语言识别,但是还未曾用于语音验证任务。我们提出的神经网络架构可以看作是一个生成模型-判别模型混合体的联合优化,与适应的深度展开类似。
这篇论文其余部分的结构如下:第 2 部分提供了语音验证的简短综述。第 3 部分描述了d-矢量方法。第 4 部分介绍了我们提出的端到端语音验证方法。第 5 部分你可以看到实验评估和分析。第 6 部分是论文的总结。
2、语音验证协议
标准语音验证协议可以被分为三个步骤:训练、注册和评估,我们接下来会详细介绍。
训练:
在训练阶段,我们从发音中找到一个合适的内部语音表征,这样能有一个简单的打分功能。总的来说,这种表征取决于模型的类型(例如,子空间高斯混合模型或者深度神经网络)、表征层级(帧或发音)以及模型训练损失(例如,最大可能性或者 softmax)。最好的表征是帧层级信息的总结,例如i-矢量和d-矢量(第 3 部分)。
注册:
在注册阶段,用户提供了若干个发音(见表格1),用来预估用户模型。常见的办法是取这些发音中i-矢量或者d-矢量的平均值。
评估:
在评估阶段,我们进行验证任务,系统也进行评估。为了验证,发音 X 的打分函数值和测试用户 spk, S (X, spk),与一个预先定义的阈值进行比较。如果分数超过阈值我们就接受,也就是说,判断发音 X 来自用户 spk,反之,如果没有超过阈值我们就拒绝,判断发音 X 不来自于用户 spk 。在这个设定中可能会出现两种类型的错误:错误拒绝和错误接受。显然,错误拒绝率和错误接受率取决于阈值。当这两项比率相同时,这项值称为相等错误率(EER)。
一个简单的打分函数,是发音 X 评估结果的用户表征 f (X),与用户模型 mspk 之间的余弦相似度。
S (X, spk) = [ f (X)T mspk ] / [ f (X) mspk ]
我们提出 PLDA 作为一种更加精确、数据驱动的打分方法。
3、D-向量基准方法
D-向量是从一个深度神经网络(DNN)中而来的,作为一个发音的用户表征。一个 DNN 包括了若干个非线性函数的连续应用,从而将用户发音转化为矢量,这样可以轻松进行决策。下面的图表 1 描绘了我们基准 DNN 的拓扑学。它包括一个本地联接的层,以及若干个完全联接的层。所有层都使用 ReLU 启动,除了最后一个线性层。在训练阶段,DNN 的参数使用 softmax 来最优化,为了方便起见,我们的定义包含一个线性转化,有一个权重矢量 wspk 和偏差 bspk,后面加上一个 softmax 函数和叉熵损失函数:
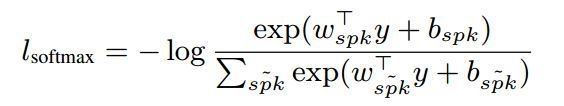
最后一个隐藏层的启动矢量标记为 y,正确用户标记为 spk。
训练阶段完成后,DNN 的参数就确定了。发音d-矢量的获取方法是,发音所有帧的最后一个隐藏层的启动矢量的平均值。每个发音生成一个d-矢量。为了进行注册,对注册发音的d-矢量进行平均,就获得了用户模型。最后,在评估阶段,打分函数是用户模型d-矢量和测试发音d-矢量之间的余弦相似度。
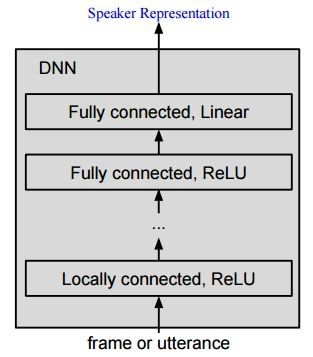
图表1
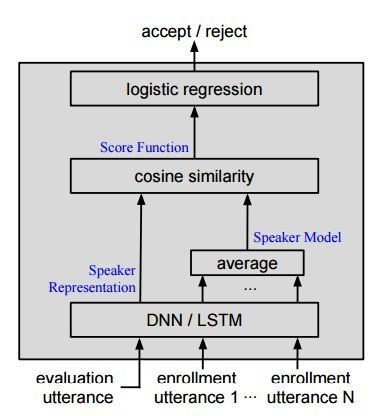
图表2
