从本篇开始,本系列将进入实战演练阶段。
前面主要介绍了一些应用程序框架的概念和基类,本来想把所有概念介绍完,再把框架内部实现都讲完了,再进入实战,这样可以让初学者基础牢靠。不过我的精力很有限,文章进度越来越慢,所以准备切换一下介绍顺序,把实战演练提前,以方便你阅读代码。
本系列实战演练共分两个部分。
实战演练第一部分介绍如何快速解决CRUD机械操作,这一部分我将手把手带领各位同学从搭建VS环境开始,创建程序集及各程序集间的依赖关系,以及引入依赖的外部DLL,并手工完成代码示例中Application的三种界面操作。当你熟悉了手工操作方式后,你会发现这些工作枯燥乏味,效率低下,且容易出错。为解决该问题,我将为你介绍PowerDesigner(PD)和CodeSmith两大工具,分享PD及数据建模技巧,并发布配套的CodeSmith模板,你将体验到高质量完成机械代码的最佳实践。
实战演练第一部分介绍的内容很有用,它将帮助你完成大量体力活,但这个示例太简单,体现不出领域模型的威力,实战演练第二部分以权限模块为例,演示如何开发具有一定业务逻辑的模块。
当然,在介绍实战演练第二部分之前,我需要先把框架内部重要代码讲解完,本系列大致构成如下:
很多同学反映,阅读我的示例代码非常困难,经过了解,我发现大多是阅读方法有问题,在此给出一些建议。
对于别人的代码,你阅读起来很痛苦是正常现象,因为编程习惯和风格不同,另外一个原因是对代码的意图不了解。
我提供了Managements和Util两个VS解决方案,Managements是简单管理系统的代码示例,Util是框架代码,它是基础设施层的一部分,被分离出来的原因是让业务项目更简单、编译更快。
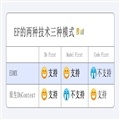
阅读代码需要从简单的东西入手,这里就是Managements解决方案,它里面包含了一个叫Application的CRUD操作,它是权限系统中的应用程序模块,具体功能先不要考虑。Application模块是一个单表操作,非常简单,几乎没有业务逻辑,很适合用来入门。EasyUi提供了三种数据录入方式,即表单操作、表格操作、行内操作,我使用Application模块演示了这几种操作方式。
有些同学下载代码后,直接看的Util代码,它主要包含一些基类和公共操作类,看起来困难就在所难免了。
为了减少程序集数量,我把一些第三方开源框架的代码直接放入Util解决方案中,有些同学直接就看到这里面去了,然后告诉我异常复杂。不要泄气,说明你是一个正常人,对于第三方开源框架的代码,我也害怕,嘿嘿。我的代码风格很容易辨认,就是每个方法都具有中文注释,当你发现代码没有注释或注释全是英文,那一定不是我写的,我的英文水平很菜。
当你把Application看熟以后,可以自己动手创建与Application类似的表,并手工完成三种CRUD操作。
当你对CRUD相关的类和配置熟悉之后,就可以查看基类实现,这时候带着问题去看Util代码,会容易理解得多。
下一步就是把这些代码逐步移植到你自己的项目中,只有把它们变成你的东西,才能发挥更大作用。这也是我写这个系列的目的,不仅授之以鱼,更要授之以渔。
建议你至少能够扩展之后,才把我的东西用到你的项目上,不然坑很多,风险高。
CRUD是Create、Retrieve(Read)、Update、Delete的缩写,中文名:增删改查。不论哪家的应用框架,都特别关照它几兄弟,为什么?
