遥想当年大一上java课时,听老师说过,要想深入了解java可以先从自己重写一个HashMap开始。说来惭愧,我现在才开始做这件事。不过,迟做总比不做好。
?
在研究hashmap之前,有必要说一下map。map,中文译为映射表,关联数组,其基本思想是键值对的关联,你可以通过键来查找值。在java类库中,map是一个接口,有多种实现,其不同体现在效率、键值对的保存和呈现次序、判定"key"的等价的策略等方面。下面实现一个简单的map(用二维数组实现):
class="java" name="code">package cn.lzj_2015_0406_hashmap;
/**
* @author lzj lzj.997@qq.com:
* @version 创建时间:2015-4-11 下午9:25:27 类说明:map映射表的简单实现
*/
public class SimpleMap<K, V> {
private int index;// 下标
private Object[][] pairs;//存放键值对的对象二维数组
/**
* 构造方法
*
* @param length
* 新建映射表时指定该映射表的长度
*/
public SimpleMap(int length) {
// 创建对象二维数组,用于存储映射表键值对
this.pairs = new Object[length][2];
}
public void put(K key, V value) {
if (index >= pairs.length)
throw new ArrayIndexOutOfBoundsException();// 抛出数组越界异常
// 放入键值对
pairs[index++] = new Object[] { key, value };
}
public V get(K key) {
// for循环遍历二维数组,寻找key对应的值
for (int i = 0; i < index; i++) {
if (key.equals(pairs[i][0])) {
return (V) pairs[i][0];
}
}
return null;// 没找到时返回null
}
// 覆盖toString为更好的显示效果
public String toString() {
StringBuilder result = new StringBuilder();
for (int i = 0; i < index; i++) {
result.append(pairs[i][0].toString());
result.append(":");
result.append(pairs[i][1].toString());
if(i<index-1)
result.append("\n");
}
return result.toString();
}
public static void main(String[] args) {
SimpleMap map = new SimpleMap<String,String>(5);
map.put("cloud", "white");
map.put("sun", "hot");
map.put("sky", "white");
map.put("grass", "white");
map.put("bird", "white");
System.out.println(map);
System.out.println(map.get("cloud"));
}
}
?在以上的代码中,可以清晰的看到,映射表的get方法是其最大的瓶颈,定位值的方法时间复杂度为O(n),从数组头部开始使用equals方法依次比较键,是效率最差的,随着操作数据的数量的增加,所花费的时间将大大增加。另外由于使用数组存放作为存放键值对的容器,具有固定的尺寸,使得在实际的运用中非常不灵活。
?
为提高查询速度,HashMap使用了散列码,通过散列码对值的反射取代了对键的缓慢搜索。散列码是相对唯一的、用于代表对象的值,散列函数基于对象的某些信息而产生。HashMap使用对象的hashCode()方法产生散列码进行快速查询。在任何时候,对同一个对象所产生的hashcode都必须是同样的值,否则所产生的hashcode是非常糟糕的,因为它将无法获取到相应的对象。
总之,要想使得hashcode()实用,它必须基于对象的内容产生hashcode,它不必是独一无二的,但是通过equals()和hashcode(),必须能够完全确认对象的身份,即同一对象必须具有相同的hashcode。
java中Object的hashcode方法默认使用对象的地址计算hashcode,Object默认的equals比较的是对象的地址(在未被重载的情况下),因此在使用自己的类作为hashmap的键时,必须同时重载hashCode()方法和equals()方法。
关于hashcode如果深入展开还有很多需要分析,期待在下一篇中进行探讨。
?
