首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章都会被其他网站给抓取去了,不信你们看看就知道了。还有人抓取别人网站上的邮箱、电话号码、QQ等等有用信息,这些信息抓取下来肯定可以卖钱或者干其他事情,我们每天都会时不时接到垃圾短信或邮件,可能就这么回事了,有同感吧,O(∩_∩)O哈哈~。
本人前段时间了写了两个程序,一个程序是抓取某彩票网站的数据(双色球),一个是抓取求职网站(猎聘、前程无忧、智联招聘等等)的数据,当时在写这两个程序的时候显示尤为棘手,看到一堆的HTML标签真的是想死。首先来回顾一下之前我是如何解析HTML的,非常常规的做法,通过WebRequest拿到HTML内容,再通过HTML标签一步一步截取你想要的内容,以下代码就是截取双色球的红球和篮球的代码。一旦网站的标签发生一点变化可能面临的就是要重新改程序了,使用起来非常不方便。
下面是我在解析双色球的红球和篮球的代码,做得最多的是截取(正则表达式)标签相应的内容,也许这段代码显得还不是很复杂,因为这个截取的数据有限,而且非常有规律所以显得比较简单。
1 #region * 在一个TR中,解析TD,获取一期的号码 2 /// <summary> 3 /// 在一个TR中,解析TD,获取一期的号码 4 /// </summary> 5 /// <param name="wn"></param> 6 /// <param name="trContent"></param> 7 private void ResolveTd(ref WinNo wn, string trContent) 8 { 9 List<int> redBoxList = null; 10 //匹配期号的表达式 11 string patternQiHao = "<td align=\"center\" title=\"开奖日期"; 12 Regex regex = new Regex(patternQiHao); 13 Match qhMatch = regex.Match(trContent); 14 wn.QiHao = trContent.Substring(qhMatch.Index + 17 + patternQiHao.Length, 7); 15 //匹配蓝球的表达式 16 string patternChartBall02 = "<td class=\"chartBall02\">"; 17 regex = new Regex(patternChartBall02); 18 Match bMatch = regex.Match(trContent); 19 wn.B = Convert.ToInt32(trContent.Substring(bMatch.Index + patternChartBall02.Length, 2)); 20 //存放匹配出来的红球号码 21 redBoxList = new List<int>(); 22 //匹配红球的表达式 23 string patternChartBall01 = "<td class=\"chartBall01\">"; 24 regex = new Regex(patternChartBall01); 25 MatchCollection rMatches = regex.Matches(trContent); 26 foreach (Match r in rMatches) 27 { 28 redBoxList.Add(Convert.ToInt32(trContent.Substring(r.Index + patternChartBall01.Length, 2))); 29 } 30 //匹配红球的表达式 31 string patternChartBall07 = "<td class=\"chartBall07\">"; 32 regex = new Regex(patternChartBall07); 33 rMatches = regex.Matches(trContent); 34 foreach (Match r in rMatches) 35 { 36 redBoxList.Add(Convert.ToInt32(trContent.Substring(r.Index + patternChartBall07.Length, 2))); 37 } 38 //排序红球号码 39 redBoxList.Sort(); 40 //第一个红球号码 41 wn.R1 = redBoxList[0]; 42 //第二个红球号码 43 wn.R2 = redBoxList[1]; 44 wn.R3 = redBoxList[2]; 45 wn.R4 = redBoxList[3]; 46 wn.R5 = redBoxList[4]; 47 wn.R6 = redBoxList[5]; 48 }
下面这块的代码是某招聘网站的截取数据,就是一串的截取HTML标签的内容,哈哈,当时在写这个时候相当的头痛,不知有做个这方法工作的人是不是有同感,当你解析比较多网站的数据就更加了(我写了抓取前程无忧、猎聘网、前程无忧和拉勾网的数据),O(∩_∩)O哈哈~想死呀,使用正则表达是去截取数据,再去提取相应信息的工作。
// 正则表达式过滤:正则表达式,要替换成的文本 private static readonly string[][] Filters = { new[] { @"(?is)<script.*?>.*?</script>", "" }, new[] { @"(?is)<style.*?>.*?</style>", "" }, new[] { @"(?is)<!--.*?-->", "" }, // 过滤Html代码中的注释 new[] { @"(?is)<footer.*?>.*?</footer>",""}, //new[] { "(?is)<div class=\"job-require bottom-job-require\">.*?</div></div>",""} new[] { @"(?is)<h3>常用链接:.*?