对于一般的中小型项目,业务逻辑复杂的模块只占很小的比例,一半以上的模块都比较简单。这些简单模块大致会通过一个界面或设备接口把数据收集上来,基本不经过中间处理(业务逻辑),直接存入数据库,在有需要的时候会把这些数据展示出来,或者为复杂模块提供基础支持。
这些简单模块工作量大,技术含量低,通过手工的方式编写效率低下。
当采用了分层架构,特别是DDD分层架构之后,更是雪上加霜。
对于采用了DDD这种复杂分层架构,哪怕业务逻辑很复杂,还是存在不少机械工作,主要是创建各层的构造类型,比如领域实体及属性、DTO及属性映射、EF映射等,这些工作是必须的,但很枯燥乏味。
可以看到,只要是信息系统,不论简单还是复杂,都存在机械工作,不同性质的项目机械工作所占比例不一样而已。
后面我将用CRUD来指代开发中碰到的一切机械工作。
对于机械工作,最好的办法是依靠生成器自动创建代码,在讨论生成器之前,先讨论下EF相关的概念。
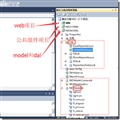
EF在刚出土的时候,提供一个叫实体数据模型的edmx文件,打开这个文件,发现它是一个可视化类图设计器。
在新建edmx文件时,有“从数据库生成”和“空模板”两个选项。
如果你选择“从数据库生成”,说明你自己先创建了数据库,再通过edmx的反向生成工具生成代码,这就是所谓的db first,first是先行或优先的意思,db first就是数据库先行,先创建数据库,再读取数据库的元数据,生成代码。
如果你选择了“空模板”,你可以在edmx可视化类图设计器中创建一些类和关联,edmx会自动帮你生成代码和数据库。这种方式称为model first,即模型先行,先有模型,后面再创建代码和数据库。
代码生成出来后,你会发现这些代码文件被包含在edmx文件中,包括领域实体和DbContext工作单元,还有一些T4模板,这有什么影响?
如果采用DDD分层架构,领域实体属于领域层,而DbContext属于基础设施层,放到一起会导致高耦合以及分层不清,这是edmx的主要问题。另外一堆不相干的代码生成模板与领域实体放到一起,估计也让你看着心烦。
EF后续推出了更加轻量的使用方式,让你可以抛弃edmx文件,直接使用原生的DbContext,并支持了code first开发模式。code first即代码先行,先写代码,再自动创建数据库。code first开发模式能够真正实现持久化无关,从而设计出更加纯净的领域模型,特别在采用TDD开发时,更加威猛。
从上面可以看出,edmx和原生DbContext是两种不同的EF技术,而db first、model first、code first则是不同的开发模式,但这些术语非常混乱,不同的人说同一个术语时可能指的是不同的东西。
经常听到有人说他用的是code first,但实际上他的开发方式是先创建数据库,再生成代码,这属于db first,他用code first指代原生DbContext技术。
还有一些人害怕使用EF,因为他认为原生DbContext只能使用code first开发模式,而他想采用db first方式,但他又不喜欢edmx。
我用原生DbContext这个词的意思是,单独使用DbContext这个基类,因为edmx也使用的是DbContext,以示区别。
下面用一个图来总结一下,如果说得不正确,请各位同学批评指正。

从上面分析得知,edmx不适合DDD分层架构,所以我们在EF技术上采用原生的DbContext,这个没有什么疑问了。那么开发模式是否一定要采用code first呢?
前面说了,code first可以获得更纯的领域模型,但你见过炉火纯青的领域模型长什么样吗?对于DDD架构初学者,在很长时间都难领悟到它的精髓,所以不论你以code first还是db first,其结果没有显著不同。
其次,.net大部分项目都是中小项目,且不太复杂,CRUD机械工作占很大篇幅,使用code first手工敲代码,效率十分低下,且工作量与表中的字段数量成正比。在配合TDD的情况下,才可以和生成的代码质量媲美,否则BUG依旧。
可以看到,虽然code first万众瞩目,但却只有DDD高手开发很复杂的业务才能真正发挥威力。很复杂的业务需求,可能逻辑非常复杂,仅简单搜集数据字段,并不能很好的完成任务,这种场景基于DDD进行行为建模并配合TDD推进项目更有保障。
根据我的项目实际情况,我采用了db first,第一步用PD数据建模,第二步用PD生成建库脚本创建数据库,第三步采用CodeSmith生成代码,第四步选择性的复制代码并建立领域模型。
很多同学一听代码生成器,就会问哪种生成器最好,还有些同学则干脆自己开发,毕竟大家都是程序员,要开发个生成器软件有何难。
技术人员总是对技术本身比较感兴趣,容易忽略做一件事的真正目的。其实对于代码生成器来说,真正重要的不是生成器软件,而是你需要获得的最终代码,它是由你的模板决定的。
要创建出一套高质量的模板,关键是不断提纯自己的代码,把重复的代码尽量提取到基类。
对于采用哪种生成器软件,根据自己的熟悉程度和喜好进行选择,我采用的是CodeSmith。
CodeSmith是一个收费的代码生成器,不过大家都使用绿色环保版本。使用它的原因是功能比较强大,能够与VS进行集成,编写模板时具有代码提示,类似ASPX语法,学习成本低,另外官方提供了一套EF DbContext模板,我们只需要简单修改,就可以用于实际开发中。
需要创建哪些部分的代码呢?在最理想的情况下,所有机械代码全部生成,这样你可以在最短时间内拿下大部分机械工作,为你能够集中火力完成核心功能奠定基础。
下面讨论几个与生成器相关的问题。
一般的代码生成器都是通过读取数据库元数据来生成代码。
如何评价生成的代码质量高低?
