(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
这几天研究了一下 disruptor .Net版,由于.Net版跟进不及时,网上只有 v2.10 版。没仔细研究,但可以肯定的是跟最新的Java版 disruptor 3.30 是有不少区别的。我也用这个 2.10 的.Net版本写了跟我们的问题相似的测试程序,得到的结果跟 Java 版的 disruptor 3.30 差不多。我还下载了 C++ 版的,不过看了一下,就扔一旁了,一个原因是版本太低,另一个原因是动不动就 boost,动不动就C++11,我是崇尚轻便、依赖小的,真要用我还不如自己写一个,所以我也懒得用他们来测,我已经在着手把 disruptor 3.3 的原理搬到 C++ 上来。
为了方便,我把修改的 disruptor .Net 版上传到了github:https://github.com/shines77/Disruptor.Net,其中 VS2013-Net 4.5 是VS 2013使用 .Net Framework 4.5的版本,因为原版使用的是 .Net 4.0,但升级到 4.5 某些文件要修改一下,所以分成了两个版本。经过我的调整,.Net 4.5的版本更细致一些,x64 和 x86 是严格分开的,本质上并没有大的区别。disruptor .Net 2.10 原版的 github 地址是:https://github.com/disruptor-net/Disruptor-net。如果你不想下载完整的项目,也可以在这里 nPnCRingQueueTest.cs 查看测试代码,在 RingQueue\disruptor\csharp 目录下面。
我们先来看 RingQueue,在上一篇里其实有些 RingQueue 测试的截图,不知道有没有细心的读者发现谁快谁慢,快多少?我们来看一下截图:

我们可以看到,混合自旋锁 spin2_push() 最快,而使用操作系统的互斥锁版本 mutex_push() 最慢,前者是后者的 3.5 倍左右。
经过多次测试我们发现,其实 spin_push(),spin1_push(),spin2_push() 速度差不多,但 spin2_push() 相对稳定一些,由于多线程程序受影响的因素很多,所以实际测试的时候,会发现每次结果都不太一样,但总体来看,spin2_push() 是里面最稳定的。
那么,我们来看看 q3.h 的测试结果:
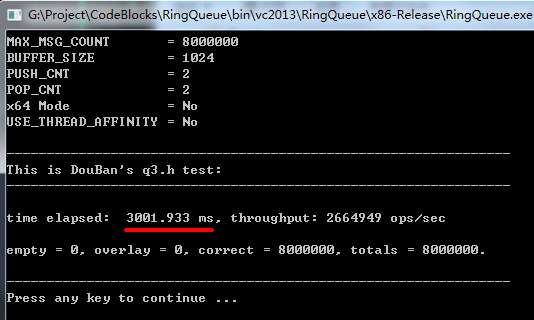
我们发现,q3.h 比 操作系统的互斥锁版本还要慢一些,细心的读者肯定会问,为什么 q3.h 测试的时候只用了4个线程?而前面却用了8个线程。这是由于 q3.h 本身代码的限制,当总线程数大于实际CPU核心数时会很慢很慢,因为我的CPU是4核的,所以它只能用 PUSH_CNT = 2, POP_CNT = 2 来测试,实际上,即使前面那些测试也用2个 push 线程和2个 pop 线程,结果还是要比 q3.h 快的,有兴趣的朋友可以自己试一下。此外,q3.h 通过修改是可以解决这个限制的,这是后话。
综上可得,我们的混合自旋锁 spin2_push() 的效率还是不错的,是 q3.h 的 4.18 倍左右,spin2_push() 的实际用时的最小值其实比 716 毫秒要小很多,甚至最快的时候可以达到 580 毫秒左右。
这里重新说明一下我的测试环境:
CPU: Intel Q8200 2.4G / 4核
系统: Windows 7 sp1 / 64bit
