OS:这里对聚集所以和非聚集所以的概念说明就不叙述了。 身为程序猿,在平时的开发中,数据的操作是经常要做的事情,大多数公司是没有DBA的,所以程序开发人员的在操作数据的时候根本不会去看SQL语句执行的效率,所以就时常的发现大数据的情况下查询数据库总会遇到各种缓慢Loading的情况。 从用户的角度来说,我裤子都脱了,你给我看这个?
CREATE TABLE [dbo].[Student]( [ID] [INT] IDENTITY(1,1) NOT NULL, [Name] [NVARCHAR](50) NOT NULL, [Age] [INT] NOT NULL, [Height] [INT] NOT NULL, [Address] [NVARCHAR](100) NULL, [Class] [NVARCHAR](50) NOT NULL, [EntranceDateTime] [DATETIME] NOT NULL, CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
ALTER TABLE [dbo].[Student] ADD CONSTRAINT [DF_Student_EntranceDateTime] DEFAULT (GETDATE()) FOR [EntranceDateTime] GO
往表里插入 500万数据:
DECLARE @i INT; SET @i=1; WHILE(@i<5000001)BEGIN INSERT INTO dbo.Student(Name,Age,Height,[Address],Class,EntranceDateTime) VALUES('yang_'+CONVERT(NVARCHAR(10),@i),RAND()*10+7,RAND()*100+50,'厦门土豪小区1座'+CONVERT(NVARCHAR(10),CONVERT(INT,RAND()*100+1))+'号',CONVERT(NVARCHAR(10),CONVERT(INT,RAND()*6+1))+'年级',GETDATE()) SET @i=@i+1; END1.合理的使用索引提高查询速度 查询表里,所有年龄为10的名字,如图:



 从图中可以看出,使用了聚集索引扫描,逻辑读取55057次
添加索引:
从图中可以看出,使用了聚集索引扫描,逻辑读取55057次
添加索引:
CREATE NONCLUSTERED INDEX [IX_Student_Age_Name] ON [dbo].[Student] ( [Age] ASC ) INCLUDE ( [Name]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO 、

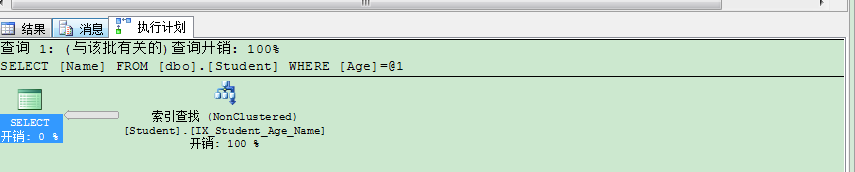

 很明显的看出来,查询优化器使用了索引查找,逻辑读取次数变少为:2411,很可观。
(在执行计划中看到索引查找,就是说明索引被使用到了,如果出现索引扫描就说明索引没有被使用到)
这里注意:
误区:我添加了索引查询速度就一定比表扫描来得快,并且索引一定会被使用
我的总结理解:一,索引不一定比扫描快,在数据量少的情况下,使用表扫描会比索引来得快,二,添加了索引不一定会被使用,首先要知道sqlserver在执行语句的时候会选择最优耗能少的方案去执行,在索引无法达到最高效的情况下,就不会被使用到。
比如:
下面的查询操作,就没有使用到索引了,而是使用到了聚集索引扫描
很明显的看出来,查询优化器使用了索引查找,逻辑读取次数变少为:2411,很可观。
(在执行计划中看到索引查找,就是说明索引被使用到了,如果出现索引扫描就说明索引没有被使用到)
这里注意:
误区:我添加了索引查询速度就一定比表扫描来得快,并且索引一定会被使用
我的总结理解:一,索引不一定比扫描快,在数据量少的情况下,使用表扫描会比索引来得快,二,添加了索引不一定会被使用,首先要知道sqlserver在执行语句的时候会选择最优耗能少的方案去执行,在索引无法达到最高效的情况下,就不会被使用到。
比如:
下面的查询操作,就没有使用到索引了,而是使用到了聚集索引扫描

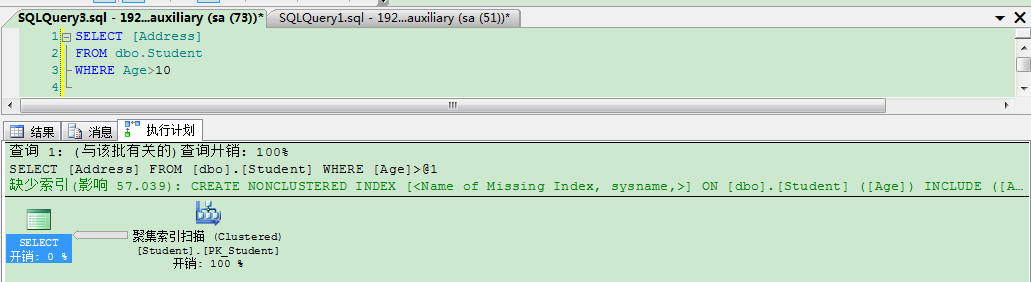

 出现上面的情况是为什么呢?
因为我创建的索引里,只有覆盖了Name字段,现在我查询的是Address字段,不在索引的覆盖中,那么查询优化器在执行语句的时候就没有使用到了索引,选择了开销更小的聚集索引扫描
但是我就是这么任性,要强制要求使用索引来查询,结果如截图:
出现上面的情况是为什么呢?
因为我创建的索引里,只有覆盖了Name字段,现在我查询的是Address字段,不在索引的覆盖中,那么查询优化器在执行语句的时候就没有使用到了索引,选择了开销更小的聚集索引扫描
但是我就是这么任性,要强制要求使用索引来查询,结果如截图:


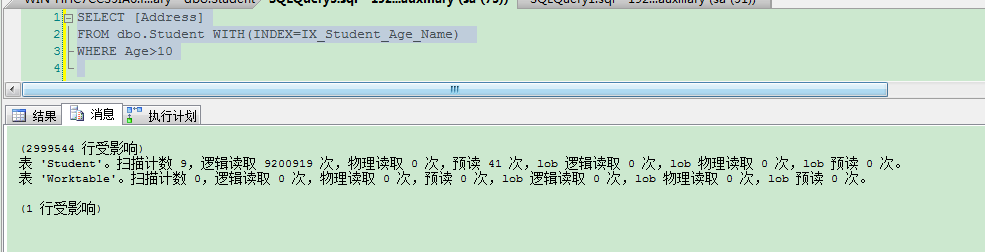
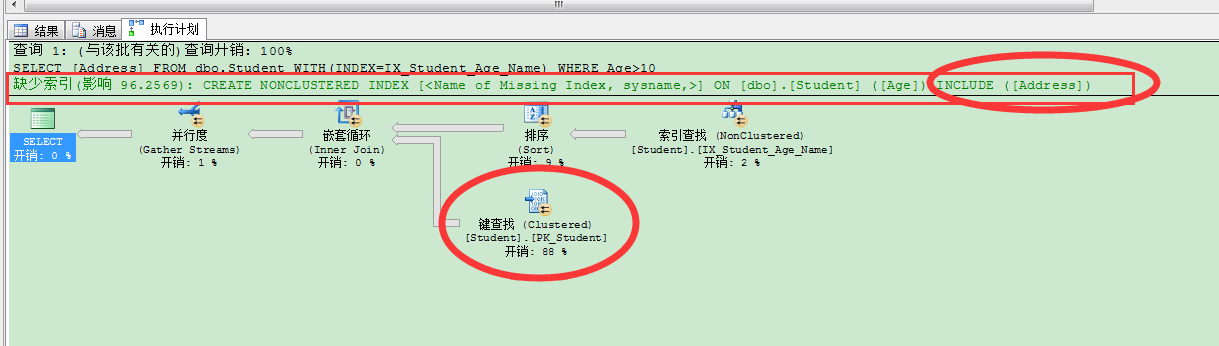 这个结果就很明显了,逻辑读次数,和扫描次数多了很多。计划里也给了提示,让我们索引覆盖Address字段
2.合理的使用聚集索引
我们在添加表的主键的时候就会默认的将主键添加为聚集索引,但是并不是聚集索引就一定要是主键字段,一张表就只能添加一个聚集索引,所以合理的利用聚集索引的特性,可以很大的提高查询速度。
一般我们都是在自增的ID设置为主键,但是又很少会对ID进行查询操作,更多的会对表中的其他字段进行查询,比如:时间字段。
这个时候就可以将聚集索引加到时间字段里,你会发现整个查询就会高效很多。
3,4,5,6
未完待续。。。
-----------------------------------[我只是美丽的分割线]-----------------------------------------
索引的优缺点
优点: 加快访问速度, 加强行的唯一性
缺点: 带索引的表在数据库中需要更多的存储空间,操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
创建索引的指导原则
请按照下列标准选择建立索引的列:
该列用于频繁搜索
该列用于对数据进行排序
请不要使用下面的列创建索引:
列中仅包含几个不同的值。
表中仅包含几行。为小型表创建索引可能不太划算,因为SQL Server在索引中搜索数据所花的时间比在表中逐行搜索所花的时间更长
假设我们在Col1列上创建了单列索引,可以在以下谓词上进行索引查找:
这个结果就很明显了,逻辑读次数,和扫描次数多了很多。计划里也给了提示,让我们索引覆盖Address字段
2.合理的使用聚集索引
我们在添加表的主键的时候就会默认的将主键添加为聚集索引,但是并不是聚集索引就一定要是主键字段,一张表就只能添加一个聚集索引,所以合理的利用聚集索引的特性,可以很大的提高查询速度。
一般我们都是在自增的ID设置为主键,但是又很少会对ID进行查询操作,更多的会对表中的其他字段进行查询,比如:时间字段。
这个时候就可以将聚集索引加到时间字段里,你会发现整个查询就会高效很多。
3,4,5,6
未完待续。。。
-----------------------------------[我只是美丽的分割线]-----------------------------------------
索引的优缺点
优点: 加快访问速度, 加强行的唯一性
缺点: 带索引的表在数据库中需要更多的存储空间,操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
创建索引的指导原则
请按照下列标准选择建立索引的列:
该列用于频繁搜索
该列用于对数据进行排序
请不要使用下面的列创建索引:
列中仅包含几个不同的值。
表中仅包含几行。为小型表创建索引可能不太划算,因为SQL Server在索引中搜索数据所花的时间比在表中逐行搜索所花的时间更长
假设我们在Col1列上创建了单列索引,可以在以下谓词上进行索引查找:
Ø [Col1] = 3.14 Ø [Col1] > 100 Ø [Col1] BETWEEN 0 AND 99 Ø [Col1] LIKE 'abc%' Ø [Col1] IN (2, 3, 5, 7)然而,在以下谓词上将不能使用索引查找:
Ø ABS([Col1]) = 1 Ø [Col1] + 1 = 9 Ø [Col1] LIKE '%abc'-----------------------------------[我只是美丽的分割线]-----------------------------------------