最近公司搞了一个写程序的比赛,要求从2G的文件里统计出出现频率最高的10个单词。
最开始的想法是使用字典树,后来发现字典树更适合用在找前缀上,在查找没有hash表效率高。
之后使用Hash表+DataFlow完成了功能,2G的文件处理在20秒以内(其实我有信心优化到10秒以内,但是太折腾了)。
这是我的设计图:
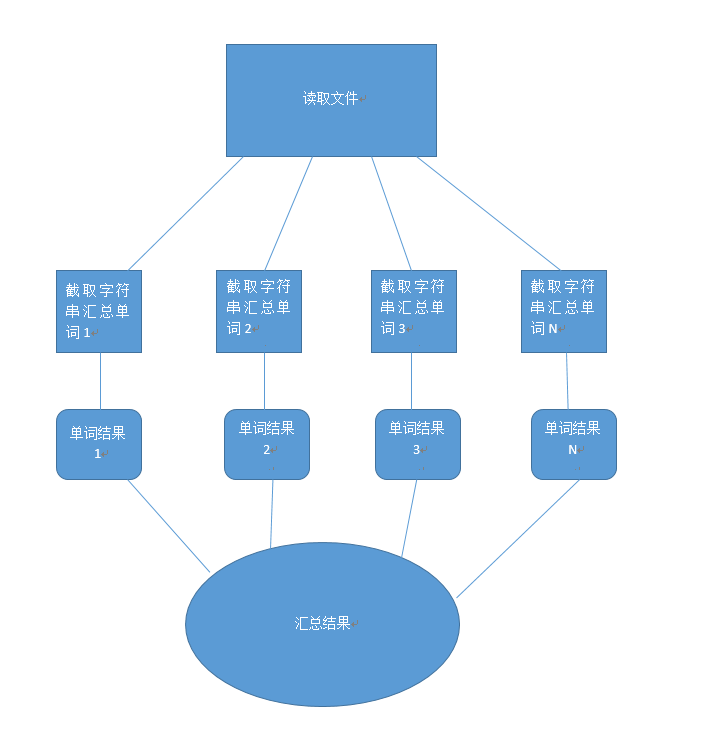
为什么要形成那么多结果?因为我不想写锁,写锁会降低很多效率,而且也失去了线程的意义,每个线程做自己的工作,
最后在把每个线程处理的结果汇总起来,这样也符合fork join 的设计。
而且我也试过,如果写锁的话,效率会降低10秒以上,我也尝试过微软提供的ConcurrentDictionary 原子哈希表,但是效果都不是
很理想,而且,在并行的年代,在写锁这个东西,感觉很恶心,好像在代码里加了一坨屎一样,我以前就很讨厌锁,也出现过代码死锁的情况。
最后我选择了使用微软的TPL 库来解决并行的问题。
使用DataFlow解决了我处理时多线程管理的问题,还有线程等待消息队列的问题,
使用BufferBlock 进行主控与工作线程之间消息传递,这是我的设计图:
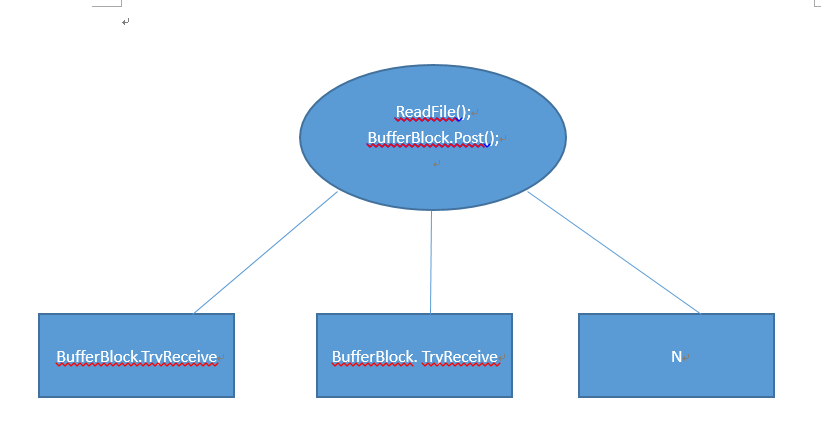
读取文件之后使用BufferBlock.Post发送给工作线程,工作线程使用TryReceive接收消息,并且处理。
在MSDNhttps://msdn.microsoft.com/zh-cn/library/hh228601(v=vs.110).aspx 里有详细的介绍。
这是典型的单生产者,多使用者的列子。
代码方面首先是读取文件:
public class FileBufferBlock { private string _fileName; BufferBlock<WordStream> _buffer = null; public FileBufferBlock(BufferBlock<WordStream> buffer,string fileName) { this._fileName = fileName; this._buffer = buffer; } /// <summary> /// 按32M读取文件,循环发送给WordBufferBlock /// </summary> public void ReadFile() { using (FileStream fs = new FileStream(_fileName, FileMode.Open, FileAccess.Read)) { using (StreamReader sr = new StreamReader(fs)) { while (!sr.EndOfStream) { char[] charBuffer = new char[32 * 1024 * 1024]; sr.ReadBlock(charBuffer, 0, charBuffer.Length); _buffer.Post(new WordStream(charBuffer)); } } } _buffer.Complete(); }
在这里使用BufferBlock.Post 发送消息给工作线程,如果不用它,你得去找个能阻塞的消息队列。
下面是我的接收方的代码,使用BufferBlock.TryReceive 接收消息,然后处理,在这里可以开多个个线程去处理。
而且线程是它帮你管理的:
// -------------------------------------------------------------------------------------------------------------------- // <copyright file="WordProcessBufferBlock.cs" company="yada"> // Copyright (c) yada Corporation. All rights reserved. // </copyright> // change by qugang 2015.4.18 // 描述:用于截取单词的工作线程 // -------------------------------------------------------------------------------------------------------------------- using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Threading.Tasks.Dataflow; namespace WordStatistics { public class WordProcessBufferBlock { private int _taskCount = 1; BufferBlock<WordStream> _buffer = null; private List<Task<Dictionary<string, int>>> _list = new List<Task<Dictionary<string, int>>>(); /// <summary> /// 单词处理类 /// </summary> /// <param name="taskCount">工作线程数</param> /// <param name="buffer">DataFlow的BufferBlock</param> public WordProcessBufferBlock(int taskCount, BufferBlock<WordStream> buffer) { _taskCount = taskCount; this._buffer = buffer; } public void StartWord() { for (int i = 0; i < _taskCount; i++) { _list.Add(Process()); } } /// <summary> /// 等待所有工作完成 /// </summary> /// <param name="f">完成后的工作函数</param> public void WaitAll(Action<Dictionary<string,int>> f) { Task.WaitAll(_list.ToArray()); foreach (var row in _list) { f(row.Result); } } /// <summary> /// 使用BufferBlock.TryReceive循环从消息里取从FileBufferBlock发送的buffer /// </summary> /// <returns>工作结果</returns> private async Task<Dictionary<string, int>> Process() { Dictionary<string, int> dic = new Dictionary<string, int>(); while (await _buffer.OutputAvailableAsync()) { WordStream ws; while (_buffer.TryReceive(out ws)) { foreach (string value in ws) { if (dic.ContainsKey(value)) { dic[value]++; } else { dic.Add(value, 1); } } } } return dic; } } }