内存: 4G / DDR2 1066 (双通道)
编译平台: Visual Studio 2013 Ultimate update 2 (自带的 cl.exe)
以上的结果都是在 x86 模式下测得的(64位系统是兼容x86模式的),由于 x64 模式下 Sleep(1) 效率有问题,这将导致系统互斥锁版本变得非常慢(要十几秒或几十秒),估计系统互斥锁也用了类似 Sleep(1) 的代码。我们用到了 Sleep(1) 代码的 spin_push(),spin1_push(),spin2_push() 也会受一点影响,不过影响很小很小。至于为什么会这样还不太清楚,所以没用 x64 模式来测。
为什么 spin2_push() 这么快呢?通过这些天的研究和比较,我分别测试了 Java 版的 disruptor 3.30 和 .Net 版的 disruptor 2.10,下面给出两者的测试结果:
Java 版的 disruptor 3.30:

.Net 版的 disruptor 2.10:
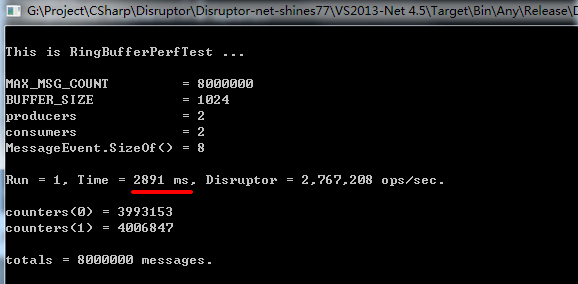
这里你一定想知道为什么 disruptor 这么慢?其实我也很想知道。。。
我们注意到,disruptor 给我们带来了新的视野,多种多样的场景(1P + 1C,1P + 多C,多P + 1C),以及各式各样的消息处理方式,是值得我们学习的一个好东西。尤其是在单生产者或单消费者模式下,是可以简化的,这是我们原来没考虑过的,这里也暂不考虑,我们还是以多生产者+多消费者模式来讨论,因为单生产者或单消费者模式相对简单很多。
disruptor 在单生产者+单消费者(1 producer + 1 comsumer)的时候,还是非常快的,这个时候的确是 lock-free 的,其实此时不仅仅是 lock-free 的,而且还是 wait-free 的,除了队列满了或空了的时候要等待以外(这个每种方法都是必须等待的)。不过,由于 disruptor 并未完全为 1P + 1C 模式特别优化,只是考虑了 1P + 多C,所以其消费者并不是 wait-free 的。虽然 disruptor 的 1P + 1C 模式很快,但其实还可以更快。而实际测试来看,1P + nC 模式(单生产者+多消费者)也不见得快,实测中 2P + 2C 倒是比 1P + 3C 还要快一些,原因不明。
这里可以参考《Disruptor使用指南》一文,disruptor 为我们提供了很多场景,最常用的是 EventHandler,EventHandler 是让每个 EventProcessor 从队列中取出消息并都处理一遍,即消息是被重复处理的,由于我们要实现的是多生产者、多消费者的 FIFO(先入先出)的消息队列,所以 EventHandler 不符合。参考该文的叙述,我们知道只有 WorkerPool + WorkHandler 模式才符合我们的场景:


这里还要指出的一点是,就在写本文的同时,我在看单生产者 SingleProducerSequencer.java 的 publish() 函数时(其中的 cursor 是一个Sequence类),发现:

转到 Sequence.java 里,Sequence::set() 函数定义如下:(其实之前我一直以为 set 就是单纯的一个写入操作而已,而且也不懂 putOrderLong() 具体是什么意思)
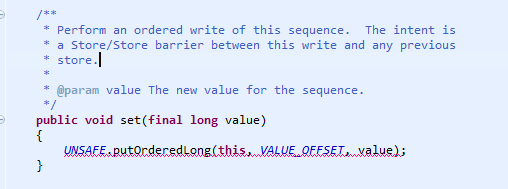
