摘要
不久前,一篇名为《黄焖鸡米饭是怎么火起来的》文章引起了数据领域的广泛关注,作者使用大数据分析的形式直观显示了黄焖鸡米饭的发展过程。今天在这篇文章里,我们将从原材料准备(数据来源和爬取)出发,抽丝拨茧,为您一步一步详细讲解如何才能写出这么一篇图文并茂的数据分析文章。内含大量源码哦~
正文
去年开始研究做爬虫,搞了一套分布式的爬虫系统,主要目标是帮别人做数据采集。后来看到黄焖鸡米饭是怎么火起来的这篇文章,进而关注了《数据冰山》,发现里面的大数据分析的文章都相当有意思,图表也一个比一个专业。我当时的表情大约是这样的:
我的天哪,这么神奇吗? 放下手机,操起键盘,正准备也搞上一篇 “大数据分析:郭德纲和女演员的相爱相杀之后,wuli涛涛是如何火起来的”。后来转念一想,这不是赤果果的抄袭了,妈妈是怎么教导我的。再说了,以我这样的实力,写了这样的文章,以后别人还怎么写呢?

俗话说得好:授人以鱼不如授人以渔,独乐乐不如众乐乐。不如我们就以黄焖鸡米饭为例,给大家讲讲如何才能写出这样一篇图文并茂的分析文章来吧。
先来一段硬广:本文所有代码,都需要运行在本人搭建的神箭手云爬虫框架上,打算完全自己写爬虫的同学,领会精神即可。
?? 数据来源分析
首先需要黄焖鸡米饭门店的创建时间,来分析黄焖鸡米饭随时间的增长,其次需要门店的地域信息来分析不同地域黄焖鸡米饭的增长情况。
分析大众点评的商户门店信息,可以在商户的贡献榜页面找到相关的信息,如下图:
?
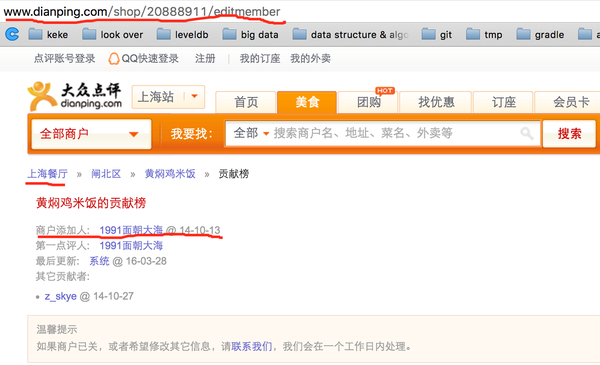
这里需要对数据作几个近似处理:
??? 仅选取商户名中包含"黄焖鸡米饭"的门店
??? 将商户的添加时间近似看作门店的创建时间
??? 大众点评无法查到已经关闭的商户,所以这里不考虑门店的关闭,仅选取现存的门店
??? 开始写爬虫
上面分析了对数据的需求,下面就开始动手写爬虫爬取数据啦~
熟悉爬虫的人都知道,一个爬虫的基本工作流程是:
??? 首先挑选一部分种子URL(也可以叫入口URL),并放入到待爬队列中
??? 从待爬队列中取出一个URL,下载内容并从中抽取信息,同时发现新URL,并加入到待爬队列中。重复此步骤,直至待爬队列为空。
上面加粗了3个重点,种子URL、抽取信息和发现新URL。
??? 种子URL
也可以叫入口URL,爬虫以这些URL为入口,以某种规则发现新的URL,最终爬遍所有想要的网页。为了爬取高效,我决定直接用大众点评的搜索,选择大众点评的搜索结果页作为入口URL,爬取结果页的所有商户并筛选后作为样本数据。大众点评的搜索也是分区域的,要把所有区域的搜索结果页都作为入口URL,形如
http://www.dianping.com/search/keyword/{region_id}/0_%E9%BB%84%E7%84%96%E9%B8%A1%E7%B1%B3%E9%A5%AD