</ul>",""} }; private void GetJobInfoFromUrl(string url) { try { JobInfo info = new JobInfo(); //-- string pageStr = GetHtmlCode.GetByget(url, "utf-8"); if (string.IsNullOrEmpty(pageStr)) { return; } //-- pageStr = pageStr.Replace("\r\n", "");//替换换行符 // 获取html,body标签内容 string body = string.Empty; string bodyFilter = @"(?is)<body.*?</body>"; Match m = Regex.Match(pageStr, bodyFilter); if (m.Success) { body = m.ToString().Replace("<tr >", "<tr>").Replace("\r\n", ""); } // 过滤样式,脚本等不相干标签 foreach (var filter in Filters) { body = Regex.Replace(body, filter[0], filter[1]); } //-- if (!string.IsNullOrEmpty(mustKey) && !body.Contains(mustKey)) { return; } body = Regex.Replace(body, "\\s", ""); info.Url = url; string basicInfoRegexStr0 = "<h1title=([\\s\\S]+?)>(.*?)</h1>"; //职位名称 string position = Regex.Match(body, basicInfoRegexStr0).Value; info.Position = string.IsNullOrEmpty(position) ? "" : position.Substring(position.IndexOf(">") + 1, position.IndexOf("</") - position.IndexOf(">") - 1);//职位名称 string basicInfoRegexStr1 = "</h1><h3>(.*?)</h3>";//公司名称 string company = Regex.Match(body, basicInfoRegexStr1).Value; info.Company = string.IsNullOrEmpty(company) ? "" : company.Substring(company.IndexOf("<h3>") + 4, company.IndexOf("</h3>") - company.IndexOf("<h3>") - 4);//公司名称 string basicInfoRegexStr2 = "<divclass=\"resumeclearfix\"><span>(.*?)</span>";//工作地点 string address = Regex.Match(body, basicInfoRegexStr2).Value; info.Address = string.IsNullOrEmpty(address) ? "" : address.Substring(address.IndexOf("<span>") + 6, address.IndexOf("</") - address.IndexOf("<span>") - 6);//工作地点 string basicInfoRegexStr3 = "<li><span>企业性质:</span>(.*?)</li>";//公司性质 string nature = Regex.Match(body, basicInfoRegexStr3).Value; info.Nature = string.IsNullOrEmpty(nature) ? "" : nature.Substring(nature.IndexOf("</span>") + 7, nature.IndexOf("</li>") - nature.IndexOf("</span>") - 7);//公司性质 if (string.IsNullOrEmpty(info.Nature)) { string basicInfoRegexStr3_1 = "<br><span>性质:</span>(.*?)<br>"; string nature_1 = Regex.Match(body, basicInfoRegexStr3_1).Value; info.Nature = string.IsNullOrEmpty(nature_1) ? "" : nature_1.Substring(nature_1.IndexOf("</span>") + 7, nature_1.LastIndexOf("<br>") - nature_1.IndexOf("</span>") - 7);//公司性质 } string basicInfoRegexStr4 = "<li><span>企业规模:</span>(.*?)</li>";//公司规模 string scale = Regex.Match(body, basicInfoRegexStr4).Value; info.Scale = string.IsNullOrEmpty(scale) ? "" : scale.Substring(scale.IndexOf("</span>") + 7, scale.IndexOf("</li>") - scale.IndexOf("</span>") - 7);//公司规模 if (string.IsNullOrEmpty(info.Scale)) { string basicInfoRegexStr4_1 = "<br><span>规模:</span>(.*?)