春节期间,和朋友一起做了一个关于物流行业的系统优化,在此记录一下优化过程及过程中遇到的问题,用以备忘,同时分享给有类似需要的朋友.
首先交代一下背景:
- 数据库采用MS SqlServer 2008 R2, 数据库物理文件大小为150G.
- 系统大部分报表采用存储过程实时统计,前台系统通过视图实现.
- 快递物流行业,平均每天产生8000票新快递单,关系到单据网点及状态的流转,每票快递单表现在数据库中大概会产生8张新的其他跟踪单据.
- 数据库服务器: 8核CPU 256G 内存 1T固态硬盘, Windows Server 2008 64位操作系统.
- 正常时段(早6点-凌晨3点),平均实时在线用户数为4000+,闲时(凌晨3点-早6点)平均在线用户数为900+.
- 正常时段数据库服务器,CPU 占用率一直稳定徘徊在70%-90%的高位.
- 正常时段,系统功能使用异常卡顿,报表基本上出不来结果,数据库常常发生死锁.
在了解了以上背景后,我们对系统分别做了以下调整:
- 和核心业务无关的数据移除到另外的数据库, 如短信记录, 人员档案等.
- 优化索引.
- 核心业务的数据表采用按时段做分区表.
- 核心业务的数据提交采用根据操作日志按顺序合并后统一提交,而非直接操作原始数据库.
- 数据库读写分离.
- 写在开始之前,介绍几个常用的DBA命令.
首先, 在做数据库优化的时候,我们必须得知道为何要优化以及优化的方向,以及调整的方向,了解以下的几个常用数据库命令可能会对我们快速的分析和解决问题起到一定的帮助.
- a). 查看某段sql/存储过程的详细执行时间及执行的详细步骤:
SET STATISTICS PROFILE ON
SET STATISTICS IO ON
SET STATISTICS TIME ON GO
/*--你的SQL脚本开始*/
SELECT * FROM tb
/*--你的SQL脚本结束*/
GO
SET STATISTICS PROFILE OFF
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
通过设置STATISTICS我们可以查看执行SQL时的系统情况。选项有PROFILE,IO ,TIME。介绍如下:
SET STATISTICS PROFILE ON:显示分析、编译和执行查询所需的时间(以毫秒为单位)。
SET STATISTICS IO ON:报告与语句内引用的每个表的扫描数、逻辑读取数(在高速缓存中访问的页数)和物理读取数(访问磁盘的次数)有关的信息。
SET STATISTICS TIME ON:显示每个查询执行后的结果集,代表查询执行的配置文件。
- b).查看某个表的索引情况 : sp_helpindex 表名 .
- c).查看表存储的碎片情况: DBCC ShowContig (‘表名’) .
- d).整理表上的索引碎片: DBCC IndexDefrag .
- e).重建某个表的索引: DBCC DBREINDEX (‘表名’) .
- f). 查看某个表的数据量及所占磁盘空间: sp_spaceUsed ‘表名’.
- g). 收缩某个文件组: DBCC ShrinkFile .
- h). 修改数据库服务器名称: select @@ServerName ;/ sp_dropserver ‘oldServerName’;/ sp_addserver ‘newServerName’,'LOCAL' ;
- 索引优化.
在这里, 限于篇幅,不想谈论索引的概念问题.只提出几个建议以供大家参考.
- a).尽量不要将宝贵的聚集索引定义在毫无顺序的主键上, 改为定义在有顺序且较常用的查询条件列上, 如 本案例中 将业务表聚集索引由 ”guid主键 ”改为了 ”收件时间 ”.
- b).合理应用 ”包含索引”,当有多个大表关联的时候,若需要获取的关联表数据列不多,可尝试在需要关联表的关联字段索引上创建查询返回字段的包含索引. 此场景下会起到非常明显的效率提升.
- c). 合理的利用 “组合索引”,当关联查询的时候,若关联的条件有多个,或者在查询的时候,有多个组合条件,且这种组合条件常常都需要一起出现的时候,可尝试将这几个组合条件创建一个组合索引.
- d).尽量不要在有较多重复值的列上创建索引,因为即便创建了,也不一定能利用上,大多时候仅徒增存储空间.
- e). 时刻关注表索引的碎片情况,通过 “DBCC ShowContig (‘表名’)”命令查看碎片情况及索引命中率,当比值出现较低情况下, 建议使用 “DBCC DBREINDEX (‘表名’) ”命令重建其索引,此步骤可尝试创建一个作业,自动检查.
- 表分区.
在本案例中,几个关键的业务表数据量已经达到了千万/几十G的数据量,在这个数据量下,每次查询都变得异常慢,又特别是在这种高并发的状态下,服务器已经不堪重负,前文背景中已经提到,这么高配置的服务器下, CPU还长时间负荷在70%-90%,于是我们尝试着引入分区表来解决这个问题.在本案例中,以运单记录表为例.
- a). 新建文件组,文件组为一组物理文件的逻辑包含关系,本处我们分别对于运单,财务,基础数据,其他资料分辨创建了对应的文件组.
- b). 选择分区列,及创建分区索引,根据业务场景我们选择了”收件时间”,首先将原主键的聚集索引改为普通索引,其次将收件时间列转为了聚集索引.