通过网上的搜索,我意外的发现,其实 UNSAFE.putOrderedLong(this, VALUE_OFFSET, value); 这个函数内部使用了一个全局自旋锁来保证写入/存储的顺序,可参考《源码剖析之sun.misc.Unsafe》。

不仅仅如此,Java 所有 Unsafe 的原子操作(CompareAndSwap等)里面都使用了这个spinlock,具体可以参考该文。这个spinlock是一个 static 的静态变量,所以所有这些操作都可能会导致一定的自旋,虽然这个自旋等待的时间也许很短很短,但这跟单一的CAS局部循环是不一样的,因为单一的CAS等原子操作只要处理的地址不一样,锁住的 Cache Line 就跟别的地方的原子操作的地址很可能是不一样的,被阻塞而互相影响的可能性比较小。而 spinlock 锁住的是同一条 Cache Line,要阻塞都一起阻塞。不过这个影响很难评估,但至少这不是一个好的做法。
spinlock 的代码是这样的:

所以,不管 disruptor 想出多么好的 lock-free, wait-free 算法,其内部的实现里必然包含了“锁”, 所以永远不可能是“无锁”的。其实在 disruptor 3.30 (Java版) 里,即使是在多生产者+多消费者模式里,disruptor 还真的实现了 lock-free 的方法(如果不算Unsafe 的锁的话),但是多用了一个跟 BUFFER_SIZE 一样大小的数组来记录 Flag,然后每次生产者还要在一个包含所有消费者的序号数组(记录每个消费者已读取的序号)里找出一个最小的来,这个消耗也不见得是很小的,虽然可能会比非 lock-free 的方法要快一些。
至于为什么这么慢,还在进一步研究中,可能有一部分还是跟语言本身有点关系。而且 disruptor 还存在一个问题,就是线程越多越慢,而 spin2_push() 线程越多则越快,不过也有个极限,但是这符合我们常说的线程数最好设置为 CPU总核心数 的两倍左右的经验值。此外,关于 disruptor 我会另外写一篇文章详细讨论。
我们在第四篇 (四)RingQueue(上) 自旋锁 里面有提到,我们之所以选择自旋锁是因为 q3.h 可以认为是由两个 lock-free 结构和两个 “锁” 构成的,所以我们不妨直接用一个 “自旋锁” 。比如 push(),CAS循环领取序号的时候,所有 push() 线程都会在这上面竞争,竞争主要在 q->head.first 所在的 Cache Line 的被锁而缓存失效的问题,而 head = q->head.first; tail = q->tail.second; 也会受其他地方写入该值时导致缓存失效。然后是确认提交成功后的序列化过程,这个过程是一个真正的“锁”,会导致别的线程被阻塞。而且 q3.h 的失误就在于没在这个地方做合理的休眠,这就导致了当总的线程数超过核心数的时候,某个线程阻塞了别的线程,而这个线程又得不到时间片,从而导致livelock,虽然最终该线程还是可以获得时间片,但是其他线程已经白白的等了很久了,而且没有休眠,CPU占用一直是很高的,整个过程又很慢。所以解决这个问题,就是在这个“锁”的过程中,适当的自旋、yield()或休眠一下。这个“锁”本身不会造成缓存行失效,但是如果 q->head.second 被写入新值的时候,还是会导致伪共享(False Sharing)的问题。同理,pop() 的分析也类似。这里跟 spin2_push() 来比的话,有点是产生竞争的线程数少了一半(假设生产者和消费者线程是一样多的),缺点是竞争的点多了,自旋锁竞争的点只有一个,就是锁的循环上,只要进了锁,由于只有一个线程能获得写入和读取的权力,此时对RingBuffer内部的操作并不会产生伪共享(False Sharing)问题,因为“一夫当关,万夫莫开”。