对这项基准方法有一些批评,包括从帧而来的d-矢量的情景局限以及损失的类型。softmax 损失函数有望从所有用户中区分出真正的用户,但是在第 2 部分没有遵守标准验证协议。这样的结果是,必须要有方法和评分标准化技术来弥补不一致性。而且,softmax 损失函数没法很好地扩大化,因为计算复杂度是线性的,每个用户必须有最少量的数据来评估具体用户的权重和偏差。可以用候选人取样方法来减轻复杂度问题(而非预估问题)。
对于其他的语音验证方法我们也可以指出同样的问题,其中一些部件块要不是联系松散,要不就是没有遵循语音验证协议直接优化。举个例子,GMM-UBM 或者 i-矢量模型没有直接优化验证问题。或者比较长的情景特征可能被基于帧的 GMM-UBM 模型忽视。
4、端到端用户验证
在这个部分,我们将用户验证协议的各个步骤整合为一个单一的网络(见图表2)。这个网络的输入由一个“评估”发音和一小组“注册”发音组成。输出是一个单一的节,指明是接受还是拒绝。我们使用 DistBelief 来联合优化这个端到端架构,它是 TensorFlow 的一个早期版本。用这两种工具,复杂的计算图表(例如我们端到端拓扑学定义的那个图标)可以分解为一系列操作,具有简单的梯度,例如总和、分区和矢量的交叉产品。在训练步骤之后,所有网络权重保持不变,除了一维逻辑回归的偏差(图表2)是根据注册数据手动调试的。除此以外,注册步骤什么也没有做,因为用户模型预估是网络的一部分。在测试的时候,我们在网络中输入一个评估发音和要测试的用户的注册发音,网络直接输出判断结果。
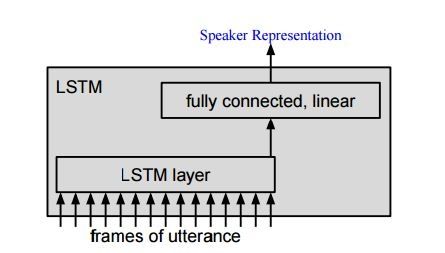
图表3
我们使用神经网络来获取发音的用户表征。我们在研究中使用的两种网络类型,在图表 1 和图表 3 中:一个深度神经网络(DNN),带有本地联接和完全联接的层作为我们第 3 部分的基准 DNN,以及一个长短时记忆循环神经网络(LSTM),和一个单一输出。DNN 假设输入长度固定。为了符合这项限制,我们将一个固定长度、足够时长的帧叠加到发音上,作为输入。对 LSTM 就不需要这招了,但是我们为了更好的可比性,使用同样的帧时长。与具有多个输出的 LSTM 不同,我们只连接最后一个输入到损失函数,来获得单一的、发音层级的用户表征。
用户模型是一些“注册”表征的平均。我们使用相同的网络来计算“测试”发音和用户模型发音的内部表征。通常,实际的每个用户发音数量(几百个或更多)比在注册阶段(十个以内)多得多。为了避免错误配对,每一个训练发音,我们只从同一个用户获取几个样本发音,来在训练阶段创建用户模型。总体来说,我们没法假设每个用户有N个发音。为实现可变的发音数量,我们在发音上加入权重来指明是否要使用这个发音。
最终,我们计算出用户表征和用户模型 S ( X, spk)之间的余弦相似度,把它输入一个包括有偏差线性层的逻辑回归。架构是使用端到端损失函数 le2e = − log p (target) 来最优化,其中二维变量 target ∈ {accept, reject}, p (accept) = (1+exp (−wS (X, spk)−b))−1,以及p(reject) = 1−p(accept)。-b/w 的值相当于验证阈值。
端到端架构的输入是 1+N 个发音,例如,一个要测试的发音,和最多N个不同的用户发音,来预估用户模型。为了实现数据处理和内存之间的平衡,输入层维护一个发音库来为每一个训练步骤获取1+N个发音样本,并经常更新以实现更好的数据处理。由于用户模型需要同一个用户特定数量的发音,数据的呈现方式是同一个用户的一小组发音。
5、实验评估