其中region_id从1到2323(很容易可以发现此范围内是中国的区域,数字再大就到国外了,如果多了或者少了请告诉我)。
??? 抽取信息
从网页中抽取信息,最常用的是xpath,这里我们需要抽取商户id(防止重复),商户名称(过滤掉不含黄焖鸡米饭的),创建时间,区域名称,省份是没有的,需要根据区域名称得到。xpath可以结合Chrome的开发者工具来写,并通过xpath插件来验证,下面给出这几项数据的xpath:
商户id,抽取的数据中包含其他商户id,需要进一步处理来得到id
//div[contains(@class,'shop-review-wrap')]/div/h3/a/@href
商户名称
//div[contains(@class,'shop-review-wrap')]/div/h3/a/text()
创建时间,需要进一步字符串处理后得到时间
//div[contains(@class,'block raw-block')]/ul/li[1]/span
区域名称,同样文本需要处理
//div[@class='breadcrumb']/b[1]/a/span/text()
??? 发现新URL
URL的发现规则不是必须配置的,但是配置之后,可以大大提高爬虫的速率。对于大众点评这样规整的列表页+详情页,配置好列表页的url规则和详情页的url规则,爬虫的目标就很明确,爬取速率杠杠的。一般这种规则用正则来表示,对于这里的爬虫,列表页规则为
http://www.dianping.com/search/keyword/\\d+/0_.*
详情页规则为
http://www.dianping.com/shop/\\d+/editmember
另外,大众点评限制了IP的访问频率,这里可以把降低爬取速率,或是使用代理。如果你使用的是神箭手云爬虫,则代码如下
configs.enableProxy = true;
自己写爬虫的同学,请自行Google代理IP,此处不再赘述。
??? 用爬取的数据配置出图表
折腾出了这么多代码,约摸着看到这的都是真爱了,那么赶紧看看我们的成果吧:
?
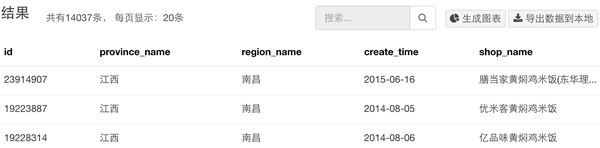
总共爬取到14000多条数据,现在就以这些数据作为样本来分析(下面涉及到的图表的设置,都是在神箭手云平台上操作完成的)。
1. 黄焖鸡米饭的整体增长
像原文里的分析一样,以季度为单位,作出2012年至2016年,黄焖鸡米饭的门店数随时间的增长情况。先看下出来的图:
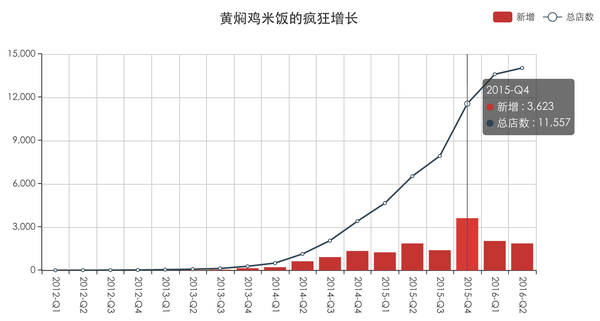
