说到数据格式化框架,就不得不提到 Google 的 Protocol Buffers,Facebook 的 Thrift,还有 Apache Hadoop 推出的 Avro。Microsoft 最近开源的 Bond 也是一种用于数据格式化的可扩展框架,其适用的应用场景包括服务间通信、大数据存储和处理等。
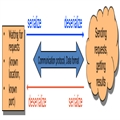
为什么会有这么多关于数据格式处理的框架?它们都在解决什么问题呢?我们先来观察一下典型的服务间通信的结构。

通常,在设计服务间通信时,我们所要面对的基本问题有:
随着服务系统架构的不断演进,我们会面对更多的问题:
那么,以前我们都是在用什么技术来解决这些问题的呢?
都是听起来很熟悉的名字。实际上,C 结构体仍然被广泛地应用于网络底层通信,DCOM, CORBA, SOAP 正逐步退出历史舞台。目前,最流行的就是基于 XML 或 JSON 的序列化机制。
但使用 XML 和 JSON 时也会面对一些问题:
那么,对于这些数据处理和序列化框架,从软件设计人员的角度来看,我们最需要的到底是什么呢?
所以,业界著名公司的开发人员分别推出了不同的框架,以期解决这些问题。包括 Google 的 Protocol Buffers,Facebook 的 Thrift,Apache Hadoop 的 Avro,和 Microsoft 的 Bond。
这些框架的一些共性:
这些框架的典型使用过程:
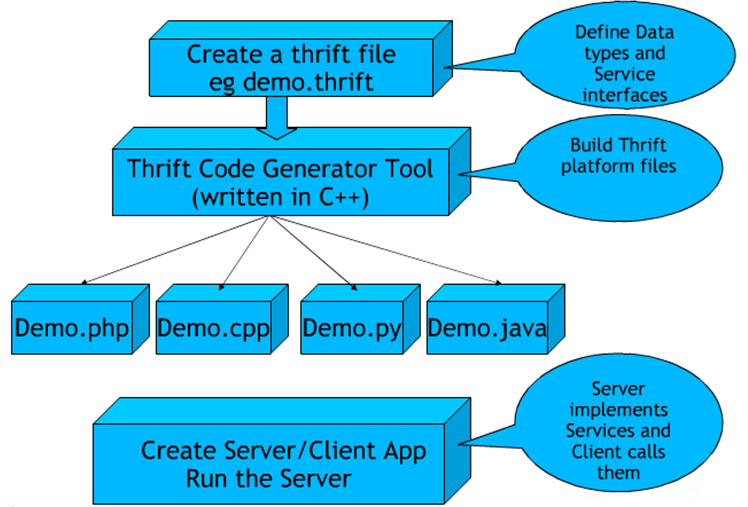
也就是说,用户首先需要定义数据结构,然后生成可以有效读写这些数据结构的代码,再将代码嵌入到服务端与客户端的代码中使用。
例如,下面使用 Protocol Buffers 的定义搜索请求消息 search.proto。
package serializers.protobuf.test; message SearchRequest { required string query = 1; optional int32 page_number = 2; optional int32 result_per_page = 3 [default = 10]; enum Corpus { UNIVERSAL = 0; WEB = 1; } optional Corpus corpus = 4 [default = UNIVERSAL]; }
使用代码生成工具生成 C# 代码如下。
1 namespace serializers.protobuf.test 2 { 3 [global::System.Serializable, global::ProtoBuf.ProtoContract(Name=@"SearchRequest")] 4 public partial class SearchRequest : global::ProtoBuf.IExtensible 5 { 6 public SearchRequest() {} 7 8 private string _query; 9 [global::ProtoBuf.ProtoMember(1, IsRequired = true, Name=@"query", DataFormat = global::ProtoBuf.DataFormat.Default)] 10 public string query 11 { 12 get { return _query; } 13 set { _query = value; } 14 } 15 private int _page_number = default(int); 16 [global::ProtoBuf.ProtoMember(2, IsRequired = false, Name=@"page_number", DataFormat = global::ProtoBuf.DataFormat.TwosComplement)] 17 [global::System.ComponentModel.DefaultValue(default(int))] 18 public int page_number 19 { 20 get { return _page_number; } 21 set { _page_number = value; } 22 } 23 private int _result_per_page = (int)10; 24 [global::ProtoBuf.ProtoMember(3, IsRequired = false, Name=@"result_per_page", DataFormat = global::ProtoBuf.DataFormat.TwosComplement)] 25 [global::System.ComponentModel.DefaultValue((int)10)] 26 public int result_per_page 27 { 28 get { return _result_per_page; } 29 set { _result_per_page = value; } 30 } 31 private serializers.protobuf.test.SearchRequest.Corpus _corpus = serializers.protobuf.test.SearchRequest.Corpus.UNIVERSAL; 32 [global::ProtoBuf.ProtoMember(4, IsRequired = false, Name=@"corpus", DataFormat = global::ProtoBuf.DataFormat.TwosComplement)] 33 [global::System.ComponentModel.DefaultValue(serializers.protobuf.test.SearchRequest.Corpus.UNIVERSAL)] 34 public serializers.protobuf.test.SearchRequest.Corpus corpus 35 { 36 get { return _corpus; } 37 set { _corpus = value; } 38 } 39 [global::ProtoBuf.ProtoContract(Name=@"Corpus")] 40 public enum Corpus 41 { 42 [global::ProtoBuf.ProtoEnum(Name=@"UNIVERSAL", Value=0)] 43 UNIVERSAL = 0, 44 45 [global::ProtoBuf.ProtoEnum(Name=@"WEB", Value=1)] 46 WEB = 1, 47 } 48 49 private global::ProtoBuf.IExtension extensionObject; 50 global::ProtoBuf.IExtension global::ProtoBuf.IExtensible.GetExtensionObject(bool createIfMissing) 51 { return global::ProtoBuf.Extensible.GetExtensionObject(ref extensionObject, createIfMissing); } 52 } 53 }
使用 IDL 定义的语法通常包括:
这里,为字段指定的标识符 "= 1", "= 2" 或 "1 : ", "2 : " 等称为 "Tag",这个操作称为 "Tagging"。这些 Tag 用于从二进制的消息中识别字段,所以一旦定义并使用,则后续不能修改。
Tag 的值在 1-15 区间时使用 1 byte 存储,在 16-2047 区间时使用 2 bytes 存储。所以,为节省空间,要将 1-15 留给最常使用的消息元素,并且要为未来可能出现的频繁使用元素留出空间。
下面是各框架在 IDL 定义层的比较:
注:"√" 代表支持,"×" 代表不支持,"-" 代表不涉及。
各开源数据格式化框架默认会支持若干编程语言,一些没有被默认支持的编程语言通常在社区中也会找到支持。下面是各框架默认支持的开发语言:
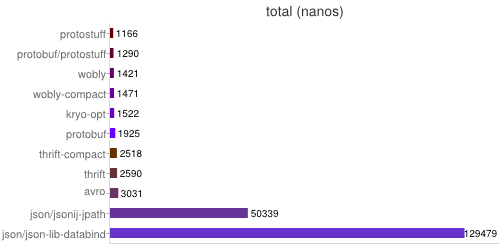
以下性能比较数据来自 GitHub eishay/jvm-serializers 。
Serializes only specific classes using code generation or other special knowledge about the class.
create ser deser total size +dfl kryo-opt 64 658 864 1522 209 129 wobly 43 886 536 1422 251 151 wobly-compact 43 903 569 1471 225 139 protobuf 130 1225 701 1926 239 149 protostuff 82 488 678 1166 239 150 protobuf/protostuff 83 598 692 1290 239 149 thrift 126 1796 795 2591 349 197 thrift-compact 126 1555 963 2518 240 148 avro 89 1616 1415 3031 221 133 json/json-lib-databind 63 26330 103150 129479 485 263 json/jsonij-jpath 63 38015 12325 50339 478 259
Total Time : Including creating an object, serializing and deserializing.
Serialization Time : Serializing with a new object each time (object creation time included).
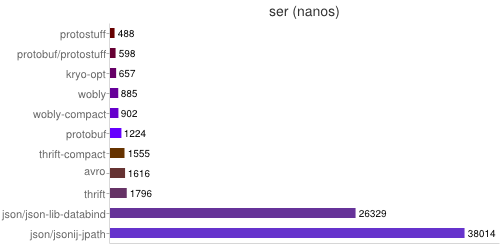
Deserialization Time : Often the most expensive operation. To make a fair comparison, all fields of the deserialized instances are accessed - this forces lazy deserializers to really do their work.