<br>"; string scale_1 = Regex.Match(body, basicInfoRegexStr4_1).Value; info.Scale = info.Nature = string.IsNullOrEmpty(scale_1) ? "" : scale_1.Substring(scale_1.IndexOf("</span>") + 7, scale_1.LastIndexOf("<br>") - scale_1.IndexOf("</span>") - 7);//公司规模 } string basicInfoRegexStr5 = "<spanclass=\"noborder\">(.*?)</span>";//工作经验 string experience = Regex.Match(body, basicInfoRegexStr5).Value; info.Experience = string.IsNullOrEmpty(experience) ? "" : experience.Substring(experience.IndexOf(">") + 1, experience.IndexOf("</") - experience.IndexOf(">") - 1);//工作经验 string basicInfoRegexStr6 = "</span><span>(.*?)</span><spanclass=\"noborder\">";//最低学历 string education = Regex.Match(body, basicInfoRegexStr6).Value; info.Education = string.IsNullOrEmpty(education) ? "" : education.Substring(education.IndexOf("<span>") + 6, education.IndexOf("</span><spanclass=") - education.IndexOf("<span>") - 6);//最低学历 string basicInfoRegexStr7 = "<pclass=\"job-main-title\">(.*?)<";//月薪 string salary = Regex.Match(body, basicInfoRegexStr7).Value; info.Salary = string.IsNullOrEmpty(salary) ? "" : salary.Substring(salary.IndexOf(">") + 1, salary.LastIndexOf("<") - salary.IndexOf(">") - 1);//月薪 string timeInfoRegexStr = "<pclass=\"release-time\">发布时间:<em>(.*?)</em></p>";//发布时间 string time = Regex.Match(body, timeInfoRegexStr).Value; info.Time = string.IsNullOrEmpty(time) ? "" : time.Substring(time.IndexOf("<em>") + 4, time.IndexOf("</em>") - time.IndexOf("<em>") - 4);//发布时间 if (GetJobEnd != null) { GetJobEnd(pageStr, info); } } catch (Exception exMsg) { throw new Exception(exMsg.Message); } } }
从以上代码可以看出都是在截取(正则表达式)相应内容,非常复杂,稍微一不注意就截取不到网站数据,写起来相当的费劲,最后通过QQ群(186841119)里的朋友的介绍采用了Fizzler来提取网站数据,一下子感觉就容易多了,下面着中来介绍一下Fizzler这个工具(好像这个是开源的),相关介绍可以去网站查询到。
首先提供这个工具的下载地址:Fizzler
这个里面包括三个文件:Fizzler.dll、Fizzler.systems.html" target="_blank">Systems.HtmlAgilityPack.dll、HtmlAgilityPack.dll三个文件,在VS2010里引用里直接进行引用就可以了。
完成以上即完成了对Fizzler的引用。
using HtmlAgilityPack; using Fizzler; using Fizzler.Systems.HtmlAgilityPack;
以上就可以在CS里进行了引用,
下面来进行代码的实现,
private static WebDownloader m_wd = new WebDownloader(); /// <summary> /// 获取HTML内容 /// </summary> /// <param name="Url">链接</param> /// <param name="Code">字符集</param> /// <returns></returns> public static string GetHtml(string Url, Encoding Code) { return m_wd.GetPageByHttpWebRequest(Url, Code); } public string GetPageByHttpWebRequest(string url, Encoding encoding) { Stream sr = null; StreamReader sReader = null; try { HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Method = "Get"; request.Timeout = 30000; HttpWebResponse response = request.GetResponse() as HttpWebResponse; if (response.ContentEncoding.ToLower() == "gzip")//如果使用了GZip则先解压 { sr = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress); } else { sr = response.GetResponseStream(); } sReader = new StreamReader(sr, encoding); return sReader.ReadToEnd(); } catch { return null; } finally { if (sReader != null) sReader.Close(); if (sr != null) sr.Close(); } }