q3.h 的另一个问题是,在第三篇文章里也说过了,就是 head.first,head.second,tail.first,tail.second 四个变量应该在 4 条不同的Cache Line(缓存行)上,以减少缓存失效的问题(即伪共享)。这点 disruptor 是做得很好的,也许 q3.h 解决了这些毛病以后会快一点,但不知道会快多少,以后有时间我会加进去试一下,不过肯定是比 disruptor 现在的版本改成 C++ 是要慢的,这可以肯定。
那么,现在我们来看看我们的混合自旋锁 spin2_push(),可查阅 RingQueue.h 中的 spin2_push_() 函数:
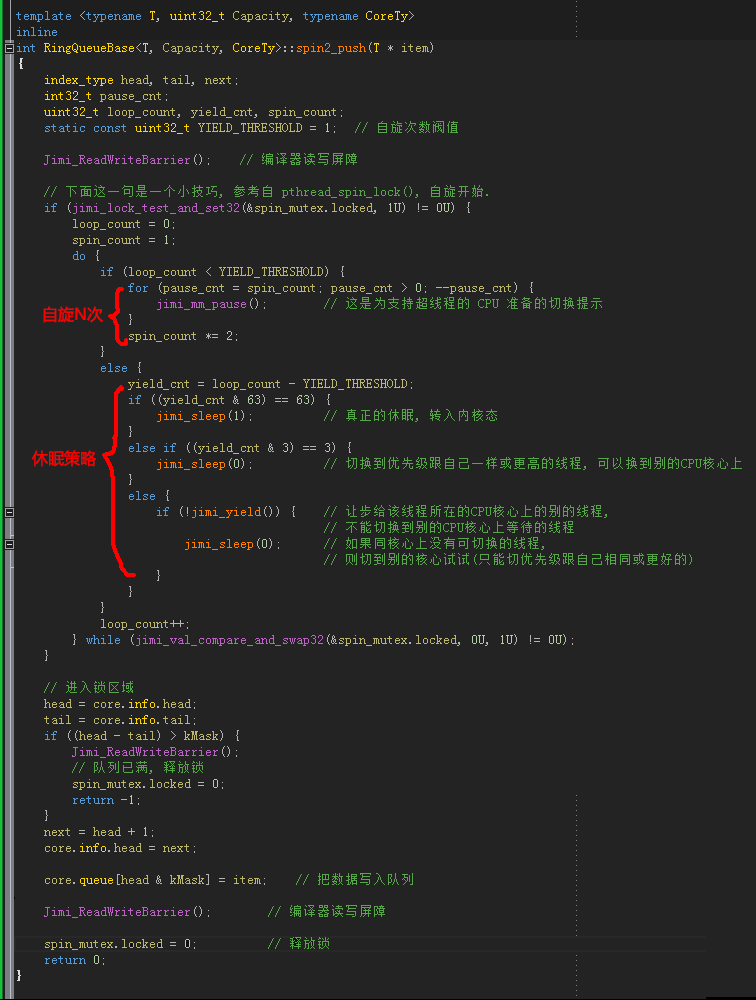
在上一篇的末尾,我提到了 Thread.Yield(),yield 是让步、低头、出让的意思,也就是说把CPU的主动权交给别的线程。前面也说到 DengHe.Net (老邓) 曾经贴过的用反射工具查看的 C# 源码,其实不是 Thread.Yield(),而应该是 System.Threading 下面的 SpinWait() 类。这里注意,不是 Thread.SpinWait(n),Thread.SpinWait(n) 其实是一个自旋 n 次的循环,而 Thread.Yield() 被定义为 Windows API SwitchToThread(),spin2_push() 里面的 jimi_yield() 在 Windows 上就是定义为 SwitchToThread(),该函数是一个很特殊的函数,在上图的 jimi_yield() 的注释里我已经写了,它的功能是让步给该线程所在的CPU核心上的别的等待线程(但不能切换到别的CPU核心上的等待线程),后面我们也会详细讨论。
而我们提到的 SpinWait() 类则跟我们这个 spin2_push() 长得很像,其实我们是模仿它的。SpinWait.cs 的源码可以在网上查到,我已经上传至 github 上:SpinWait.cs,在 RingQueue 项目里的 \douban 目录下面。
我们来看一下 SpinWait.cs 长什么样子?我们来看两个比较重要的地方:

还有 SpinOne() :

你可以看到,我对 SpinOne() 做了几点改进,SLEEP_0_EVERY_HOW_MANY_TIMES 改为了4,SLEEP_1_EVERY_HOW_MANY_TIMES 改为了64,这是执行 Sleep(0) 和 Sleep(1) 的间隔值,这是为了计算 % 是使用位运算效率高一点,其实这个地方用 % 也没多大区别,即用 5 和 20 也是可以的,不过根据我的经验 20 可以稍微设大一点,尤其是在 x64 模式下,前面我也稍微提到过原因,这是一个经过多次测试后得出的经验值,具体的可自己试情况调整。
其实关键的地方是自旋次数的设定,你可以看到 SpinWait.cs 用的阀值是 10,而 spin2_push() 里面有的是 1(设置成2也可以),其实这是一个很关键的地方,这个地方决定了混合自旋锁的性能,它是由你要锁的区域进行的操作持续多长时间而决定的,锁持有的时间短的话,我们自旋的次数就应该要少,而持有的时间长,则可以设大一点,但是不能太大,太大的化就会一直自旋而浪费 CPU 时间。因为我们与其让它自旋很久,不如看看别的线程有没有需要,有需要的话,我们先切换到别的线程,把时间片让给它。如果别的线程也不需要时间片,重复一点的次数后,我们就让线程进入休眠状态,即Sleep(1)。这里 Sleep(0) 并不是休眠,而是切换到跟自己相同优先级或更高优先级的线程,后面我们会讲,spin2_push() 的函数的截图里也有详细的注释和说明。