Serialization Size : May vary a lot depending on number of repetitions in lists, usage of number compacting in protobuf, strings vs numerics, assumptions that can be made about the object graph, and more.

Object Creation Time : Object creation is not so meaningful since it takes in average 100 nano to create an object.

各数据格式化框架通过 Tag 来支持版本控制,以支持前向和后向兼容。客户端与服务端的版本不匹配可归纳为 4 种情况:
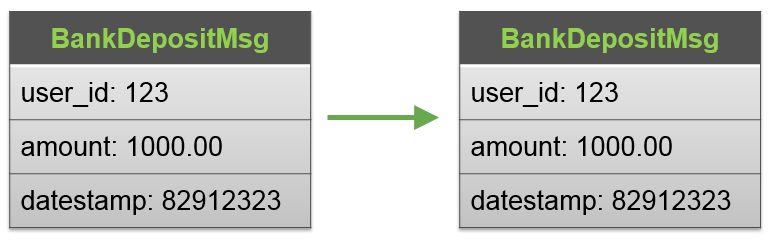
Client 端和 Server 端消息定义字段一致。
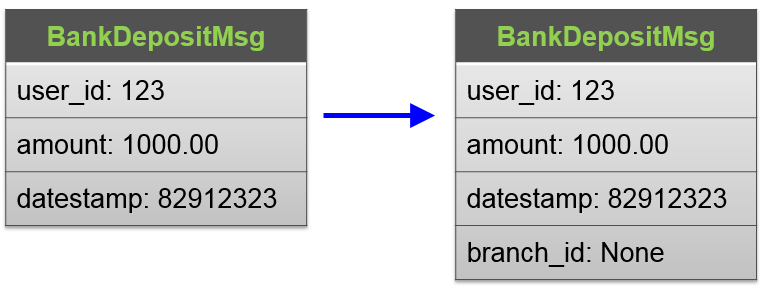
Client 端仍然使用旧版本。
Server 端消息定义新增字段 branch_id。
Server 端需要适配旧版本,也就是处理没有 branch_id 的消息。

Client 端消息定义新增字段 branch_id。
Server 端仍然使用旧版本。
Server 端解析消息时实际上直接忽略了 branch_id 字段,所以不会产生问题。
参考情况2。
参考情况1。
本篇文章《开源跨平台数据格式化框架概览》由 Dennis Gao 发表自博客园,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫转载行为均为耍流氓。