第一个特征,所有代码是否具有准确的注释。
大部分程序员都不喜欢写注释,不知道是因为打字慢,还是觉得没必要。哪怕你英文很牛X,你的命名非常标准,但你不能保证看你代码的人具有同样的英文水平。何况大部分人的英文还是和我一样菜,命名十分晦涩。在这种情况下,不要说给别人留条活路,那是给自己将来留的。
如果你采用code first模式,手工编写所有代码,相信能给全套代码写全注释的人不多,每个领域实体的属性头上都要加上注释,而且还有大量相似类,比如Dto,不复制代码很难做到。
第二个特征是自动帮你生成EF导航属性及相关映射配置,这是通过读取外键关系来创建的。
很多.Net程序员不知道数据建模的价值,如果你问我一个项目里,哪种文档最重要,我会毫不犹豫的告诉你——数据建模文档。
为什么数据建模这么重要,如果你现在接手一个遗留系统,你最需要什么?需求文档?类图?序列图?需求你不懂,还可以找用户问,但数据库中一个命名很晦涩的列,你要猜出它是什么意思,则难如登天。而类图和序列图等UML建模,主要是前期帮助理解和设计领域模型,不一定能够与代码同步更新,另外也不可能对每一个模块创建UML,完全没有必要。
通过PowerDesigner进行数据建模,你可以让系统清晰度上升几个层次,让你看清表之间的关系,以及每个列的具体含义。
你可以在数据建模时,把每个列的注释加上,用PD创建数据库后,生成的代码中就具有良好的注释了。
当你在表之间用关联线一拖,外键关系就建立了,生成的代码就具有了导航属性。
当然你可以直接在数据库中创建表,并添加注释,并手工创建外键关系。但这并没有让你减轻工作量,反而工作量更大,使用数据建模,工作轻松高效,且对项目未来维护有深远影响。
生成高质量代码,除了你的模板外,另一个影响它的就是数据建模。
我将在后面几篇分享我整理的CodeSmith模板,对于简单的CRUD操作,它可以生成全套代码,代码质量与我手工编写无异。
对于从三层架构过来的朋友,很多都用过代码生成器。
如果系统有100个表,他们会把这100个表先建好,然后一次生成出来,然后再花几小时到几天的时间来整理修改。
这个开发效率看上去很诱人,对于比较简单的三层架构和SQL操作可能是有效的,但对于EF+DDD分层架构却不太吃香。
对于EF的导航属性,生成出来都是双向导航,但为了降低复杂度,可能会手工调整为单向导航,这时候也需要手工修改映射代码。
EF操作,我总是保持小步前进,前进太快,出现任何一个问题,都可能浪费更多时间。很多时候看EF异常提示很难定位到问题,甚至断点调试也不起作用。这种情况下,最好的办法就是小步走,一出问题就可以迅速解决。
用代码生成器创建DDD分层架构,一个弊端是导致一个表对应一个聚合,每个表都有一个仓储,这把你又带回了三层架构时代。不过对于新手来说,这没有多大问题,每个人都有一个成长的过程,第一步把充血模型用起来就行了,下一步再考虑聚合。
但对于达到一定经验的人,直接用生成的代码就不合适了,因为聚合是DDD分层架构的核心,聚合使用得好,能显著降低系统复杂性,并使业务逻辑更好的内聚。
所以如果你具备一定经验以后,不应该完全采用代码生成的老方式,更不能偷懒。应该选择性的复制代码,手工组织聚合结构,这样一来,很多生成的代码都不需要了,比如某个仓储操作的是聚合内部实体,系统复杂性会大幅降低。