我们把 SpinWait.cs 中 SpinOne() 函数的这个策略称之为 “休眠策略”,而如何更好的进行休眠,则是一种“休眠的艺术”。
我们先来研究一下操作系统的 进程/线程 调度原理。
操作系统中,CPU 进程/线程调度有很多种策略,Unix 系统使用的是时间片算法,而 Windows 则属于抢先式的。
在时间片算法中,所有的进程排成一个队列。操作系统按照他们的顺序,给每个进程分配一段时间,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前挂起或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它将被移到队列的末尾。
所谓抢先式操作系统,就是说如果一个进程得到了 CPU 时间,除非它自己主动放弃使用 CPU,否则将完全霸占 CPU 。因此可以看出,在抢先式操作系统中,操作系统假设所有的进程都是“人品很好”的,会主动让出 CPU 。
在抢先式操作系统中,假设有若干进程,操作系统会根据他们的优先级、饥饿时间(已经多长时间没有使用过 CPU 了),给他们算出一个总的优先级来。操作系统就会把 CPU 交给总优先级最高的这个进程。当进程执行完毕或者自己主动挂起后,操作系统就会重新计算一次所有进程的总优先级,然后再挑一个优先级最高的把 CPU 控制权交给他。
我们用分蛋糕的场景来描述这两种算法。假设有源源不断的蛋糕(源源不断的时间),一副刀叉(一个CPU),10个等待吃蛋糕的人(10 个进程)。
如果是 Unix/Linux 操作系统来负责分蛋糕,那么他会这样定规矩:每个人上来吃 1 分钟,时间到了换下一个。最后一个人吃完了就再从头开始。于是,不管这10个人是不是优先级不同、饥饿程度不同、饭量不同,每个人上来的时候都可以吃 1 分钟。当然,如果有人本来不太饿,或者饭量小,吃了30秒钟之后就吃饱了,那么他可以跟操作系统说:我已经吃饱了(挂起)。于是操作系统就会让下一个人接着来,而刚吃饱的会被安排到队伍的最后面。
如果是 Windows 操作系统来负责分蛋糕,那么场面就很有意思了。他会这样定规矩:我会根据你们的优先级、饥饿程度去给你们每个人计算一个优先级。优先级最高的那个人,可以上来吃蛋糕——吃到你不想吃为止。等这个人吃完了,我再重新根据优先级、饥饿程度来计算每个人的优先级,然后再分给优先级最高的那个人。
这样看来,这个场面就有意思了——有的人是年轻MM,而且长得漂亮,因此天生就拥有高优先级,于是她就可以经常来吃蛋糕。而另外一个人可能是个穷屌丝,而且长得也挫,所以优先级特别低,于是好半天了才轮到他一次(因为随着时间的推移,他会越来越饥饿,因此算出来的总优先级就会越来越高,因此总有一天会轮到他的)。而且,如果一不小心让一个大胖子得到了刀叉,因为他饭量大,可能他会霸占着蛋糕连续吃很久很久,导致旁边的人在那里咽口水……