WordStrem是我自己写的一个单词枚举流,继承了IEnumerable接口,将找单词的算法写到枚举器里面,实现流化。
// -------------------------------------------------------------------------------------------------------------------- // <copyright file="WordStatistics.cs" company="yada"> // Copyright (c) yada Corporation. All rights reserved. // </copyright> // change by qugang 2015.4.18 // 单词枚举器:算法从开始找字母,如果不是字母,则返回从pos 到end 的组成单词 // -------------------------------------------------------------------------------------------------------------------- using System; using System.Collections; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace WordStatistics { /// <summary> /// 单词枚举器 /// </summary> public class WordStream : IEnumerable { private char[] buffer; public WordStream(char[] buffer) { this.buffer = buffer; } IEnumerator IEnumerable.GetEnumerator() { return (IEnumerator)GetEnumerator(); } public WordStreamEnum GetEnumerator() { return new WordStreamEnum(this.buffer); } } public class WordStreamEnum : IEnumerator { private char[] buffer; int pos = 0; int endCount = 0; int index = -1; public WordStreamEnum(char[] buffer) { this.buffer = buffer; } public bool MoveNext() { while (index < buffer.Length - 1) { index++; char buff = buffer[index]; if ((buff >= 'a' && buff <= 'z') || (buff >= 'A' && buff <= 'Z')) { if (endCount == 0) { pos = index; endCount++; } else { endCount++; } } else { if (endCount != 0) return true; } if (buff == '\0') { return false; } } return false; } public object Current { get { int tempInt = endCount; endCount = 0; return new string(buffer, pos, tempInt); } } public void Reset() { index = -1; } } }
到这里就完成了,然后再Main函数里添加调用
static void Main(string[] args) { DateTime dt = DateTime.Now; var buffer = new BufferBlock<WordStream>(); //创建工作BufferBlock WordProcessBufferBlock wb = new WordProcessBufferBlock(8, buffer); wb.StartWord(); //创建读取文件,发送的BufferBlock FileBufferBlock fb = new FileBufferBlock(buffer, @"D:\content.txt"); fb.ReadFile(); Dictionary<string,int> dic = new Dictionary<string,int>(); //等待工作完成汇总结果 wb.WaitAll(p => { foreach (var row in p) { if (!dic.ContainsKey(row.Key)) dic.Add(row.Key, row.Value); else { dic[row.Key] += row.Value; } } } ); var myList = dic.ToList(); myList.Sort((p, v) => v.Value.CompareTo(p.Value)); foreach (var row in myList.Take(10)) { Console.WriteLine(row); } Console.WriteLine(DateTime.Now - dt); }
最后2G的文件,我的机器跑出来是19秒多。
如果代码没有包,请从NuGet上下载Dataflow包。
代码下载:http://files.cnblogs.com/files/qugangf/WordStatistics.rar