- c). 创建分区函数,根据数据量及实际需求合理确定分区区间规则,常常查询请求一般都在一个季度内,所以我们在这里将分区区间定为按季度.即每三个月创建一个分区,并将数据分区的数据转移到指定的文件组中
- d). 在程序和存储过程中,检查无分区列条件的sql, 将分区列条件补充上,使其每次查询都尽量能预先知道数据的分区位置.
通过以上的表分区及索引优化步骤后,我们的系统在性能表现上有了很明显的提升,服务器CPU资源占用已经有效的下降到了40%-55%样子,通过介绍的第一个命令查看得知,相同的查询已经大大的降低了IO开销.
但问题往往并不是一帆风顺的, 第二天有人反馈,系统中的某些功能变得奇慢无比,根本就没有办法使用,比优化前更加的慢了, 是的,你没有听错, 有些功能比分区后更加的慢, 按常理来说应该不应该才对, 结果仔细检查,发现比较慢的地方基本由两方面原因:查询条件里面没有分区列字段”收件时间”条件 及 部分数据的”收件时间”为null,查询条件中无”收件时间”到好说,根据业务场景,补上这个条件即可.
对于有的数据初始状态”收件时间”为null的情况,结果某些操作后,该单据的收件时间才会录入的情况,引起慢的问题却并不容易解决,因为操作前后这个收件时间不一致,该条数据应该会落在两个不同的分区里面, 并且很可能是跨物理文件的,根据业务场景,发现初始状态收件时间为null的情况仅出现在特定的场景下, 于是在此过程中,我们通过引入一个中间表, 将这种特定场景下的数据优先产生在一个新的临时业务表中,待后续中的登记了收件时间后,再将该数据转移到正式的业务表中.
至此,由于分区引起的问题顺利的解决.
- 更新频繁的表 ”采用操作日志更新”来代替 ”直接操作原始数据库”.
因为高并发 ,数据操作入口较多, 数据库常常发生死锁,特别是对于运单表的处理尤为突出.针对这个情况,我们引入了操作日志表的概念, 然后后台新起一个服务, 定时将这个操作日志按顺序合并,将合并后的结果在更新到运单业务表,这样做就将运单数据的更新入口由系统中的各个并发点统一收归到这个后台服务中,也就有效的避免了这个表的死锁情况.
- 数据库读写分离.
其实经历了以上几步后,系统已基本起死回生了, 稳定运行了几天基本上大部分业务都已经能正常开展, 唯独实时统计的报表比较费时,为了分散主要报表的数据库访问压力,我们尝试了将数据库做读写分离,在本案例中,数据库同步我们采用数据库自带的复制技术,在这里将读写分离的关键步骤罗列在此,以供有需要的朋友参考.
- a).准备从库服务器,本处我们使用了和主库一样的环境, MS Sqlserver 2008 R2 + Windows Server 2008 64 bit.
- b).在主库服务器上安装ftp服务器,本处我们使用操作系统自带的ftp服务器,怎么开启操作系统的ftp服务,各位可自行谷歌.
- c).将主库数据库服务器设置为允许通过机器名登录(因为从库订阅的时候,只能使用服务器名称来连接,不能使用IP地址).
- d).将主库和从库服务器的 Sql Server 代理 服务开启.
- e).在主库服务器上新建数据库发布.本案例中的发布类型选择为”事务发布”并设置为将快照文件通过ftp服务传递.至于几种发布类型的区别以及发布的创建详细步骤,园子里面有很多人讨论过,本处就不做深入展开了.
- f).在从库服务器上新建数据库,并创建主库服务器的数据订阅,注意此处如果使用主库的服务器名称不能正常访问,可尝试在系统的etc文件中增加上IP的别名映射.
- g).可通过复制监视器查看数据的复制状态.正常运行两天过程中, 密切监视数据的同步状态,发现一切正常.
- h).调整程序, 增加从库的数据库连接,将除具有实时性质读取之外的数据库访问接口,调整为使用从库数据库连接.
- i).在一主一从数据库模式正常运行4天后,我们又尝试着将其数据库调整为一主多从的模式.
- 引入Web系统负载均衡.
关于负载均衡,有很多的实施方案, 甚至如果你们公司不差钱,可以引入F5这样的土豪利器来处理.在本案中,我们选用了微软的NLB, 这个组件已经集成在了Windows Server 版的操作系统中,关于NLB的使用,园子里面有很多大神的谈论过,或可参阅http://www.iis.net/learn/extensions/configuring-application-request-routing-(arr)/achieving-high-availability-and-scalability-arr-and-nlb,在此,本文就不深入阐述了.
- 后记.
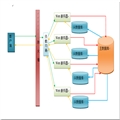
经过这一系列优化后,系统已经表现得比较良好,本阶段的优化也即将告一段落,当然随着时间的推移, 系统肯定会遇上更多的问题,或许这仅是该系统优化的一个开始. 当然每个生产环境都或多或少不一样,以上的步骤不一定适合每一个看官所遇到的问题,但或许能给你提供一个类似问题的思路.最后补充上这个系统最后优化完的部署结构草图作为本文的收尾,限于编辑方便,此部署图用word简单的画了一下,各位看官莫怪.
.