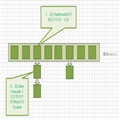
hashmap的结构--以挂链法为例。如图所示:
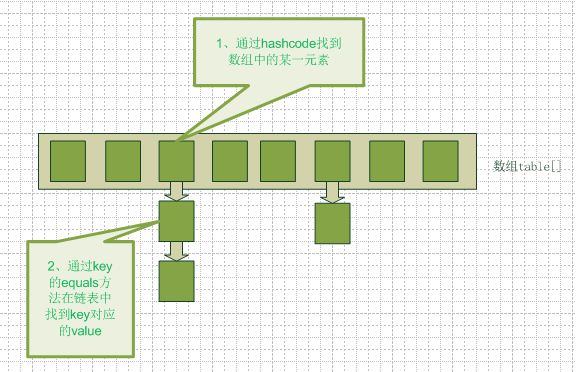
?可以看到,该hashmap是一个数组和链表的结合体。
hashmap所实现的散列化是对于线性查找而言巨大的改进,通过hashcode把数据分散到数组的各个位置,减少了equals方法的调用次数,从而提高程序的效率。
在此过程中,有几个关键点:
实现的hashmap
package cn.lzj_2015_0406_hashmap;
/**
* @author lzj lzj.997@qq.com:
* @version 创建时间:2015-4-6 上午12:40:54 类说明
*/
public class MyHashMap<K, V> {
private int size;// 当前项目数
private static final int INI_CAPACITY = 32;// 默认bucket容量
private static float RATE = 0.75f;// 负载因子
private int maxNum;// 最大项目数=capacity*rate
private Entry<K, V>[] buckets;// 存储值的链表数组
// 自定义构造方法
public MyHashMap(int capacity, float rate) {
if (capacity < 0) {
throw new IllegalArgumentException("illegal capacity=" + capacity);
}
if (rate <= 0) {
throw new IllegalArgumentException("illegal rate=" + rate);
}
this.RATE = rate;
maxNum = (int) (capacity * rate);
buckets = new Entry[capacity];
}
// 默认构造方法
public MyHashMap() {
this(INI_CAPACITY, RATE);
}
// 存
public boolean put(K key, V value) {
// 1.得到key所对应的数组下标
int index = indexOf(key,buckets.length);
// System.out.println("index of put ="+index);
// 2.要存入的链表
Entry<K, V> temp = new Entry<K, V>(key, value, key.hashCode());
// 3.得到在相同下标位置的链表
Entry<K, V> entry = buckets[index];
// 4.若不存在链表,新建一个
if (entry == null) {
// System.out.println("entry");
setFirstEntry(temp, index, buckets);
size++;
return true;
}
// 4.若存在,遍历链表:同,返回;不同,补尾
while (entry != null) {
if (entry.key.equals(temp.key) && (entry.hash == temp.hash)
&& (entry.value.equals(temp.value))) {
return false;
}
if (entry.key.equals(temp.key) && (entry.hash == temp.hash)
&& !(entry.value.equals(temp.value))) {
entry.value = temp.value;// 以 新值替代旧值
return true;
} else {
if (entry.next == null) {
break;
}
}
entry = entry.next;
}
// 当遍历到队尾,也没有找到元素,添加到链表尾部
entry.next = temp;
size++;
return true;
}
// 取
public V get(K key) {
// 1.得到key所对应的数组下标
int index = indexOf(key,buckets.length);
// System.out.println("index="+index+buckets[index]);
// 2.由下标找到链表
Entry<K, V> entry = buckets[index];
// 3.若链表为空,返回null
if (entry == null){
// System.out.println("is null");
return null;}
// 3.若链表不为空,遍历链表,比较key(若key为object,则有必要重载equals方法)
while (null!=entry) {
if (entry.key == key || entry.key.equals(key)) {
System.out.println("entry.value="+entry.value);
return entry.value;
}
entry = entry.next;
}
// 若没找到,返回null
return null;
}
// 扩大数组
public void upCapacity(int newCapacity) {
// 1.创建新数组
Entry<K, V>[] newBuckets = new Entry[newCapacity];
maxNum = (int) (newCapacity * RATE);
// 2.复制已有元素
for (int j = 0; j < buckets.length; j++) {
Entry<K, V> entry = buckets[j];
while (null != entry) {
setFirstEntry(entry, j, newBuckets);
entry = entry.next;
}
}
// 3.改变指向
buckets = newBuckets;
}
// 设置链表第一个元素的方法
public void setFirstEntry(Entry<K, V> temp, int index, Entry[] table) {
// 1.判断当前容量是否超标,如果超标,调用扩容方法
if (size > maxNum) {
upCapacity(buckets.length * 2);
}
// 2.不超标,或者扩容以后,设置元素
buckets[index] = temp;
// System.out.println("tmp"+buckets[index].value );
// temp.next=null;
}
// 得到数组的下标值
public int indexOf(K key,int capacity) {
return Math.abs(key.hashCode()) & (capacity - 1);
}
// 匿名内部类,用于保存数据,设计为链表形式来解决冲突
class Entry<K, V> {
Entry<K, V> next;// 下一节点
K key;
V value;
int hash;
Entry(K k, V v, int hash) {
this.key = k;
this.value = v;
this.hash = hash;
}
}
public static void main(String[] args) {
MyHashMap<String, String> myhash = new MyHashMap<String, String>();
long start = System.currentTimeMillis();
for (int i = 0; i < 2000000; i++) {
myhash.put("cloud" + i, "white" + i * 100);
}
long end = System.currentTimeMillis();
System.out.println("put 2000000 timeCost=" + (end - start) + "ms");
long start1 = System.currentTimeMillis();
// System.out.println(myhash.get("cloud" + 28));
myhash.get("cloud" + 10000);
long end1 = System.currentTimeMillis();
System.out.println("get from 2000000 timeCost=" + (end1 - start1) +
"ms");
}
}
?
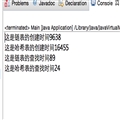
花费的时间:
put 2000000 timeCost=2546ms
get from 2000000 timeCost=0ms
?
?
?
?
?
?
?