以上即实现抓取HTML数据代码,,以上代码基本上也没啥区别,就是普通抓取数据的方法。
/// <summary> /// 获取相应的标签内容 /// </summary> /// <param name="Url">链接</param> /// <param name="CSSLoad">CSS路径</param> /// <param name="Code">字符集</param> /// <returns></returns> public static IEnumerable<HtmlNode> GetUrlInfo(string Url, string CSSLoad, Encoding Code) { HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument { OptionAddDebuggingAttributes = false, OptionAutoCloseOnEnd = true, OptionFixNestedTags = true, OptionReadEncoding = true }; htmlDoc.LoadHtml(GetHtml(Url, Code)); IEnumerable<HtmlNode> NodesMainContent = htmlDoc.DocumentNode.QuerySelectorAll(CSSLoad);//查询的路径 return NodesMainContent; } /// <summary> /// 获取相应的标签内容 /// </summary> /// <param name="html">html内容</param> /// <param name="CSSLoad">CSS路径</param> /// <returns></returns> public static IEnumerable<HtmlNode> GetHtmlInfo(string html, string CSSLoad) { HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument { OptionAddDebuggingAttributes = false, OptionAutoCloseOnEnd = true, OptionFixNestedTags = true, OptionReadEncoding = true }; htmlDoc.LoadHtml(html); IEnumerable<HtmlNode> NodesMainContent = htmlDoc.DocumentNode.QuerySelectorAll(CSSLoad);//查询的路径 return NodesMainContent; }
以上两个方法即实现对相应路径标签数据的抓取,一个方法是根据URL进行抓取,一个是根据HTML内容去抓取相应的数据,下面着重介绍CSSLoad的获取方法,这个需要安装火狐浏览器即可,火狐浏览器需要安装FireBug插件进行查询,如下图(网站工具栏):

再点击像蜘蛛一样的图标,这样可以看到如下:
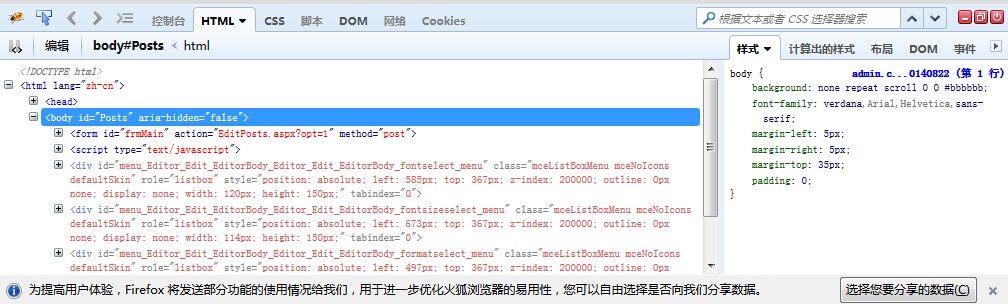
这样可以看到所有的HTML标签,那么紧接着如何去获取CSS路径呢,那相对来说就非常简单了。

点击蓝色的箭头选取网站相关的内容,

这样相应的HTML同样选中了,这样离我们拿到CCS路径更近一步了,紧接着点击右键即可复制CCS路径即可。如下:

点击复制CSS路径就可以了,复制出CSS路径如下:
html body#Posts form#frmMain table#BodyTable tbody tr td#Body div#Main div#Editor_Edit div#Editor_Edit_Contents div#edit_container div#Editor_Edit_APOptions div#Editor_Edit_APOptions_Contents.Edit div.edit_option div#Editor_Edit_APOptions_Advancedpanel1 div#Editor_Edit_APOptions_Advancedpanel1_Header.subCollapsibleTitle
看到这一串路径别急,我们也不需要把这串路径全部复制到我们程序里,否则这样显得太负责了,我们只需要将最后的部分节点放到上面的方法里面,我们就能读取到HTML标签相应的内容,下面举一个简单例子就进行说明。
1 /// <summary> 2 /// 解析每一条招聘信息 3 /// </summary> 4 /// <param name="Url"></param> 5 private void GetJobInfoFromUrl(object Url) 6 { 7 try 8 { 9 JobInfo info = new JobInfo(); 10 info.Url = Url.ToString(); 11 //--获取HTML内容 12 string html =AnalyzeHTML.GetHtml(Url.ToString(), Encoding.UTF8); 13 if (string.IsNullOrEmpty(html)) { return; } 14 //--职位名称 15 IEnumerable<HtmlNode> NodesMainContent1 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h1"); 16 if(NodesMainContent1.Count()>0) 17 { 18 info.Position = NodesMainContent1.ToArray()[0].InnerText; 19 } 20 //--公司名称 