上图中,柱形绘制的是各个季度门店的新增数,折线绘制的是截止到某个季度的总门店数。对于柱形图/折线图,首先设置X轴和Y轴。Y轴比较简单,就是门店数,值类型是value,一个Y轴就可以了,不需要第二个Y轴;X轴是按季度划分的,值类型是category,需要在爬取结果的create_time字段上作区间划分,这里展示的"新增"和"总店数"两个数据,它们的统计区间是不一样的,"新增"统计的是create_time落在某个季度的门店数,而"总店数"统计的是create_time在某个季度之前的门店数,所以这里的区间划分需要定义两个。
X轴和Y轴定义好之后,开始定义数据。
新增数展示为柱形图。X轴的字段选择create_time,在create_time上划分区间,这里通过简单的字符串比较就可以划分出季度区间,比如"2013-Q2",定义它的最小值为"2013-04-01",最大值为"2013-07-01"。Y轴只需要对划分出的区间作count操作就可以,所以配置Y轴字段为'*',操作选择计数。
总店数展示为折线图。总店数跟新增数唯一的区别就是区间划分,比如"2013-Q2",只定义它的最大值为"2013-07-01"就好了。
下图为部分设置界面。
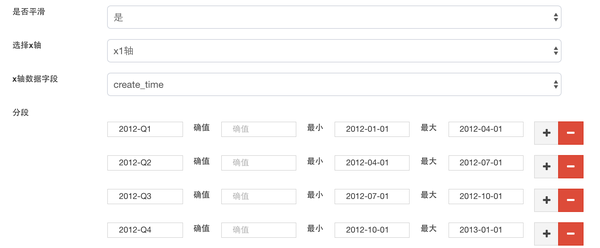
配置完成后保存,就可以查看生成的图表了。
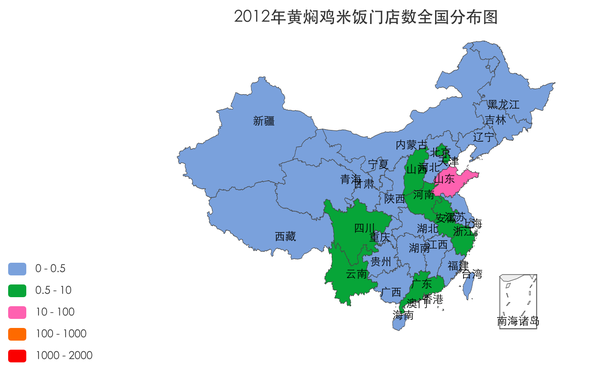
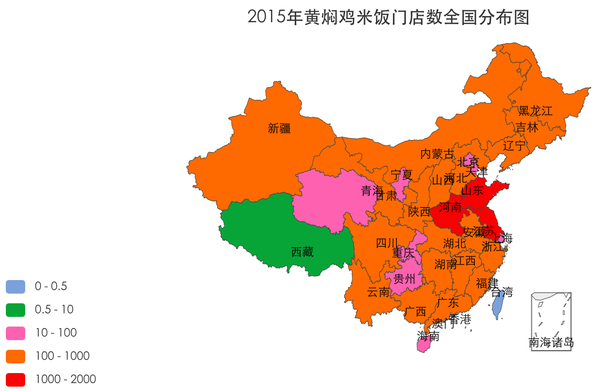
2. 分区域分析黄焖鸡米饭的增长
逐年观察各个省份黄焖鸡米饭门店数的增长情况,时间维度体现在多张图上,省份的数据通过中国地图的着色深浅来表示。先看效果图:
?


?
?
图表类型为中国地图,配置也比较简单。首先在create_time上添加过滤条件来配置年份,比如要配置2014年的地图,添加过滤条件,字段选择create_time,设置最大值为"2015-01-01";配置区域字段为province_name,数据还是计数操作,选择字段为'*',操作为count。这样就会筛选出2014年底黄焖鸡米饭的门店,并以省为单位,分别统计门店个数。最后设置图例,不同门店数用不同的颜色填充,就可以作出上面的系列图。
大功告成,一碗热腾腾的黄焖鸡米饭就可以上桌了,如果想搞什么大盘鸡,小盘鸡,红烧肉,KTV啥的的,相信你都已经不在话下了吧。
代码信息:
github上分享了所有的代码
https://github.com/ShenJianShou/crawler_samples/blob/master/dianping.js
最后附上神箭手云爬虫链接,对云爬虫开发有兴趣的童鞋,欢迎来看看哦
http://www.shenjianshou.cn/
?