而且,还可能会有这种情况出现:操作系统现在计算出来的结果,5号漂亮MM总优先级最高,而且高出别人一大截。因此就叫5号来吃蛋糕。5号吃了一小会儿,觉得没那么饿了,于是说“我不吃了”(挂起)。因此操作系统就会重新计算所有人的优先级。因为5号刚刚吃过,因此她的饥饿程度变小了,于是总优先级变小了;而其他人因为多等了一会儿,饥饿程度都变大了,所以总优先级也变大了。不过这时候仍然有可能5号的优先级比别的都高,只不过现在只比其他的高一点点——但她仍然是总优先级最高的啊。因此操作系统就会说:5号MM上来吃蛋糕……(5号MM心里郁闷,这不刚吃过嘛……人家要减肥……谁叫你长那么漂亮,获得了那么高的优先级)。
以上参考自:《理解 Thread.Sleep 函数》 http://www.cnblogs.com/ILove/archive/2008/04/07/1140419.html
(楼主后记:本来是在写此文之前搜索一下“C# SpinWait”,没想到看到这么一篇文章,正好用来解释操作系统的调度原理,本来我对 Linux 和 Windows 的调度区别并不是特别清楚,看了这篇文章后,正好弥补了这个问题。)
我们前面提到5号MM说“我吃饱了,先不吃了”(挂起),这是怎么实现的?在 C# 中,就是使用 Thread.Sleep(n) 实现的,类似的 Windows API 是:Sleep(n); ,Linux API 是:sleep(n); usleep(n); 等,而对于 Java 来说,就是 Thread.sleep(n); 。那么 Thread.Sleep(n) 是什么意思呢?在 Windows 下,意思就是,我先休息 n 毫秒,不参与 CPU 的竞争。投射到分蛋糕的场景上就是,你们先吃,我吃得够饱了,未来半个小时内我都不想吃了,我让出位置,先休息 30 分钟再来。而在 Linux 下,意思也是一样的,唯一的区别可能就是休眠完成后怎么归队的问题。
在进程/线程休眠足够的时候后,重新参与 CPU 竞争的时候,在 Windows 下,是否是立刻把这个时间片分配给这个从休眠状态重新归队进程/线程,还是按照它的饥饿程度(因为休眠了许久)和线程的优先级,即休眠完成后重新计算的总的优先等级,跟其他进程/线程一起参与竞争,以选出一个总的优先级别最高的,再把时间片分配给该总优先级最高的进程/线程,而不一定是该重新被唤醒的进程/线程。不过从合理性的角度,前者更合理,因为后者可能导致即使你结束休眠了,但是由于可能你总的优先级别怎么都抢不过别进程/线程,而导致休眠结束后,可能会被延迟很久才能重新获得时间片,这看起来不太科学。但是 Windows 可能选择的是后者,MSDN 里提到,即使是 Sleep(0) ,也可能不一定保证会立刻被执行,进程/线程只是被设置为准备就绪状态。准备就绪的意思就是声明我要重新参与 CPU 的竞争了。
关于这个细节,我们来看看 MSDN 中 MSDN: Sleep() function 是怎么说的:
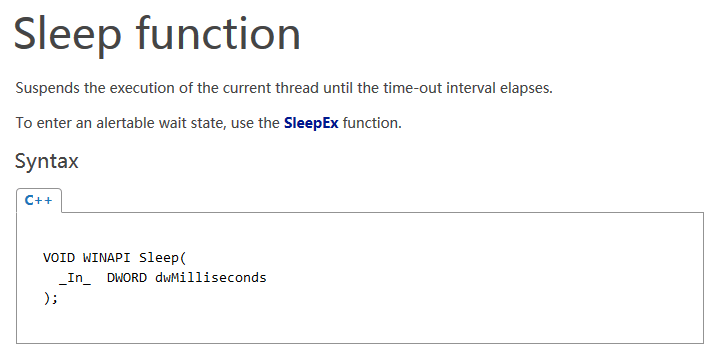

中文大意是:
在 Sleep 的间隔时间结束后,线程准备运行。如果你指定的休眠时间是 0 毫秒,那么线程将放弃剩余的时间片,但保持准备就绪状态。需要注意的是这个准备就绪的线程不能保证立刻被运行。因此,线程可能不能立刻被运行直到休眠一定 的时间间隔以后。想了解更详细的信息,可以参阅 Scheduling Priorities (调度优先级) 。
而 Scheduling Priorities (调度优先级) 里提到:

中文大意是:
操作系统对待相同优先级别的线程是平等的,操作系统以 轮叫循环 的方式分配时间片给最高优先级的线程。如果这个优先级别没有准备就绪的线程,系统将以 轮叫循环 的方式分配时间片给下一个优先级别的线程。如果一个高优先级别的线程变成可运行的,那么系统将终止低优先级的线程(即不允许它完成本来属于它的时间片),并且分配一个完整的时间片给更高级别的线程。想了解更多信息,请参阅 Context Switches (上下文切换) 。
