百度上暂时还没有搜索到相关的个人写的比较有价值的文章,至少在中文网络的世界里面没有
但是在微软的网站有这样一篇文章:《比较 SQL Server 与 IBM DB2》
文章从下面几个方面进行了对比
1、TCO和ROI
2、性能和可扩展性
3、高可用性
4、安全
5、管理
6、开发效率
7、商业智能和cangku.html" target="_blank">数据仓库
8、OLTP
9、SAP集成
文章介绍得比较牛逼
class="cueSectionTitle">性能与可扩展性
SQL Server 的性能和可扩展性优于IBM DB2.
基准显示SQL Server 能够掌控大型工作负荷:
- 在TPC-C 基准测试总,SQL Server每分钟的事务处理超过1百万,并且在 Windows平台上拥用最好的性能.
- 在 TPC-H 基准的10项比较中,有7项SQL Server优于DB2.
- 在一项 SAP-SD 认证基准中 支持 93,000个并发用户,相当于全球最大的SAP客户的10倍以上.
- 在新的OLTP基准标准-TPC-E中,SQL Server 是无可争议的领先者.
- 阅读最新的 SQL Server 2008 基准结果.
SQL Server 2008 包括最新的性能与可扩展性 ,能够优于DB2为大型工作负荷提供更好的性能:
成功案例
Citi Group runs Lava market montage解决方案 运行在SQL Server上, 达到每秒200,000次以上的更新频率
Xerox 采用SQL Server管理每天7百万的事务处理,达到99.999%运行时间
American Power Conversion 迁移至 SQL Server企业版---实现100%的快速响应时间,节省费用800,000美元
VHA 从DB2的大型机迁移至SQL Server—提升了25%效率, 降低了89%的复制时间, 显著降低了总拥有成本.
Countrywide Home Loans 选择了SQL Server以提高性能,获得高可用性
Microsoft IT 使用SQL Server来驱动 27TB的全球法定安全工具
Nasdaq, 全球领先的科技股交易,实时定票系统,采用SQL Server处理高达每秒5000的事务量.
Unisys UPSS system, 在 SQL Server上架构23 TB的数据仓库,进入了数据仓库峰值负荷的Top10行列.
Premier BankCard 将12 TB的数据仓库和OLTP数据库升级到SQL Server.
Danske Supermarket 在 SQL Server分析服务上运行600GB的的多维分析,以及10TB的商业智能数据
还有一个帖子《sqlserver的并发处理能力到底如何呀?高手都说说?》
其实这个题目是too open ended,无论大家认为它的定位在Oracle之下,还是只适合于中小型数据库,我只想说一下它在我眼中的能力
我相信我写完后其他数据库爱好者就会出来喷了,Oracle的、MySQL的,毕竟这种文章跟《C#和JAVA哪家强》之类的文章是比较类似的。
我在这篇文章主要讲两个大家最care的方面:数据量、性能和功能
其实大家刚开始用数据库最关心的莫过于OLTP场景里面的性能了还有这个数据库系统的所能够hold住的数据量
一、hold住大数据量
SQL Server作为一个成熟的商业数据库,对于hold住大数据量是没有问题的
正如上面文章提到的:Microsoft IT 使用SQL Server来驱动 27TB的全球法定安全工具
在本人所在公司也有一些比较大的数据库,数据库体积大的也有7~8TB,小的几十MB

很多人说:“SQL Server不能处理海量数据,数据量一大SQL Server就处理不了!”
我想问:“海量数据究竟有多少数据?1亿?10亿?100亿?1TB?10TB?100TB?”
反正我天天都对着这麽多数据(上TB也有、上十亿条也有),还是这样用SQL Server管理它们。
我这里想说明一下如何比较数据量:比较数据量应该用数据库的实际占用体积大小来比较,而不应该用单表数据量的大小来比较!