我的方法是,按依赖顺序手工复制需要的代码,按聚合粒度复制并组织代码,一次操作一个聚合,把界面运行通过后再复制下一个。
这样可以让你用db first模式开发出较高质量的领域模型,当然质量高低与水平成正比。
对于很简单的CRUD模块,大多都是单表结构,这种情况下,一个表本来就是一个聚合,代码直接COPY,你的主要工作是调整下界面。
对于比较复杂的模块,根据自己的理解手工复制代码组织聚合,生成的代码一般都达不到要求,比如界面布局比较复杂,这时候你会发现,生成的代码主要用于填充内容,你自己完成布局等功能。
更复杂的模块,可以先不生成代码,用TDD推进并模拟出业务逻辑后,再进行数据建模生成代码,并复制需要的文件。
对于强大一点的生成器,都能够嵌入VS,并一键生成。这个特性也很诱人,如果把生成器嵌入生产项目,就不需要COPY文件了,这看起来能够极大的提升开发效率。
与上一个问题一样,当你把生成器嵌入生产项目,生成的所有文件都进入你的项目,不论你需不需要它,这导致每个表一个仓储,增加了复杂性。
我的方法是,把代码生成器与生产项目分离,手工复制相关文件,虽然看上去效率低,但可以根据需要选择代码和重新组织代码,质量将高得多。
采用代码生成器的一个问题是,每当数据库增加一个字段,代码上相关的位置都要同步更新,很多懒汉希望通过重新生成并全面覆盖来解决这个问题。
我的方法是仅在第一次生成全套代码,后面通过手工添加相关属性,如果增加的字段比较多,我可能先生成代码,再手工将差异属性复制过去。原因很简单,项目上的代码不是完全生成的,有修改过的地方,重新生成并完全替换,可能会覆盖已修改代码。
很多人在生成器下了大量功夫,能够支持复杂的配置,以生成出非常智能的代码。
这可能造成对代码生成器的高度依赖,我仅使用代码生成器解决机械的简单工作,对于更智能的手工完成。
我的方法是一键生成简单代码。
有人看见生成的代码中,很多类都直接从基类派生,里面完全是空的,是否可以简化掉。
这些类中啥也没有的原因是,基础操作已抽象到基类,由于没有什么业务逻辑,所以是空的。
一般来说不能简化,因为对于稍复杂的模块,都需要往这些类中添加内容,如果没有它们你的代码将变得混乱,这些构造很好的组织了代码。
除非你能确定你的项目基本都是CRUD,这种情况下确实可以简化,而且最好的办法是采用单层架构,单层架构在高度抽象和采用代码生成器的情况下,开发效率犹如火箭直冲宵汉。
这两天园子里讨论加班的很多,我也说几句。
不加班有几个条件:
第一点最困难,哪怕你们开发人员水平再高,框架也很强大,如果老板要求你2个月完成8个月的工作,你不加班是不可能的。
如果计划合理,框架很强大,你一天用半天时间来开发,半天时间休息都绰绰有余。
本文分享了我在EF和代码生成器上的一些看法,不见得正确,那只是我摸索的一些经验,你应该找出最合适你们团队和项目的方法,并持续改进。
.Net应用程序框架交流QQ群: 386092459,欢迎有兴趣的朋友加入讨论。
.Net Easyui开发交流QQ群(本群仅限Easyui开发者,非Easyui开发者勿进):157809322
谢谢大家的持续关注,我的博客地址:http://www.cnblogs.com/xiadao521/