数据是会说话的。
大多数人不知道这一点,知道这一点的人里也有很多听不明白数据说的话。正是因为这样,能和数据进行“沟通”的人,往往知道得更多,更能做出准确的判断和有效的决定。
其实和数据沟通没这么难,很多时候,一些很基本最简单的对话,就能让你获得启发。
我们来看目前国外“最潮”的写作平台 Medium 的一个例子,如何通过分析平台的数据,找到最能让你引起关注的作品集。
分析过程并不难,我保证,人人都能看懂。
在 13 年底,Medium 发布 1.0 版本时,带出了一个重要的变化——所有的写作者在写完文章之后,必须将文章投稿给某个作品集(collection)。由于人人都可以创建作品集,很快 Medium 上就出现了成千上万的作品集,于是,一个问题被抛给了所有的写作者:
“投给什么样的作品集更好?”
要回答这个问题,你可以向 Medium 公司的人寻求建议——如果你的确认识他们的话。不过不认识他们也不要紧,一点儿简单的数据分析的技术就能给你指明方向。
从数据的角度看作品集,有几个专门的指标是可以反应其状况的:1)该作品集的订阅人数;2)文章数;3)最后更新日期。这些指标会影响文章作者向其投稿的意愿。
有人就写代码分析了 Medium 上超过 1000 个作品集,并通过分析结果带出他自己的看法。
分析背景
所有的数据分析都有预设的一些条件。这可能是分析时候的一些背景信息,也可能是分析方法的局限性介绍,或者分析所基于的一些假设。了解这些信息,将有助于你判断分析结果的应用场景和局限性。
1)作品集的选择
该次分析的作品集,是由大约 100 个非随机关键词的搜索得到的。分析者用代码模拟了文章作者,通过关键词搜索作品集的方式。
所以你知道了,这 100 个关键词并非随机得到。而是由分析者根据经验选择的。
2)语言
被分析的是英文文章。所以分析得到的结论并不能简单迁移到别的语言上。
3)最后更新日期
Medium 对于这个日期的定义是:最后一篇文章被放入作品集的日期。也就是说,它不能反应作品集的文章修改情况。
分析过程
1)订阅者与文章数
在分析的这 1000 个作品集中,35% 没有或者只有 1 个订阅者。90% 的作品集的订约人数不到 55 个。
也就是说,Medium 作品集的订阅遵循着幂次定律:一小部分的作品集拥有大规模的订阅者,而大部分的作品集几乎没有订阅者。
作品集所收录的文章数量也是这样。
另外一个现象是:那些最热门的作品集,也拥有最多的文章数量。