这里有一个例子:之前我们数据库服务器里有一个表,有六个字段,都是int类型,单表数据量已经1亿+了,但是数据库的大小只有20G不到
在我眼中只是一个比较小的数据库,虽然它的数据量比较惊人
在园友马非码的博客里曾经写到一篇文章《我是如何在SQLServer中处理每天四亿三千万记录的》,文章是非常多的推荐
但是在我眼里,文章没有多少新意,正如我刚才说的,四亿三千万数据可能就<100G的数据,这麽多数据其实跟SQL Server是否能hold住
没有多大关系,而是跟博主的架构能力有关系,数据库架构无非就是 分表-》分库-》分机房,解决CAP问题,还有就是MVCC的问题。
实际上,超大型数据库(VLDB)跟小型数据库管理起来是不一样的,这里我是不管它数据量,我只管它的数据库实际占用体积
对于管理大型数据库里面的大表,大家第一个想法就是使用表分区来管理它,表分区从SQL Server2005开始推出到现在SQL Server2014还是使用表分区
大家会说,微软还是没有什么突破,还是用这麽老的表分区技术来管理大表,甚至于有时候我做了表分区,但是整个数据库这麽大,我还是做不了完整备份。。。
貌似在大家的眼中,表分区只是作为一种提升查询性能的工具,更直接来说,就是提升Select Query性能的利器
但是对于我们DBA来说,分区表的优势更多的体现在管理方面
分区表的管理优势如下:
1、压缩单独某个分区的数据(SQL2008)
2、按分区的统计信息(SQL2014 CREATE STATISTICS 和相关统计信息语句现在允许通过使用 INCREMENTAL 选项创建按分区的统计信息)
3、联机重新生成某个分区的数据(SQL2014 针对联机索引操作事件类的进度报告现在具有两个新数据列:PartitionId 和 PartitionNumber)
4、联机重新组织某个分区的数据(SQL2005)
5、文件组备份和段落还原(SQL2005)
6、CHECKFILEGROUP(SQL2005)
7、交换分区(删除历史数据或归档 或进行ETL)
8、锁升级可以提升到分区锁,而不是直接到表锁(SQL2008)
其实只要表分区做得好,分区区间做得合理,定时维护分区表,hold住大数据量是没有多少问题的。
前年看到一篇文章,对于关系型数据库,如果数据库的实际占用体积到了100TB,关系型数据库已经无能为力了,该到Hadoop上场的时候了。
本人承认,如果你的数据库真的有100TB,那么SQL Server可能会没有能力handle,但是,你的数据库真的reached 100TB,那么你们公司的数据库架构师
是不是有责任承担这个风险,是不是他的数据库架构没有做好,没有分库分表分机房。
我先不管关系型数据库是否有能力handle这麽大的数据量,后来我又看了一个视频。
视频里面甲骨文技术产品事业部总经理吴承杨介绍了关系型数据库和Hadoop的区别,Hadoop是处理非结构化数据的
而关系型数据库是处理结构化数据的,两者的侧重点是不一样,Hadoop处理的是海量非结构化数据,一般数据量PB级别
而吴承杨总经理也讲到,非结构化数据通常指代的就是网页数据,Hadoop把这些数据经过处理之后就存放进去关系型数据库里面以便查询
所以不能把Hadoop和关系型数据库相提并论。
二、SQL Server的性能
性能方面,我只想谈论一下IO
大家知道不管Windows还是Linux,都是 用户程序->OS内核->存储设备这种架构,用户程序和OS内核之间存在一套IO接口
同样,OS内核和存储设备之间一样存在一套IO接口,有异步,同步,存储设备的Write Through和Write Back等参数
而caozuoxitong.html" target="_blank">Linux操作系统的IO行为跟Windows有很多不同之处的,两者的文件系统的不同,两者的IO设备驱动不一样,IO调度模型不一样
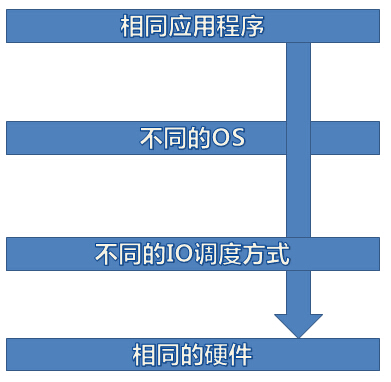
由于本人对Windows和Linux的IO调度没有太深入研究,大家可以参考下面两篇文章
Linux五种IO模型性能分析
Windows五种IO模型性能分析
其实一般不是太差的数据库都可以达到上千的TPS,上万的QPS,上万的并发连接
由于本人没有亲自测试也没有环境,就不再详细说了
之前看过一本书,里面说Linux的IO调度模型对于使用网络存储的机器来讲更加好,上层的一个请求,对于下层少量的网络数据包
而Windows上层的一个IO请求会对网络存储发出比Linux还多的网络数据包,好像是iSCSI协议,所以运行在Linux上的Oracle和MySQL会更胜一筹
但是可以说,SQL Server针对Windows系统做过特别优化,在TPS和QPS各方面测试中不会跟主流数据库相差很远,不然的话SQL Server早就从地球上消失了
三、SQL Server的功能
本人觉得SQL Server的功能做得是比较完善了,最起码对于一个商业数据库,其他竞争对手有的功能,SQL Server基本都有
例如限制资源使用这个功能

SQL Server的资源调控器可以针对登录用户限制它所使用的CPU、内存、IO资源
而MySQL的Query Throttling针对的是
限制用户每小时的修改数据库数据的数量
控制用户每小时打开新连接的数量
限制有多少用户连接MYSQL服务器
MySQL的Query Throttling偏向于查询方面的
我这里不评论好坏,我只想说各有各的优缺点
到目前为止,我还未发现其他数据库有的功能,SQL Server没有的,或者本人才疏学浅,可能Oracle有的功能而SQL Server没有的
比如:Oracle中的位图索引,而在SQL Server中位图过滤(Bitmap)运算符
相关文章:《SQL Server优化器特性-位图过滤(Bitmap)》
很多时候只是大家的实现方式不一样已而,而不代表SQL Server没有
总结
本人做DBA的时间不长,在学校开始接触,到毕业之后公司使用SQL Server,到现在由它来带我进入DBA这个行业
对于SQL Server这个产品,本人是比较感激的,每天跟各位SQL Server爱好者讨论如何使用它,不亦乐乎
只可惜SQL Server在中国国内市场越来越不活跃,不知道以后会不会有尽头。
如有不对的地方,欢迎大家拍砖o(∩_∩)o