我们使用内部的“OK Google”基准来评估我们提出的端到端方法。
5. 1. 数据组合基本设定
我们用一组从匿名的语音搜索记录中收集来的“OK Google”发音,来测试我们提出的端到端方法。我们实行了多种风格的训练,来提升噪音强度。我们人工加入了汽车和餐厅噪音来增强数据,并模拟用户发言时与麦克风的不同距离。注册和评估数据只包括真实数据。表格 1 展示了一些数据组的统计数据。
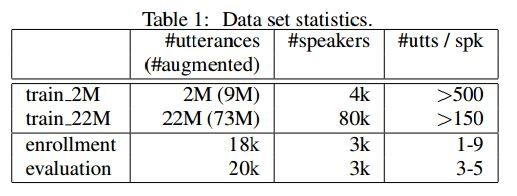
表格1
发音强制统一起来,从而获取“OK Google”的片段。这些片段的平均长度大约是 80 帧,帧率是 100Hz。基于这项观察结果,我们从每一个片段抽取最后的 80 帧,有可能在片段的最初和最后增减了一些帧。每一帧由 40 个滤波器组日志组成。
对 DNN 来说,我们将 80 输入帧连接起来,这样有了一个 80x40 维度的特征矢量。除非另外说明,DNN 由 4 个隐藏层组成。DNN 里所有隐藏层有 504 个节,使用 ReLU 启动,除了最后一个线性层。DNN 中本地连接层的区块大小是 10x10。对 LSTM,我们将 40 维度的特征矢量一帧一帧地输入。我们使用一个有 504 个节的单个 LSTM 层,没有投影层。所有试验中的批量大小都是 32。
结果是按相等错误率(ERR)来汇报的,包括没有及有t分数标准化的两个类别。
5. 2. 帧层面 vs 发音层面的表征

表格2
首先,我们比较帧层面和发音层面的用户表征(见表格2)。这里,我们使用了一个图表 1 中所描述的 DNN 和一个 softmax 层,使用 train_2M (见表格1)来进行训练,在线性层面有 50% 的丢失。发音层面的方法比帧层面的方法更好,超出 30%。在每一种方法中,分数标准化技术带来了重大的运行提升(相对提升了 20%)。为了比较,这里展示了两个i-矢量基准。第一个基准是基于表格 2 中的6,使用 13 PLP 以及一阶和二阶导数、1024 高斯和 300 维度的i-矢量。第二个基准是基于表格 2 中的 27,有 150 个本征音。i-矢量 +PLDA 基准应该还得打些折扣,因为 PLDA 模型的训练只使用了 2M_train 数据库的一个子集(4k 用户、每个用户 50 个发音),这是因为我们目前实施方面的局限(不过,这与每个用户只用 30 个发音训练的结果几乎是一样的)。另外,这个基准没有包括其他的改善技术,例如“不确定性测试”,这项测试已经证实在特定情况下可以给出很多额外增量。我们已经大大提升了我们的d-矢量。
5. 3 Softmax 函数 vs 端到端损失函数
接下来,为了训练发音层级的用户表征,我们比较了 softmax 损失函数(第 2 部分)和端到端损失函数(第 4 部分)。表格 3 显示了图表 1 中的 DNN 的同等错误率。它用了一个小训练库来训练(train_2M),原始分数的错误了可以和不同的损失函数相比。虽然损失让 softmax 函数获得了1% 的绝对增益,对于端到端损失函数我们没有观察到损失带来任何增益。类似的,t标准化对 softmanx 函数有 20% 的帮助,但是对端到端损失函数没有任何帮助。这项结果符合训练损失和评估维度之间的一致度。尤其是端到端方法在训练中假设了一个通用阈值,可以不经意地学会标准化分数,标准化分数在不同的噪音情况下维持不变、让分数标准显得多余。当我们为启动端到端训练而使用 softmax DNN,错误率从 2.86% 减少到了 2.25%,意味着存在预估问题。
