这阵子在重温数据结构的时候,顺便用ILSpy看了一些.NET类库的实现,发现一些基本的数据结构的实现方法也是挺有意思的,所以这里拿出来跟大家分享一下。这篇文章讨论的是Stack和Queue的泛型实现。
Stack(栈)是一种后进先出的数据结构,其中最核心的两个方法分别为Push(入栈)和Pop(出栈)两个操作,那么.NET类库是如何实现这种数据结构呢?为了降低学习成本,这里将根据.NET源码的实现,结合其中的核心设计思想,得出一个简化版本的实现:
using System; namespace OriginalCode { /// <summary> /// 基于.NET源码的简化版实现 /// </summary> public class Stack<T> { private const int _defaultCapacity = 4; private T[] _array; private int _size; public Stack() { //默认初始化数组的数量为空 _array = new T[0]; //初始化数组的数量为0 _size = 0; } /// <summary> /// 入栈 /// </summary> /// <param name="item">入栈的元素</param> public void Push(T item) { if (_size == _array.Length) { //数组存储已经满了,需重新分配数组大小 //分配的数组大小为原来的两倍 T[] array = new T[_array.Length == 0 ? _defaultCapacity : 2 * _array.Length]; //将原来的数组Copy到新数组中 Copy(_array, array); //_array指向新数组 _array = array; } _array[_size] = item; _size += 1; } /// <summary> /// 出栈 /// </summary> /// <returns>出栈的元素</returns> public T Pop() { if (_size == 0) { throw new Exception("栈为空,当前不能执行出栈操作"); } _size -= 1; T result = _array[_size]; _array[_size] = default(T); return result; } /// <summary> /// 将旧数组赋值到新数组(这个方法是一个模拟实现,实际情况.NET源码底层用C++实现了更高效的复制) /// </summary> /// <param name="oldArray">旧数组</param> /// <param name="newArray">新数组</param> private void Copy(T[] oldArray, T[] newArray) { for (int i = 0; i < oldArray.Length; i++) { newArray[i] = oldArray[i]; } } } }简化版Stack的实现
必须明确的一点是Stack<T>的底层是靠T[] _array数组对象维系着。首先来看构造函数Stack(),这里做的事情无非就是一些基本的初始化工作,当调用这个无参构造函数的时候,会将_array数组实例化为T[0],同时将一个_size初始化为0。这个_size主要是用来表示当前栈中存在的元素个数,同时也承担起类似数组下标的作用,标识下一个元素入栈的数组位置。
接下来来看一下Push(T item)函数的实现。这里的第一步操作其实就是执行一次判断,判断当前_array数组的元素个数是否已经满了,假如满了的话,就要对数组进行扩充。.NET源码对于数组扩充的设计还是比较巧妙的,当_array为空的时候,默认开始分配的数组个数为4,既new T[4],假如要插入的是第5个元素的时候,这时数组的个数不足,就声明一个新的T[] array,并将个数扩充为_array个数的2倍,之后再将_array元素一个个复制到新的array中,最后将_array字段指向array,就完成了数组扩充的工作。这一步在前面的代码中的实现应该是很清晰的,不过需要注意的一点是这里的Copy(_array,array)函数是我自己的一个简单的实现,跟.NET源码中的实现是很不一样的,.NET源码是调用一个Array.Copy(this._array, 0, array, 0, this._size)的函数,它的底层应该是用C++实现了数组复制的更好的优化。通过一张图来看一下数组扩容的过程:

最后来看一下Pop()函数的实现。首先先判断当前数组的个数是否大于0,小于等于0的话就会抛出异常。之后就将_size-=1,得到要Pop的对象在数组的位置。取出_array[_size]后,就调用default(T)填充_array[_size]的位置,这样做的一个好处是取消对原来的对象的引用,是其能够成为垃圾回收的对象,更好地减少内存的占用。总体而言Pop()实现还是比较简单的。
从前面我们知道,使用Stack<T>数据结构,数组扩容应该是影响性能最大的一个因素。默认情况下,假如要往栈中插入100个对象,意味着数组就要经过4->8->16->32->64->128总共5次的数组扩容,那么有没有什么办法可以改善性能呢?答案是有的,.NET源码Stack<T>对象除了提供默认的无参构造函数外,还提供了一个Stack(int capacity)的构造函数,capacity参数其实就是用表示来初始化数组的个数,假如我们能预料到这次插入栈的对象个数的最大值的话(以100为例),就直接这样调用new Stack<T>(100),这样就能减少不必要的数组扩容,从而提高了Stack的使用性能。
Queue(队列)是一种先进先出的数据结构,其中最核心的两个方法是Enqueue(入队)和Dequeue(出队)两个操作。通过前面的热身,我们已经对Stack<T>的实现比较理解了,其实Queue<T>的实现也有相似的地方,例如底层的数据结构同样是靠T[] _array数组对象维系着,也是使用了2倍数组扩容的方式。不过,由于队列具有先进先出的特性,它决定了不能像Stack<T>那样只用一个_size来维系栈尾的下标,队列必须有一个队头_head下标和一个队尾_tail下标来保证先进先出的特性。考虑到队列的存储效率,还必须涉及到循环队列的问题,所以Queue<T>的实现会比Stack<T>更为复杂一些,同样来看一个简化版本的实现:

using System; namespace OriginalCode { /// <summary> /// 基于.NET源码的简化版实现 /// </summary> public class Queue<T> { private static T[] EMPTY_ARRAY = new T[0]; private const int _defaultCapacity = 4; private T[] _array; private int _head; //头位置 private int _tail; //尾位置 private int _size; //队列元素个数 public Queue() { _array = EMPTY_ARRAY; _head = 0; _tail = 0; _size = 0; } public Queue(int capacity) { _array = new T[capacity]; _head = 0; _tail = 0; _size = 0; } /// <summary> /// 入队操作 /// </summary> /// <param name="item">待入队元素</param> public void Enqueue(T item) { if (_size == _array.Length) { //确定扩充的容量大小 int capacity = _array.Length * 2; if (capacity < _array.Length + _defaultCapacity) { //.NET源码这样实现的一些基本猜想 //由于可以通过调用Queue(int capacity)实例化队列 capacity可以=1 | 2 | 3 //这里做与+4做判断 应该是为了提高基本性能 比如当capacity = 1的时候 *2 = 2 这样2很快容易有下一次扩充 //不过其实感觉效果并不大 有点设计过度的嫌疑 capacity = _array.Length + _defaultCapacity; } //实例化一个容量更大的数组 T[] array = new T[capacity]; if (_size > 0) { //当需要重新分配数组内存的时候 根据循环队列的特性 这时的_head一定等于_tail //从旧数组_array[_head]到_array[_size-1] 复制到 新数组array[0]...[_size - _head - 1] ArrayCopy(_array, array, 0, _head, _size - _head); //从旧数组_array[0]到_array[_head-1] 复制到 新数组array[_size - _head]...[_size - 1] ArrayCopy(_array, array, _size - _head, 0, _head); } _array = array; //将旧数组指向新数组 _head = 0; //重新将头位置定格为0 _tail = _size; //重新将尾位置定格为_size } _array[_tail] = item; _tail = (_tail + 1) % _array.Length; _size += 1; } /// <summary> /// 出队操作 /// </summary> /// <returns>出队元素</returns> public T Dequeue() { if (_size == 0) { throw new Exception("当前队列为空 不能执行出队操作"); } T result = _array[_head]; _array[_head] = default(T); _head = (_head + 1) % _array.Length; _size -= 1; return result; } /// <summary> /// 将旧数组的项复制到新数组(这个方法是一个模拟实现,实际情况.NET源码底层用C++实现了更高效的复制) /// </summary> /// <param name="oldArray">旧数组</param> /// <param name="newArray">新数组</param> /// <param name="newArrayBeginIndex">新数组开始项下标</param> /// <param name="oldArrayBeginIndex">旧数组开始项下标</param> /// <param name="copyCount">复制个数</param> private void ArrayCopy(T[] oldArray, T[] newArray, int newArrayBeginIndex, int oldArrayBeginIndex, int copyCount) { for (int i = oldArrayBeginIndex, j = newArrayBeginIndex; i < oldArrayBeginIndex + copyCount; i++,j++) { newArray[j] = oldArray[i]; } } } }简化版Queue的实现
首先通过下面的图来看一下数组容量足够的时候,循环队列的执行过程:
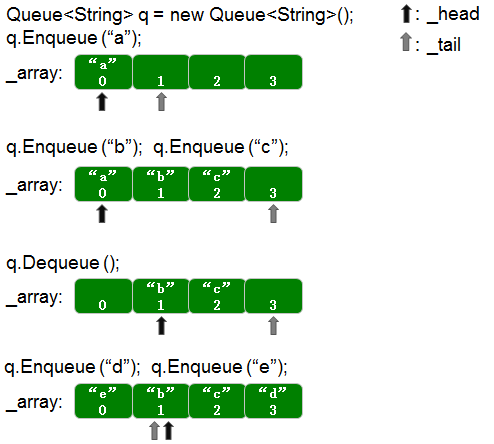
基于上面这张图的执行过程,来看一下Dequeue函数的实现。第一步判断的是_size是否为0,是的话就抛出异常。如果当前入队个数大于0,则获取_array[_head]元素作为出队元素,之后就调用default(T)填充_array[_head]的位置。由于是一个循环队列的设计,所以不能简单地将_head+=1,而必须这样_head=(_head+1)%_array.Length,如上图所示,_head有可能指向下标为3的位置,假如这时直接_head += 1变为4的话,就跳出了数组的小标范围,而_head=(_head+1)%_array.Length变为0,则指向了数组最前的位置,实现了循环队列的功能,更好地利用了内存。
接下来看一下Enqueue(T item)函数的实现。承接上图的Queue的状态,假如现在要执行q.Enqueue("f")的入队操作,但是很明显数组_array已经满了,那么要怎么办呢?其实原理和Stack的实现类似,也是要通过数组扩容的方式,不过比Stack的数组复制要复杂一些。来继续看图:
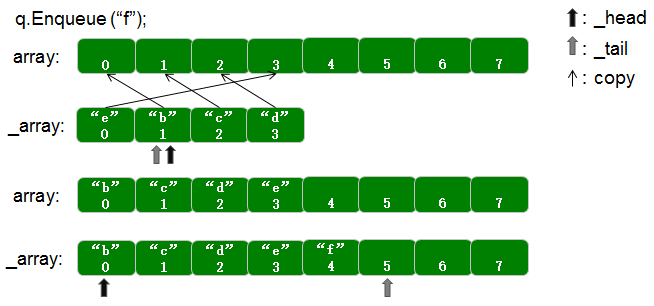
与Stack<T>一样,影响Queue<T>性能最大因素是数组扩容以及相应的数组复制操作,同样Queue也提供了一个带初始化容量的构造函数Queue(int capacity),如果我们能估算到队列可能同时存在元素的最大值,就尽量调用这个带capacity的构造函数。