class="T-ParCxSpFirst" style="text-indent: 21.0pt;">在开发数据库应用时,经常会遇到分组后针对组内数据的运算问题,如:列出近3年每年都发表过论文的学生名单,统计全部参加了历次培训的员工,选出每位客户的高尔夫成绩最高的三天等等。SQL完成这类运算较为复杂,一般需要嵌套多层,导致代码难以理解和维护。而集算器擅长表达这类组内计算,且很容易和JAVA或报表工具集成。下面用一个例子来说明。
?
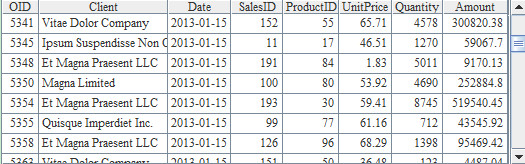
根据数据库表SaleData统计出2013年中,每个月销售金额均排在前20名的客户名称。SalesData的部分数据如下:
?
想解决这个问题,需要选出2013年的销售数据,然后再按月分组统计,再循环选出每月销售前20名的客户,最后求各组的交集。
用集算器,可以将复杂问题拆分,逐步计算出最终结果。首先,从销售数据中取出2013年的数据,并按月份分组:
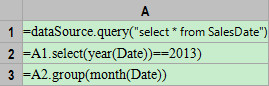
?
注:A2中的过滤也可以用SQL来完成。
?
用集算器对数据分组,是真实的分组,会将数据按照需要分为多个组。这和在SQL中的情况是不同的,SQL中的group by命令将直接计算出分组的汇总值,而不能保留分组的中间结果。分组后,A3中的数据如下:
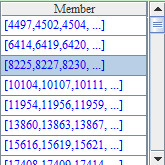
?
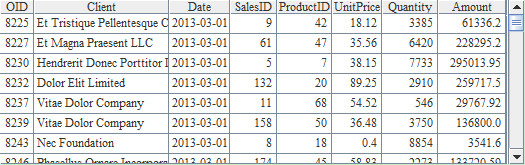
在分组前,会自动完成排序,每个分组都是销售记录的集合,如其中3月的数据如下:
?
?
为了统计每个月中,每个客户的月销售总额,需要再按客户分组。在集算器中,只需要循环每个月的数据,分别按客户分组就可以了。循环组内成员时,可以用A.(x)来执行,而不必再去编写循环代码。
A4:=A3.(~group(Client))
?
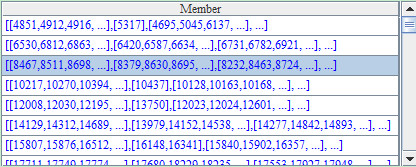
再次分组后,A4中,每个月的数据都是分组的分组:
?
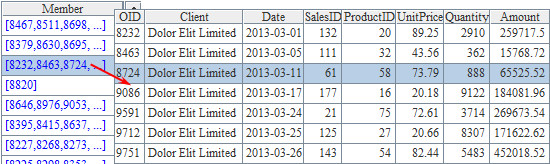
此时,3月的数据如下:
?
可以看到,3月数据中的每个分组,都是某个客户的交易数据。
注意上述代码中的“~”表示分组中的每个成员,针对“~”书写的代码就是组内运算代码,比如上面的~.group(Client)。
接下里,继续通过组内运算求出每月排名前20的大客户:
A5:=A4.(~.top(-sum(Amount);20))
A6:=A5.(~.new(Client,sum(Amount):MonthAmount))
?
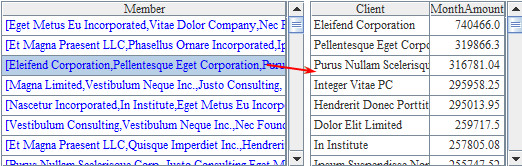
在A5中,循环每个月的数据,计算出了每月销售额最大的前20个客户,并在A6中列出了这些客户的名称及月销售额。A6中计算的结果如下:
?
最后列出分组内的Client字段,并对各分组求交集:
A7:=A6.(~.(Client))
A8:=A7.isect()
?
在A7中求出每月销售额最大的20个客户名称。最后在A8中求12个月的客户名称交集,结果如下:

?
从这个问题中可以看到,集算器可以轻松实现结构化数据的组内计算,可以使得解决问题时的思路更为直观;在组内也能够轻松地完成再分组、排序等计算,使得每一步的数据处理更加清晰自然。此外,集算器能使组成员的循环或者求交集等运算变得更为简易,大大减少代码量。
?
集算器被java程序调用的方法也和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。