如果用更大的训练组(train_22M)来训练,端到端损失函数明显比 softmax 函数更好,见表格3。为了合理地将 softmax 层扩大到 80k 个用户标签,我们使用了候选人取样方法。这次,t标准化也为 softmax 函数带来了 20% 的帮助,softmax 可以跟得上其他损失函数,它们从t标准化中没有什么获益。端到端训练的启动(随机 vs “预先训练”的 softmax DNN)在这种情况下没有什么影响。
虽然用了候选人取样,端到端方法的步骤时间比 softmax 方法更长,因为用户模型是运行中计算出来的,总体收敛时间还是相当的。
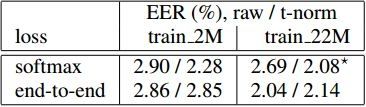
表格3
训练中预估用户模型的发音数量被称为用户模型大小,最佳的选择要看注册发音的(平均)数量。但是,实际上更小的用户模型大小反而可能更好,更能缩短训练时间、并让训练更难。图表 4 展现了测试同等错误率对用户模型大小的依赖性。最适宜范围相对较宽,模型大小大约为5,同等错误率为 2.04%,相比之下,模型大小为 1 时有 2.25% 的同等错误率。这个模型大小近似于真实的平均模型大小,对我们的注册组来说大小是6。这篇论文中的其他配置(未展示)也看到了类似的趋势。这意味着,我们提出的训练算法与验证协议之间有一致性,意味着针对具体任务的训练会更好。
5. 4. 前馈控制 vs 循环神经网络
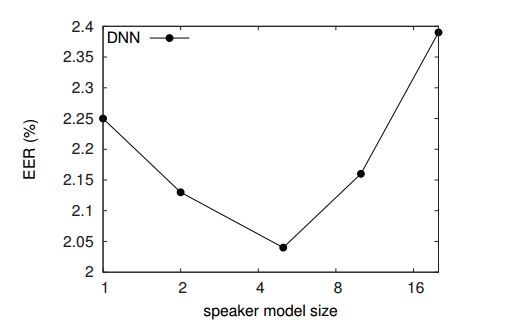
图表4
目前为止,我们集中讨论图表 1 中的“小型”DNN,带有一个本地联接层和三个完全联接的隐藏层。接下来,我们探索更大的、不同的网络架构,与它们的大小和计算复杂度无关。结果总结在图表 4 中。与小型 DNN 相比,“最好”的 DNN 使用一个额外的隐藏层,有 10% 的相对增益。图表 3 中的 LSTM 在最佳 DNN 的基础上又增加了 30% 的增益。参数数量与 DNN 的相似,但是 LSTM 多了 10 倍的乘法和加法。更多的超级参数调试有望降低计算复杂度,增加可用性。使用 softmax 损失函数(运用t标准化、候选人取样以及可能提早暂停,这些技术在端到端方法中都是不需要的)。在 train_2M 中,我们观察到错误率在相应的 DNN 基准上有相似的相对增益。

表格4
6、总结
我们提出了一个新的端到端方法,来解决用户的语音验证问题,直接将发音配对打分,并用训练和评估相同的损失函数来联合优化内在的用户表征和用户模型。假如有足够的训练数据,使用我们的内部基准“OK Google”,我们提出的方法可以将小型 DNN 基准的错误率从3% 改善为2%。大部分增益来源于发音层级 vs 帧层级建模。与其他损失函数相比,端到端损失函数使用了更少的额外概念,却实现了同样的、或者略微更好的结果。例如在 softmax 的情况中,我们只有在运行中使用分数标准化、候选人取样让训练变得可行,才能获得同等的错误率。而且,我们展示了使用循环神经网络而非一个简单的深度神经网络,可以进一步将错误率减少到 1.4%,虽然计算运行时间成本更高了。相比之下,一个合理但不是最佳的 i-矢量/PLDA 系统的错误率是 4.7%。显然,我们还需要更多的比较研究。不过,我们相信我们的方法为大数据验证应用,展现了一种大有前途的新方向。
via Google Research