21 IEnumerable<HtmlNode> NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3"); 22 if (NodesMainContent2.Count() > 0) 23 { 24 info.Company = NodesMainContent2.ToArray()[0].InnerText; 25 } 26 //--公司性质/公司规模 27 IEnumerable<HtmlNode> NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li"); 28 if (NodesMainContent4.Count() > 0) 29 { 30 foreach (var item in NodesMainContent4) 31 { 32 if (item.InnerHtml.Contains("企业性质")) 33 { 34 string nature = item.InnerText; 35 nature = nature.Replace("企业性质:", ""); 36 info.Nature = nature; 37 } 38 if (item.InnerHtml.Contains("企业规模")) 39 { 40 string scale = item.InnerText; 41 scale = scale.Replace("企业规模:", ""); 42 info.Scale = scale; 43 } 44 } 45 } 46 else//第二次解析企业性质和企业规模 47 { 48 IEnumerable<HtmlNode> NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word"); 49 if (NodesMainContent4_1.Count() > 0) 50 { 51 foreach (var item_1 in NodesMainContent4_1) 52 { 53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries); 54 if (arr != null && arr.Length > 0) 55 { 56 foreach (string str in arr) 57 { 58 if (str.Trim().Contains("性质")) 59 { 60 info.Nature = str.Replace("性质:", "").Trim(); 61 } 62 if (str.Trim().Contains("规模")) 63 { 64 info.Scale = str.Replace("规模:", "").Trim(); 65 } 66 } 67 } 68 } 69 } 70 } 71 //--工作经验 72 IEnumerable<HtmlNode> NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder"); 73 if (NodesMainContent5.Count() > 0) 74 { 75 info.Experience = NodesMainContent5.ToArray()[0].InnerText; 76 } 77 //--公司地址/最低学历 78 IEnumerable<HtmlNode> NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix"); 79 if (NodesMainContent6.Count() > 0) 80 { 81 foreach (var item in NodesMainContent6) 82 { 83 string lable = Regex.Replace(item.InnerHtml, "\\s", ""); 84 lable = lable.Replace("<span>", ""); 85 string[] arr = lable.Split("</span>".ToCharArray(), StringSplitOptions.RemoveEmptyEntries); 86 if (arr != null && arr.Length > 2) 87 { 88 info.Address = arr[0];//公司地址 89 info.Education = arr[1];//最低学历 90 } 91 } 92 } 93 //--月薪 94 IEnumerable<HtmlNode> NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title"); 95 if (NodesMainContent7.Count() > 0) 96 { 97 info.Salary = NodesMainContent7.ToArray()[0].InnerText; 98 } 99 //--发布时间 100 IEnumerable<HtmlNode> NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em"); 101 if (NodesMainContent8.Count() > 0) 102 { 103 info.Time = NodesMainContent8.ToArray()[0].InnerText; 104 } 105 //-- 106 if (GetJobEnd != null) 107 { 108 GetJobEnd("", info); 109 } 110 } 111 catch (Exception exMsg) 112 { 113 throw new Exception(exMsg.Message); 114 } 115 }
以上这个方法也是解析某招聘网站标签的内容,但已经看不到复杂的正则表达式去截取HTML标签了,这样显得代码更加干练、简单,再整一个配置页面既可应付抓取网站标签经常变化的难题,这样就显得抓取别人网站数据就是一件非常简单的事情了,O(∩_∩)O哈哈~是不是啦!!!
以上只代表个人观点!!!