uniVocity-parsers ��һ����Դ��Java��Ŀ�� ���CSV/TSV/�����ı��ļ���
���������Լ���API����
�ӿ��ṩ�˷ḻ��ǿ��Ĺ��ܡ����������һ�����ܡ�
������������������ͬ��uniVocity-parsers�Ը����ܡ�����չΪ�����㣬�����һ������
�ܹ����������ܹ��������߿��Թ������µ��ļ���������
1. ����
��Ϊһ��Java�����ߣ���Ŀǰ���ڲ��뿪��һ��Web��Ŀ������Ŀ����ͨ����Ӫ��������ǰ�����磬��������������� �ڸ���Ŀ�У�CSV�ļ�������������Ҫ�Ľ�ɫ��������Ӫ���������ݵij��ظ�ʽ����Щ���ݰ��������û���ʵʱ
����״̬������/���ߣ�������ʵʱ������ ͨ������������CSV�ļ����Դﵽ1GB���ϣ������ϰ�������¼����Ŀ��ǰ���õ�CSV������ΪJavaCSV��
������Ӫ�������ģ�����ţ��Լ�ϵͳ������ڵ����ӣ�CSV�ļ�Ѹ�ٱ�� ��Ŀ�鲻�ò��������CSV���ݽ������������������⣨���������뼶�Ľ���Ч�ʣ����Լ�ҵ��仯�����Ĺ�����չ�ܵ�
���������⡣
�����ܶ�εIJ��Ժͷ�������������ȷ������uniVocity-parsers��ΪCSV�ļ������⣬ ʵ��֮��
������ȷʵ��������ǵ����⡣���˸��õ����ܺ�
��չ��֮�⣬�ÿΪ�������ṩ�˼������API�������ĵ��ͽ̡̳� ���ڸ��Ĺ�����չ���ٷ��ṩ��Ӧ���շѷ���
����Ŀ�й���
Github�ϣ�����Ŀǰ������63��star��8��fork�������������������ҵ���ؿ����ĵ��ͽ̳̣�Ҳ�����������ҵ�����
���������š�
ֵ�ù�ע���ǣ�Apache����֪����
��Դ��ĿApache CamelҲ������uniVocity-parsers ����Ϊ����Ŀ����CSV/TSV/�����ı��ļ����Ƽ��⡣ ������Ϣ��鿴���
2. ��װ
������Ŀ��Ŀǰ����1.5.1
�汾�� �Ƽ��Ʋ���uniVocity-parsers�ٷ���վ������
�°汾��
����ĿͬʱҲ����������
Maven�����IJֿ⣬���Ҳ���������pom.xml��ֱ���������´��룺
class="java" name="code"><dependency>
<groupId>com.univocity</groupId>
<artifactId>univocity-parsers</artifactId>
<version>1.5.1</version>
</dependency>
3. ���Լ��
uniVocity-parsers�ṩ��һϵ��ǿ��Ĺ��ܣ��ܹ��ܺõ����������й����б�ʽ���ݵĴ�����������ͼ��չ���˲��ֹؼ����ܣ�
 4. ��ȡ�б�ʽ����
4. ��ȡ�б�ʽ����
��ȡCSV�е�������
CsvParser parser = new CsvParser(new CsvParserSettings());
List<String[]> allRows = parser.parseAll(getReader("/examples/example.csv"));
����鿴�ļ�д����ص����й��ܣ����Ʋ���https://github.com/uniVocity/univocity-parsers#reading-csv
5. д���б�ʽ����
����2�д��룬�Ϳ������CSV��ʽ���ݵ�д�룺
List<String[]> rows = someMethodToCreateRows();
CsvWriter writer = new CsvWriter(outputWriter, new CsvWriterSettings());
writer.writeRowsAndClose(rows);
����鿴�ļ�д����ص����й��ܣ����Ʋ��� https://github.com/uniVocity/univocity-parsers/blob/master/README.md#writing
6. ��������չ��
����Ϊ���ǶԱ� uniVocity-parsers �� JavaCSV �IJ��ԶԱȱ���
�ļ���СJavaCSV������ʱuniVocity-parsers������ʱ10MB, 145453 ��1138ms836ms100MB, 809008 ��23s6s434MB, 4499959 ��91s28s1GB, 23803502 ��245s70s
��������Բ鿴��������CSV����������ܶԱȷ��������ӱ��п��Է��֣�uniVocity-parsers�Ծ����������������⡣
uniVocity-parsers�����ܺ�����Է�������Ƶ�����������ƺͻ��ƣ�
- �Ե����߳���ȡ���ݣ�ͨ������CsvParserSettings.setReadInputOnSeparateThread() �������ã�
- ���е������������� ���ο� RowProcessor ��ʵ���� ConcurrentRowProcessor��
- ͨ���̳� ColumnProcessor ��������ҵ��������������
- ͨ���̳� RowProcessor ��������ҵ��������������
7. �����ʵ��
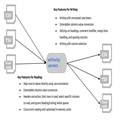
��uniVocity-parsers�У���һЩ���ĵ�
���ݴ���ģ�飬
������������ݰ��ж�д�����ж�д���Լ��������ݵ�ת������������Щ����ģ��Ĺ�ϵͼ��
�����ͨ��ʵ�� RowProcessor �ӿڻ��̳���ʵ�����������Լ������ݴ���ģ�顣���´����У���ͨ�����ڲ�����������Լ������ݴ���ģ�顣
CsvParserSettings settings = new CsvParserSettings();
settings.setRowProcessor(new RowProcessor() {
StringBuilder stringBuilder = new StringBuilder();
/**
* ������һ������֮ǰ������Ը���ҵ��������س�ʼ�����á�
**/
@Override
public void processStarted(ParsingContext context) {
System.out.println("Started to process rows of data.");
}
/**
* �������ҵ����������������
**/
@Override
public void rowProcessed(String[] row, ParsingContext context) {
System.out.println("The row in line #" + context.currentLine() + ": ");
for (String col : row) {
stringBuilder.append(col).append("\t");
}
}
/**
* ���������ݴ������֮��������������
**/
@Override
public void processEnded(ParsingContext context) {
System.out.println("Finished processing rows of data.");
System.out.println(stringBuilder);
}
});
CsvParser parser = new CsvParser(settings);
List<String[]> allRows = parser.parseAll(new FileReader("/myFile.csv"));
uniVocity-parsers���ṩ�����Բ�ֹ��Щ�������������ǵ���Ŀ�з����˺ܴ�����ã��Ƽ����һ���˽⡣