???????? ?XML 指可扩展标记语言XML ,被设计用来传输和存储数据。从某种角度来说,XML是数据封装和消息传递技术。许多框架的配置文件都是使用XML,所以有必要学习XML。
??????????java的XML解析主要有两种方式:DOM和SAX。
?
1.DOM解析XML
?????DOM与语言平台无关,将XML文档建立一个完整的文档树,在内存中解析和存储XML文档,允许随机访问文档的不同部分。
优点:由于整棵树在内存中,因此可以对xml文档进行随机访问;可以对xml文档进行修改操作,API使用起来比较简单。
缺点:整个文档都需要载入内存,对于大文档成本高
???? 我们这里说的是java自带的DOM解析方式,不使用第三方类库,DOM解析方式还有两种比较有名的解析方式JDOM和dom4j(dom4j使用最多,需要引入第三方类库,详情地址)
????要解析的XML文档如下:
class="xml" name="code"><?xml version="1.0" encoding="UTF-8"?> <Teachers> <teacher id="1001"> <name>黄小米</name> <age>28</age> <sex>男</sex> </teacher> <teacher id="1002"> <name>李小璐</name> <age>30</age> <sex>女</sex> </teacher> <teacher id="1003"> <name>王尼玛</name> <age>38</age> <sex>男</sex> </teacher> </Teachers>
?
使用DOM解析代码及注释:
package Myclass;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Test {
public static void main(String[] args) throws Exception{
//创建dom解析器工厂
DocumentBuilderFactory df=DocumentBuilderFactory.newInstance();
//生成解析器
DocumentBuilder builder=df.newDocumentBuilder();
//返回Document对象,准备解析
Document doc=builder.parse(new File("F:\\NewFile.xml"));
//根据结点获取数据
NodeList teachers=doc.getElementsByTagName("teacher");
//依次读取结点数据
for(int i=0;i<teachers.getLength();i++)
{
//获取结点
Node teacher=teachers.item(i);
//获取老师id
String id=teacher.getAttributes().getNamedItem("id").getNodeValue();
System.out.print("老师编号:"+id);
//获取该结点的所有子结点
NodeList son=teacher.getChildNodes();
//输出子结点的数据
for(int j=0;j<son.getLength();j++)
{
//获取结点
Node ok=son.item(j);
//获取结点名
String name=ok.getNodeName();
//输出老师名字
if(name.equals("name"))
System.out.print(" 姓名:"+ok.getFirstChild().getNodeValue());
//输出老师年龄
if(name.equals("age"))
System.out.print(" 年龄:"+ok.getFirstChild().getNodeValue());
//输出老师性别
if(name.equals("sex"))
System.out.print(" 性别:"+ok.getFirstChild().getNodeValue()+"\n");
}
}
}
}
?
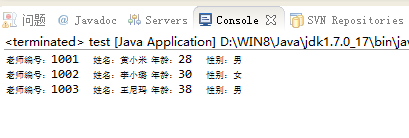
运行结果:
?
2.SAX解析XML
???? SAX,全称Simple API for XML,既是一种接口,也是一种软件包。它是一种XML解析的替代方法。SAX不同于DOM解析,它逐行扫描文档,一边扫描一边解析。由于应用程序只是在 读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势。SAX是一个用于处理XML事件驱动的“推”模型。
特点:只能顺序读取文档,使用的是事件处理机制。内存占用少,不能随机读取。
?
解析XML代码和注解:
1.根据xml自定义Teacher类
package Myclass;
public class Teacher {
public String id;
public String age;
public String sex;
public String name;
}
?
2.实现事件处理器,继承DefaultHandler类(解析重点难点,基于事件处理)
package Myclass; import java.util.ArrayList; import java.util.List; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class TeacherHandler extends DefaultHandler { public List<Teacher> teachers; public Teacher temp; public String tag; // 开始解析xml触发 @Override public void startDocument() throws SAXException { // 实例化teachers teachers = new ArrayList<Teacher>(); } // 解析完成时调用 @Override public void endDocument() throws SAXException { super.endDocument(); System.out.println("解析完成"); } // 解析开始元素时调用,即<xx>,如<teacher>,<name> @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { // 获取老师id if (qName.equals("teacher"))// 读取到<teacher> { // 实例化Teacher,存储Teacher结点的数据 temp = new Teacher(); // 获取老师id temp.id = attributes.getValue("id"); } // 设置标记 tag = qName; } // 解析文本内容时触发--需要注意xml里的空格和换行也会触发,此时需要标记tag @Override public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); if (tag != null) { if (tag.equals("name")) temp.name = new String(ch, start, length); if (tag.equals("age")) temp.age = new String(ch, start, length); if (tag.equals("sex")) temp.sex = new String(ch, start, length); } } // 解析结束元素时调用,即</xx>,如</teacher>,</name> @Override public void endElement(String uri, String localName, String qName) throws SAXException { super.endElement(uri, localName, qName); // 读取完一个teacher结点把数据添加到List里 if (qName.equals("teacher")) teachers.add(temp); //清除标记 tag=null; } //返回解析的List数据 public List<Teacher> getTeachers() { return teachers; } }
?
3.实现SAX解析
package Myclass;
import java.io.File;
import java.util.List;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SAX {
public static void main(String[] args)throws Exception {
//创建SAX解析工厂
SAXParserFactory factory=SAXParserFactory.newInstance();
//创建解析对象
SAXParser sax=factory.newSAXParser();
//创建时间处理器
TeacherHandler handler=new TeacherHandler();
//开始解析
sax.parse(new File("F:\\NewFile.xml"), handler);
List<Teacher>data=handler.getTeachers();
//输出结果
for(int i=0;i<data.size();i++)
{
Teacher ok=data.get(i);
System.out.println("老师编号:"+ok.id+" 姓名:"+ok.name+" 年龄:"+ok.age+" 性别 :"+ok.sex);
}
}
}
?
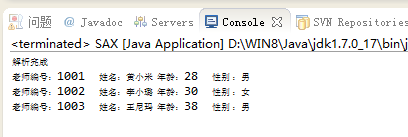
运行结果:
?
?
?