名词解释:Round-robin scheduling (轮叫调度):以一定的时间间隔,轮流的方式执行相应的任务。
参考:http://en.wikipedia.org/wiki/Round-robin_scheduling
由此可知,《理解 Thread.Sleep 函数》一文中所说的也不完全正确,其实 Windows 也是有时间片概念的,只不过它不像 Linux 那样是平均分配的,抢先式的意思是,高优先级的线程如果有需要,是可以叫低优先级的线程让出时间片的,比较“霸道”。而整个系统调度依然是按某个时间片间隔来轮询(轮循)的,来决定选择那个线程来运行。一般来说,Windows 这个时间片大约是 10-15 ms 左右。这也是 Sleep() 函数默认设置下的最小精度,可以通过 timeBeginPeriod() 函数来修改这个最小精度。
而 Scheduling Priorities (调度优先级) 末段也提到:

中文大意是:
然而,如果有一个线程在等待其他低优先级的线程来完成某些任务,则一定要阻塞那些处于等待中的高优先级线程的运行。为了实现这个目的,可以使用 Wait Function (等待系列函数),critical section (临界区),或者 Sleep() 函数,SleepEx() 函数,或者 SwitchToThread() 函数。这些对于线程运行一个循环来说是一些可优选的方案。否则,处理器可能成为死锁状态(deadlocked),因为低优先级的线程可能永远都不会被调度到。
在这一段话里,微软暗示了我们,要进行良好的休眠和线程切换管理,是要分别使用 Sleep() 和 SwitchToThread() 函数的,而 jimi_yield() 在 Windows 下就等价于 SwitchToThread()。这跟我们前面提到的 SpinWait.cs 里是如出一辙的,我们分别使用了 Sleep(0),Sleep(1) 和 SwitchToThread()。而 Wait Functions 和 临界区,则没有研究过,临界区没什么好研究的,倒是 WaitForSingleObject() 这些函数跟 Sleep() 之间的差别倒是值得研究一下,不过好像没有那个地方用到这个技巧,所以暂时不予考虑。
待续 ……
先写到这了,发现要写完还得写很长,今天就写到这吧,稍后我会继续接着本篇文章后面写,不另开新帖了,好多之前想说的话都没写进去,有空我慢慢加,喜欢看的朋友请自行刷新。
如果你觉得写得不错的话,麻烦点一下推荐,或者评论一下,这样下次你找这个文章就可以从首页的 “我赞” 和 “我评” 里面找到了。
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下载UTF-8编码版:https://github.com/shines77/RingQueue-utf8。 我敢说是一个不错的混合自旋锁,你可以自己去下载回来看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,还支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等。
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
上一篇:一个无锁消息队列引发的血案:怎样做一个真正的程序员?(四)——月:RingQueue(上) 自旋锁
(未完待续……)