所以,往热门作品集投稿,意味着要面临这极大的竞争——你的文章可能很快会被后续文章所淹没,究竟有多少订阅者真正读到了你的文章就成了一个未知数。
很显然,最明智的投稿策略,是选择那些订阅者人数众多,但是文章数量却不太多的作品集。也就是下面的分布图上绿色区域里的那些。
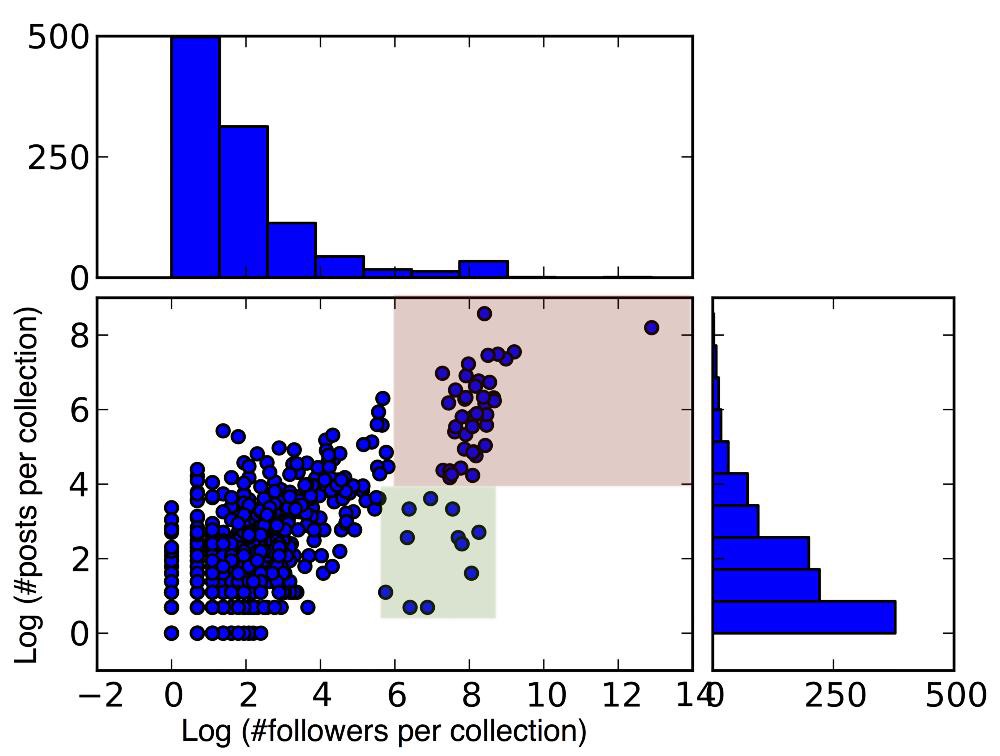
图1
这幅图中,
1)中间的散点图表示了作品集,在订阅人数和包含的文章数上的分布情况,
2)上方柱状图说明了有多少作品集拥有一定数量的订阅者,
3)右侧柱状图则说明有多少作品集包含一定数量的文章。
柱状图显示了近 90% 的作品集只有微量的订阅者和文章数(0~50 之间),而那些有众多拥趸的作品集不到2%。
散点图中红色区域里的作品集,既有高订阅量,也有高文章数,是“竞争激烈的热门区”。而那些有高订阅量,低文章数的作品集,则分布在图中的绿色区域。这才是你文章的“梦想之地”。
Tips:你会发现纵坐标和横坐标都取了对数。
这是因为有那么极个别的作品集有巨大的数字,而别的绝大多数的作品集的数字相较起来变得微乎其微,很难从图表中展现出来。
为了如实反应分布,同时还能够在图表中看到那些小众的作品集的情况,分析者对数字做了取对数(Log)的处理。
这种数据处理方法对于按照幂次定律分布的数据有较好的呈现效果。
2)更新
假设你已经找到了一些和你的文章内容相关,有足够的订阅者的作品集,现在你准备向其投稿了。
不过一旦你点击了“提交”,你的等待就开始了。在作品集的所有者批准或者拒绝你的提交之前,你没有任何办法追踪进展。
一个不好的消息是,你可能永远都得到不到回应!因为数据显示,这 1000 个作品集的平均最后更新时间,是 85 天之前!大约有 30% 的作品集一个月内没有任何更新,20% 在一年内没有任何更新。
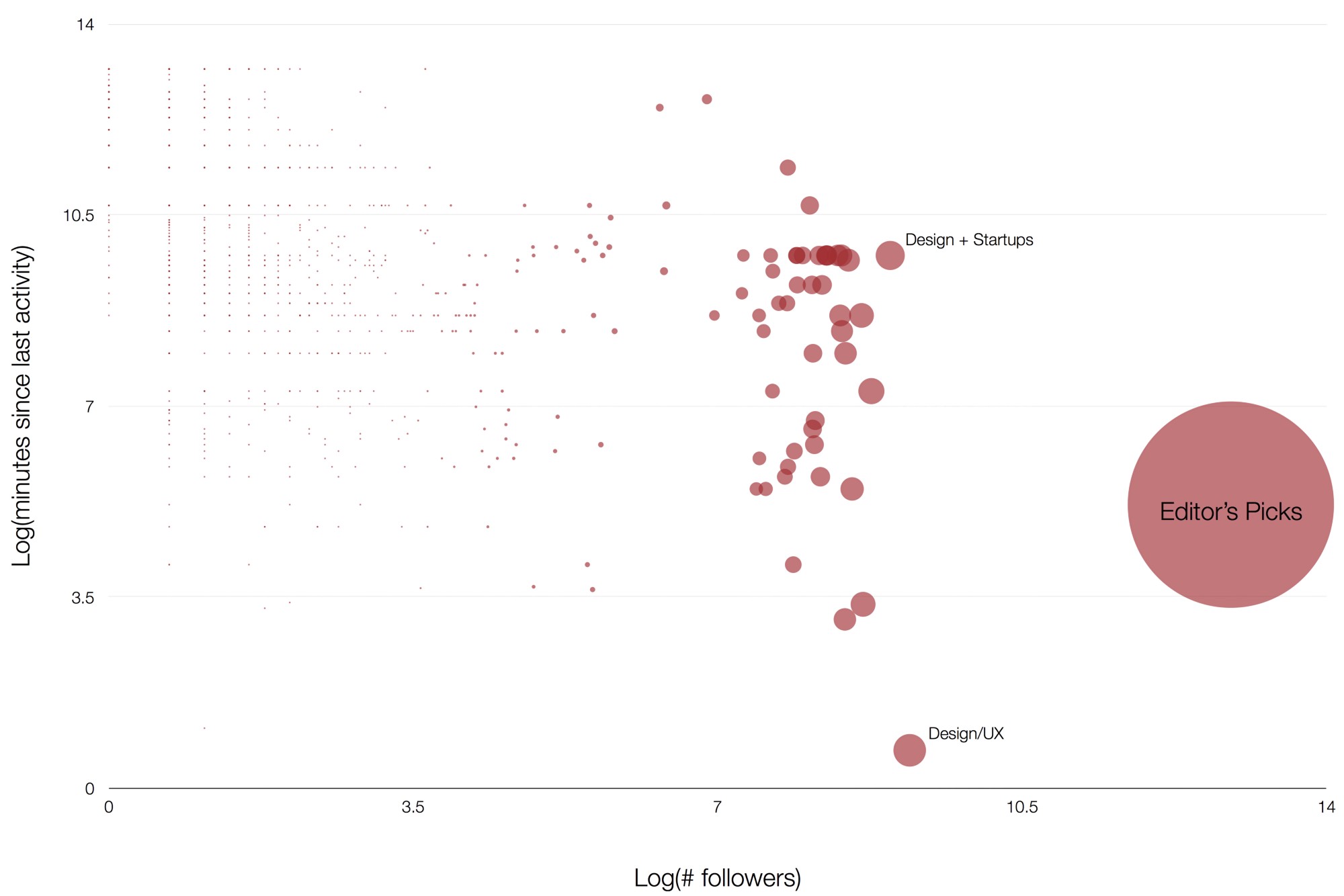
图2
上面的图中,显示了作品集的有多久没更新了,以及订阅数。而图中的圆的大小,则反映了该作品集包含的文章数量多少。大多数作品集的订阅量很少,更新也很少(图中左上角区域),少量的作品集订阅数很大更新也很频繁(图中右下角区域)。
你肯定已经发现了,你想投稿的作品集除了需要有高订阅量/低文章数量,还应该更新频繁。所以你的目光应该投向图中下放尽量靠左的位置。
学到了什么?
1)数据会说话。简单的加工分析,你就能收获启示。
2)任何数据的收集和分析有其背景和局限性,得到结论前,一定先了解背景。
3)掌握一些数据处理小技巧很有帮助,比如对幂次分布的数据取对数。